数据库模型图导入
 社区干货
社区干货
VikingDB:大规模云原生向量数据库的前沿实践与应用
而向量数据库又是以 embedding 作为核心概念,并围绕其提供存储检索能力的基础软件,因此可以说 **向量数据库是 AI 原生应用程序的基础设施** 。为了更好地胜任 AI 基础设施的角色和贴合大模型的生态,VikingDB 集成了常用的 embedding 模型,用户可以方便地导入、检索文本等非结构化数据,之后 VikingDB 再自动将其转换为向量并存储,最终提供检索能力。除了近似向量检索,VikingDB 还提供聚类查询、基于向量的相关性排序和多样...
未来向量数据库的崛起与多元化场景创新 主赛道 | 社区征文
随着大模型的兴起,向量数据库越来越成为开发者关注的重点。## 一、概述:随着人工智能时代的来临,我们要更有效的解决图象、语音和视频等各种非结构化数据。这种信息往往有复杂的关系...
分布式数据库TiDB的设计和架构
[picture.image](https://p6-volc-community-sign.byteimg.com/tos-cn-i-tlddhu82om/125153dda2484d44bd7a1cba22f0c5e1~tplv-tlddhu82om-image.image?=&rk3s=8031ce6d&x-expires=1715012438&x-signature=C5J1sDZIRAg3GnPaDoXuUO12fUA%3D)第十二期技术夜校分享嘉宾是DBA大咖——Xiaoyu他拥有10年+互联网数据库运维经验、在游戏、电商、OTA行业从事过DBA运维工作、在大规模数据库自动化、平台化方面有较资深的落地经验。# 导...
[数据库系统] 业界列式存储浅析
# 简介众所周知,在数据库存储引擎侧通常有两类存储模型,行式存储NSM(N-ary Storage Model)和列式存储DSM(Decomposition Storage Model),两种存储模型各有其特定的擅长场景。在以前,主流存储设备是机械磁盘的情况... 数据排列结构如下图所示: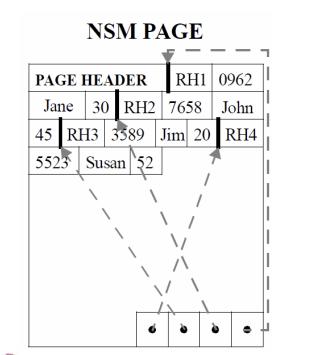列存和行存的区别主要是在存储时将多行数据的相同colum...
 特惠活动
特惠活动
 数据库模型图导入-优选内容
数据库模型图导入-优选内容
 数据库模型图导入-相关内容
数据库模型图导入-相关内容
MongoDB文档数据库创建及简单的CRUD
前言 MongoDB 本质上还是一个文档数据库,具有很强的横向扩展能力,以及灵活模型,特别适合迭代开发,数据模型多变场景。在本教程中,您将学习如何创建 MongoDB,并使用客户端连接,生产数据并进行查询。 关于实验 预计部... 3.3 在MongoDB中创建表并插入数据python test_db = client[ lxb ]test_coll = test_db[ test_table ]result = test_coll.insert_one({ string : Hello Bytedance })print(result)3.4 检索表中的数据python re...
基于云数据库 PostgreSQL 版构建智能交互式问答系统
本文就如何利用云数据库 PostgreSQL 版和大语言模型技术(Large Language Model,简称 LLM),实现企业级智能交互式问答系统进行介绍。通过本文,您将学习了解到:交互式问答系统原理、PostgreSQL 向量化存储和检索技术,... 生成文档 embedding 向量并插入数据库。 shell pnpm tsx script/generate-embeddings.ts 运行过程如下图所示: 脚本运行后,我们查看下所构建的知识库,查询 docs 表: 查询 docs_chunk 表,批量导入向量成功: 2. 问答阶...
[数据库系统] 业界列式存储浅析
# 简介众所周知,在数据库存储引擎侧通常有两类存储模型,行式存储NSM(N-ary Storage Model)和列式存储DSM(Decomposition Storage Model),两种存储模型各有其特定的擅长场景。在以前,主流存储设备是机械磁盘的情况... 数据排列结构如下图所示:列存和行存的区别主要是在存储时将多行数据的相同colum...
管理数据库
已经成功创建集群的前提下,可登录数据库管理页面,执行数据库相关操作。本文介绍数据库相关操作的操作场景、操作影响和操作步骤。 编辑数据库若导入数据库时填写的配置信息有误或配置发生变化,可重新编辑,数据库相关所有配置均支持编辑。 注意 若需要批量修改协议端口,请确保所选数据库的操作系统一致。 登录 云堡垒机控制台,在左侧导航栏选择 云堡垒机。 单击目标云堡垒机实例名称,在云堡垒机管理页面的左侧导航栏选择 资源管理...
创建数据导入任务
本文介绍如何在数据库工作台 DBW 控制台导入云数据库 MySQL 版的数据。 前提条件已注册火山引擎账号并完成实名认证。详细操作,请参见如何进行账号注册和实名认证。 已创建云数据库 MySQL 版实例和账号。详细操作,... 当前支持以下选项: INSERT INTO:数据会按照 insert into 的方式插入。在遇到数据冲突时,将报错并停止插入。 REPLACE_INTO:在表中已经存在相同的记录时,则覆盖已有数据。 字符集 在下拉列表中选择目标字符集,当前...
达梦@记一次国产数据库适配思考过程|社区征文
若是通过**Mysql或Oracle或其他数据库,文件等方式迁移导入**。这里记录一下迁移过程中遇到的问题,**在迁移的时候,报某些字段超长**。于是,查看了MySql中那些字段的类型及长度,都是varchar(50) 。这里应该是迁移有些... 则执行图一中批量插入insertBatch方法;ii、当获取到的数据源信息为db2,则会执行图二中批量插入insertBatch方法;iii、当获取到的数据源信息为oracle,则会执行图三批量插入insertBatch方法。上例,这样我们就能...
创建数据导入任务
本文介绍如何在数据库工作台 DBW 控制台导入云数据库 veDB MySQL 版的数据。 前提条件已注册火山引擎账号并完成实名认证。详细操作,请参见如何进行账号注册和实名认证。 已创建云数据库 veDB MySQL 版实例和账号。... 当前支持以下选项: INSERT INTO:数据会按照 insert into 的方式插入。在遇到数据冲突时,将报错并停止插入。 REPLACE_INTO:在表中已经存在相同的记录时,则覆盖已有数据。 字符集 在下拉列表中选择目标字符集,当前...
Broker Load
并且会在对数据进行预处理之后将数据导入到 StarRocks 中。所有 BE 均完成导入后,由 FE 最终判断导入作业是否成功。您需要通过 SHOW LOAD 语句或者 curl 命令来查看导入作业的结果。支持CSV、ORCFile和Parquet等文... 指定目标表所在的数据库。 label_name 指定导入作业的标签。每个导入作业都对应唯一的一个标签。通过标签,可以查看导入作业的执行情况。导入作业的状态为 FINISHED 时,其标签不可再复用给其他导入作业。导入作业的...
产品更新公告
更新类型 功能描述 产品截图说明 新功能 向量数据库新增向量化模型(多功能版)和 pipeline,支持 8k tokens 窗口长度和多语言、跨语言检索功能。 向量数据库提供混合检索能力,在使用稠密向量进行语义检索的同时,可使用语言模型抽取稀疏向量进行关键词匹配检索。 知识库提供混合检索能力,兼顾语义检索和关键词检索。 优化 向量数据库支持在创建 collection 的可视化界面中绑定 pipeline。 优化 知识库支持导入pdf扫描件及...
