创建3个分类模型,根据其他可用的列预测类别。
 社区干货
社区干货
干货|火山引擎技术工具分享:用AI完成数据挖掘,零门槛完成SQL撰写
画布中支持同时构建多组画布流程,一图实现多数据建模任务的构建,提高数据建设的效率,降低任务管理成本;另外,画布中集成封装了超过40种数据清洗、特征工程算子,覆盖初阶到高阶的数据生产能力,无需Coding完成复杂的数... 此时可通过可视化建模构建数据挖掘流程:1. 拖入样本数据和全部数据作为数据输入2. 拖入分类算法,如XGB算法用于模型训练3. 拖入预测算子,搭建模型与全部数据的关系进行预测4. 实际数据和预测结果结合输出数据...
我的技术年终总结——机器学习 |社区征文
**建立模型**:设计计算机可以自动“学习”的算法- **训练**:用数据训练算法模型(算法从数据中分析规律)- **预测**:利用训练后的算法完成任务(根据学习的规律为未知数据进行分类和预测) 通过周志华老... 回归是一种数学模型,利用数据统计原理,对大量统计数据进行数学处理,确定因变量与某些自变量的相关关系,建立一个相关性较好的回归方程(函数表达式)。分类就是对数据分进行分类,把它们分到已知的每一个类别。- ...
NL2SQL:智能对话在打通人与数据查询壁垒上的探索 | 社区征文
通过配合相关规则及其他语义模型,能够对一些简单常见的用户问题转换成相应的SQL。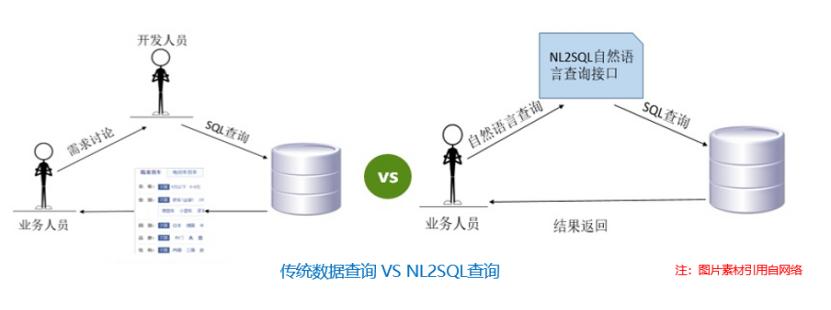... 目前学术界的预测准确率可达91.8%。Spider:Spider数据集是耶鲁大学于2018年新提出的一个较大规模的nl2sql数据集。该数据集包含了10,181条自然语言问句,分布在200个独立数据库中的5,693条SQL,内容覆盖了138个不同...
干货|8000字长文,深度介绍Flink在字节跳动数据流的实践
=&rk3s=8031ce6d&x-expires=1716135656&x-signature=67Gp61HEVcFY0Gly%2B9bGZKoMZmM%3D) **1、UserAction ETL场景**在UserAction ETL场景中,我们遇到的核心需求是:**种类繁多且流量巨大的客户端埋... 而推荐模型的迭代、产品埋点的变动都可能导致UserAction的ETL规则的变动。如果ETL规则硬编码在代码中,每次修改都需要升级代码并重启Flink Job,会影响数据流稳定性和数据的时效性。因此,这个场景的 **另一个需求就...
 特惠活动
特惠活动
 创建3个分类模型,根据其他可用的列预测类别。-优选内容
创建3个分类模型,根据其他可用的列预测类别。-优选内容
 创建3个分类模型,根据其他可用的列预测类别。-相关内容
创建3个分类模型,根据其他可用的列预测类别。-相关内容
创建模型
在页面右上角的业务线下拉列表中,选择要管理的业务线。 选择指标管理 > 模型管理,进入模型管理页面。 单击新建模型按钮,进入创建模型页面。 设置模型信息,单击确定按钮,完成模型创建。新建模型相关参数说明如下表所示。其中名称前带 * 的参数为必填参数,名称前未带 * 的参数为可选参数。 参数 说明 *数据源类型 需要导入的数据源表类型。支持 Cloud-MySQL、VEDB-MySQL、Doris、ByteHouse云数仓版、LAS-Hive 五种类型,下拉...
