数据库模型是er图
 社区干货
社区干货
[数据库系统] 业界列式存储浅析
以便query能选择最优的projections进行查询;1. 使用不同的coding算法重度压缩列;1. 构建基于列存的优化器和执行器;1. 使用有重叠的projections 来提升性能和获取高可用;1. 使用snapshot isolation,避免2PC 和 query时加锁;### 数据模型C-Store 支持标准的关系型数据模型,一个数据库包含多张表,每张表包含多个attribute(column)。数据在C-Store里面不是根据逻辑数据类型进行物理存储的。反之大多数rowstore是直接存储...
未来向量数据库的崛起与多元化场景创新 主赛道 | 社区征文
可用作图像鉴别、检索等任务;**文本向量**:通过词嵌入技术如 Word2Vec、BERT 等生成的文本特征向量,这些向量包含了文本的语义信息,可以用于文本分类、情感分析等任务;**语音向量**:通过声学模型从声音信号中提取的特征向量,这些向量捕捉了声音的重要特性,如音调、节奏、音色等,可以用于语音识别、声纹识别等任务。## 二、向量数据库的优势?向量数据库与传统的关系型数据库有很大提升。传统的关系型数据库是基于表格的数据...
字节跳动自研万亿级图数据库 & 图计算实践
图数据的分析和计算需求也逐渐显现。在这篇文章中,将从 ByteGraph 的适用场景、内部架构、关键问题分析几个方面作深入介绍,并将介绍图计算相关实践。 自研图数据库(ByteGraph)介绍 从数据模型角度看,图数据库内部数据是有向属性图,其 **基本元素是 Graph 中的点(Vertex)、边(Edge)以及其上附着的属性** ;作为一个工具,图数据对外提供的接口都是围绕这些元素展开。**图数据库本质也是一...
一文读懂火山引擎云数据库产品及选型
其理论基础是基于 IBM 研究员 E.F.Codd 博士在 1970 年提出的“关系模型(Relational model)”。关系型数据库也是过去几十年里各行各业使用最多最广泛的数据库类型。随着 2000 年之后移动互联网的大规模爆发,催生出了丰富多彩的面向互联网的应用,这些应用共同的特点是并发量非常高,数据量特别大。基于这些互联网的新场景与新需求,又出现了 NoSQL 数据库技术,其理论基础主要是由 Eric Brewer 提出的 CAP 定理以及 Dan Pritchett ...
 特惠活动
特惠活动
 数据库模型是er图-优选内容
数据库模型是er图-优选内容
 数据库模型是er图-相关内容
数据库模型是er图-相关内容
分布式数据库TiDB的设计和架构
第十二期技术夜校分享嘉宾是DBA大咖——Xiaoyu他拥有10年+互联网数据库运维经验、在游戏、电商、OTA行业从事过DBA运维工作、在大规模数据库自动化、平台化方面有较资深的落地经验。# 导语市场上有很多数据库产品,如Oracle、MySQL、SQLServer、NoSQL、NewSQL等,那么目前数据库圈最火的分布式关系型数据库之一TiDB你了解吗?相信很多同学以前听说过TiDB,也知道是一款国人研发的数据库,但你知道TiDB到底是如何实现的?它跟其他数...
VikingDB:大规模云原生向量数据库的前沿实践与应用
RAG(Retrival-Augmented Generation) 成为了当前业界最流行的解决方案。RAG 结合检索和生成两个关键组件,通过检索为大模型提供相关数据作为上下文信息。由于向量数据库能够高效存储和检索模型生成的向量,从而提供语义上更具有相关性的检索结果,因此向量数据库成了 ES 之外的 RAG 必不可少的检索工具,RAG 也成为了向量数据库最为重要的应用场景。简而言之, **向量库数据库对大模型的价值就是能够提供更准确的语义相关的数据作为上...
分布式数据库在抖音春晚活动中的应用
数据库的计算引擎是用来处理计算逻辑和事务逻辑的,一些核心的模块包括:- 接入层- Query Engine- Buffer Pool- 日志子系统- 事务子系统- 锁子系统可以这么说,缺了上述任意一个模块都很难构建出一个具有完备 ACID 特性的关系型数据库。了解关键子模块后,我们来看看计算层的数据模型。对于用户或者后端应用开发者来说,数据库可能是用户、数据库和数据表的一个集合;但是对于数据库开发者来说,数据库本质是内存...
