Kafka消费者在重启后无法读取消息。我正在使用weiboad / kafka-php。
 社区干货
社区干货
Kafka@记一次修复Kafka分区所在broker宕机故障引发当前分区不可用思考过程 | 社区征文
写在前面的话,业务组内研发童鞋碰到了这样一个问题,反复尝试并研究,包括不限于改Kafka,主题创建删除,Zookeeper配置信息重启服务等等,于是我们来一起看看... Ok,Now,我们还是先来一步步分析它并解决它,依然以”... 但Kafka的高可用性HA我们是耳熟能详的,为啥我们搭建的Kafka集群由多个节点组成,但其中某个节点宕掉,整个分区就不能正常使用-消费者端无法订阅到消息。 首先,我们来看下Kafka的配置信息:```js[root@xx-xx-xx...
字节跳动新一代云原生消息队列实践
消费者协调的资源可以完全隔离,不会互相影响。另外 Coordinator 可以独立扩缩容,以应对不同集群的情况。* Controller 承担组件心跳管理、负载均衡、故障检测及控制命令接入的工作。因为 BMQ 将数据放在分布式存储系统上,因此无需管理数据副本,相较于 Kafka 省去了 ISR 相关的管理。Controller 可以更加专注地关注集群整体流量均衡及故障检测。在 BMQ 中用户所有请求都会由 Proxy 接入,因此 BMQ 的 Metadata 中的 ‘Broker’...
Kafka数据同步
Kafka MirrorMaker 是 Kafka 官网提供的跨数据中心流数据同步方案,其实现原理是通过从 Source 集群消费消息,然后将消息生产到 Target 集群从而完成数据迁移操作。用户只需要通过简单的consumer配置和producer配置,启动MirrorMaker,即可实现实时数据同步。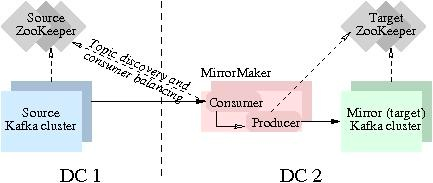本实验主要聚焦跑通Kafka MirrorMaker (MM1)数据迁移流...
字节跳动基于Apache Atlas的近实时消息同步能力优化 | 社区征文
文 | **洪剑**、**大滨** 来自字节跳动数据平台开发套件团队# 背景## 动机字节数据中台DataLeap的Data Catalog系统基于Apache Atlas搭建,其中Atlas通过Kafka获取外部系统的元数据变更消息。在开源版本中,每台... 我们不确认客户环境一定有Flink集群,即使部署的数据底座中带有Flink,后续的维护也是个头疼的问题。另外一个角度,作为通用流式处理框架,Flink的大部分功能我们并没有用到,对于单条消息的流转路径,其实只是简单的读取...
 特惠活动
特惠活动
 Kafka消费者在重启后无法读取消息。我正在使用weiboad / kafka-php。-优选内容
Kafka消费者在重启后无法读取消息。我正在使用weiboad / kafka-php。-优选内容
 Kafka消费者在重启后无法读取消息。我正在使用weiboad / kafka-php。-相关内容
Kafka消费者在重启后无法读取消息。我正在使用weiboad / kafka-php。-相关内容
高阶使用
本文将为您介绍火山引擎 E-MapReduce(EMR)kafka 组件相关的高阶使用,方便您更深入的使用 Kafka。 扩容 您可以在 EMR 控制台的集群管理页面,进行 Kafka 集群的扩容操作。开源 Kafka 扩容新的 broker 后,流量不会自动... Kafka 集群在创建时如果给 Broker 所在的 Core 节点组绑定了公网 IP,会自动配置 Kafka Broker 的 advertised.listeners 等参数,使 Kafka Broker 可以通过公网 IP(端口号:19092)和内网地址(端口号:9092)访问。在 ...
实例管理
消息队列 Kafka版提供以下实例管理相关的常见问题供您参考。 FAQ 列表如何选择计算规格和存储规格 如何选择云盘 如何删除或退订实例 是否支持压缩消息? 是否支持多可用区部署 Kafka 实例? 单 AZ 实例如何切换为多 ... 消息队列 Kafka版支持变更实例的计算规格、存储规格和分区数量。其中,各项变更対实例的影响如下: 变更计算规格时,服务端节点会依次滚动重启,可能造成客户端与部分节点连接闪断。升级计算规格可能会触发 Topic 分区...