NL2SQL:智能对话在打通人与数据查询壁垒上的探索 | 社区征文
通过配合相关规则及其他语义模型,能够对一些简单常见的用户问题转换成相应的SQL。... 目前学术界的预测准确率可达91.8%。Spider:Spider数据集是耶鲁大学于2018年新提出的一个较大规模的nl2sql数据集。该数据集包含了10,181条自然语言问句,分布在200个独立数据库中的5,693条SQL,内容覆盖了138个不同...
干货|8000字长文,深度介绍Flink在字节跳动数据流的实践
=&rk3s=8031ce6d&x-expires=1716135656&x-signature=67Gp61HEVcFY0Gly%2B9bGZKoMZmM%3D) **1、UserAction ETL场景**在UserAction ETL场景中,我们遇到的核心需求是:**种类繁多且流量巨大的客户端埋... 而推荐模型的迭代、产品埋点的变动都可能导致UserAction的ETL规则的变动。如果ETL规则硬编码在代码中,每次修改都需要升级代码并重启Flink Job,会影响数据流稳定性和数据的时效性。因此,这个场景的 **另一个需求就...
万字长文带你弄透Transformer原理|社区征文
VIT模型真是屠戮各项榜单啊,就像是15年的resnet,不管是物体分类,目标检测还是语义分割的榜单前几名基本都是用VIT实现的!!!朋友,相信你点进来了也是了解了VIT的强大,想一睹VIT的风采。🌼🌼🌼正如我的标题所说,作为一... **【注:执行步骤部分的图都为自己所画,一方面希望能用自己的思路表述清楚这部分,另一方面也想在锻炼一下自己的作图水平,作图不易,恳请大家点赞支持,转载请附链接。代码演示部分参考[这篇文章](https://towardsdata...
聚类模型
将人群包输出拆分为不同类别的子人群包,以满足某些业务场景下,按特征拆分不同属性用户人群的需求 2. 功能场景 聚类模型( K-means算法)可以根据特征快速拆分已有人群,场景举例: 目标需求:希望在近3个月注册的用户中... 3.3 人群包权限使用者需要至少拥有一个将要使用的人群包权限,可以自建或由其他人群包创建者授权 3.4 模型可用次数聚类模型提供100次免费使用,剩余次数将直观显示在模型列表页。 4. 操作步骤 4.1 新建预测任务进入模...
使用pytorch自己构建网络模型总结|社区征文
也可以自己来构建一些模型来进行训练。如果你也发现自己只知道在Git上克隆别人的代码,但是自己对程序的结构不了解,那么下面的内容可能会帮到你!!! 这部分内容主要是根据[B站视频](https://www.bilibili... 判断它是猫是狗或是其他的类型【当然这个数据集只有10种类型,如上图所示的10种】) 下面我们就来一步步的介绍!!!【代码我分流程分部分介绍,完整代码放在文末自取】 # 完整网络模型训练步骤## ...
一文读懂火山引擎云数据库产品及选型
又可以分化出不同的产品类型。根据 DB-Engines 的统计,数据库产品数量已经有将近 400 种,数据库厂商也有几百家,如下图所示,不同数据库产品的实际应用规模也大有不同,其中关系型数据库管理系统是所有数据库中使用最广泛的一类。同时,根据卡内基梅隆大学维护的全球数据库信息库(dbdb.io)显示,数据库系统种类已经多达 870 种,可谓是欣欣向荣,让人眼花缭乱。、连字符(-)。 长度不超过 32 个字符。特殊字符不能用在开头和结尾,也不能连续使用。 框架 N/A 选择模型的类别或框架。可选项: 推...
业务进阶,用架构思维看云原生 | 社区征文
是一种计算资源交付模型。** 其中集成了各种服务器、应用程序、数据和其它资源,并通过 Internet 以服务的形式提供这些资源,且通常对资源进行了虚拟化。## 一、**从虚拟化到云原生****虚拟化作为云计算中最基础的关键技术,其本质是利用一种逻辑将另一种逻辑进行抽象出来。** 也就是用某种技...