快速开始
本文介绍如何在火山引擎 E-MapReduce(EMR)上,快速开始您的 Kafka 探索之旅。请参考下面的步骤,在 EMR 引擎中创建一个 Kafka 的集群类型,并开始尝试 Kafka 的各项功能吧。 1 创建一个 Kafka 集群您可以方便地在 EMR... 如果在创建集群的过程中给 Master/Core 节点绑定了公网 IP,系统会自动把相关的公网 IP 配置信息写入到 Kafka Broker 的 advertised.listeners 服务参数中。这时 Kafka Broker 可以通过公网 IP(端口号:19092)和内网...
创建实例
应用接入消息队列 Kafka版之前,需要在控制台创建 Kafka 实例。消息队列 Kafka版提供多种实例规格,对应不同的计算能力和存储空间,您可以根据实际业务需求选择不同的实例规格。本文介绍创建 Kafka 实例的操作步骤。 ... 超出消费位点保留时长后会自动删除该消费者组。 关闭后,消费进度的自动删除不影响消费组的状态,Empty 状态的 Group 不会被自动删除。 说明 修改该参数配置将引发实例滚动重启,可能会出现服务的短暂不可用。建议您在...
修改参数配置
创建 Kafka 实例后,您可以根据业务需求修改实例或 Topic 级别的参数配置,例如最大消息大小、消息保留时长等。 背景信息消息队列 Kafka版在实例与 Topic 级别均提供了部分参数的在线可视化配置,指定不同场景下的各种... 在实例级别修改最大消息大小和消息保留时长对此 Topic 不生效。 修改实例的消费位点保留时长将引发实例滚动重启,请确认业务侧已配置了自动重连等策略。 修改最大消息大小(MessageMaxByte)之前,请确认新的消息大小和...
字节跳动新一代云原生消息队列实践
消费者协调的资源可以完全隔离,不会互相影响。另外 Coordinator 可以独立扩缩容,以应对不同集群的情况。* Controller 承担组件心跳管理、负载均衡、故障检测及控制命令接入的工作。因为 BMQ 将数据放在分布式存储系统上,因此无需管理数据副本,相较于 Kafka 省去了 ISR 相关的管理。Controller 可以更加专注地关注集群整体流量均衡及故障检测。在 BMQ 中用户所有请求都会由 Proxy 接入,因此 BMQ 的 Metadata 中的 ‘Broker’...
Kafka数据同步
Kafka MirrorMaker 是 Kafka 官网提供的跨数据中心流数据同步方案,其实现原理是通过从 Source 集群消费消息,然后将消息生产到 Target 集群从而完成数据迁移操作。用户只需要通过简单的consumer配置和producer配置,启动MirrorMaker,即可实现实时数据同步。本实验主要聚焦跑通Kafka MirrorMaker (MM1)数据迁移流...
HaKafka
HaKafka 是一种特殊的表引擎,修改自社区 Kafka 引擎。使用 Kafka / HaKafka 引擎可以订阅 Kafka 上的 topic,拉取并解析 topic 中的消息,然后通过 MaterializedView 将 Kafka/HaKafka 解析到的数据写入到目标表(一般... 每个消费者会创建一个线程。一般建议设置为 1 - 4,每个线程大约 20MB/s 的写入性能。 kafka_max_block_size UInt64 65536 写入block_size默认 65536 MB kafka_leader_priority String '0' 会存储到zk上,互...
新功能发布记录
本文介绍了消息队列 Kafka版各特性版本的功能发布动态和文档变更动态。 2024年3月功能名称 功能描述 发布地域 相关文档 Topic 支持标签 支持为 Topic 添加标签,您可以将 Topic 通过标签进行归类,有利于识别和... 2023-07-04 全部地域 创建 Topic 修改分区副本数 创建 Topic 后,可以通过修改 Topic 配置的方式调整分区副本数。 2023-07-04 全部地域 修改 Topic 配置 重启实例 支持重启一个正常运行中的 Kafka 实例。...