一文读懂火山引擎云数据库产品及选型
其理论基础是基于IBM 研究员 E.F.Codd 博士在1970年提出的“关系模型(Relational model)”。关系型数据库也是过去几十年里各行各业使用最多最广泛的数据库类型。随着2000年之后移动互联网的大规模爆发,催生出了丰富多彩的面向互联网的应用,这些应用共同的特点是并发量非常高,数据量特别大。基于这些互联网的新场景与新需求,又出现了NoSQL数据库技术,其理论基础主要是由Eric Brewer提出的CAP定理以及Dan Pritchett提出的BASE原则...
[数据库论文研读] HTAP行列混存 & 智能转换
称为HTAP数据库罢了。这么做的话数据仍然要存两份(row & column),管控面的麻烦从外部转移到内部而已,并没有什么实际的架构创新。**所以,本论文提出了一种新的想法,**不再“分而治之”,而是要构建一个统一的存储层**,使用统一的data layout来管理表数据,这种layout里的“热数据”会针对OLTP特点优化存储结构,而“冷数据”会针对OLAP特点优化存储结构,然后根据时间推移或者query pattern的变化来自动迁移数据的存储结构。# Dat...
一文读懂火山引擎云数据库产品及选型
其理论基础是基于 IBM 研究员 E.F.Codd 博士在 1970 年提出的“关系模型(Relational model)”。关系型数据库也是过去几十年里各行各业使用最多最广泛的数据库类型。随着 2000 年之后移动互联网的大规模爆发,催生出了丰富多彩的面向互联网的应用,这些应用共同的特点是并发量非常高,数据量特别大。基于这些互联网的新场景与新需求,又出现了 NoSQL 数据库技术,其理论基础主要是由 Eric Brewer 提出的 CAP 定理以及 Dan Pritchett...
火山引擎ByteHouse:分析型数据库如何设计列式存储
分析型数据库中的列式存储,是一种数据库的物理存储结构,它是根据数据的列而不是行来存储数据的。列式存储的主要优势在于它能够提高数据分析和查询的性能,尤其是在处理大规模数据集时。以下是列式存储的一些主要特... **灵活的数据模型**: 列式存储通常支持多种数据模型,如行存储、列存储和键-值存储,这使得它能够适应不同的数据处理需求。# ByteHouse 的列式存储设计ByteHouse 是一款云原生数据仓库,为用户提供极速分析体验...
抖音大规模实践,火山引擎向量数据库是这样炼成的
AI时代,如何用好大模型是当前各行各业瞩目的焦点。向量数据库作为大模型“记忆体”,不仅能够为其提供数据存储,而且能通过数据检索、分析让大模型进行知识增强,成为生成式AI应用开发新范式的重要组成部分。用图片搜索图片或者文本搜索文本时,在数据库中存储和对比的并不是图片和视频片段,而是通过深度学习等算法将其提取出来的“特征”,“特征”提取的过程称为 Embedding,提取出的“特征”用数学中的向量来表示。向量化的目的是...
NL2SQL:智能对话在打通人与数据查询壁垒上的探索 | 社区征文
通过配合相关规则及其他语义模型,能够对一些简单常见的用户问题转换成相应的SQL。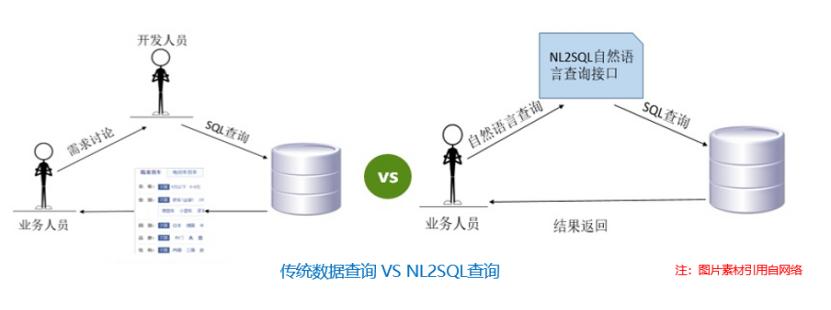... Spider:Spider数据集是耶鲁大学于2018年新提出的一个较大规模的nl2sql数据集。该数据集包含了10,181条自然语言问句,分布在200个独立数据库中的5,693条SQL,内容覆盖了138个不同的领域。虽然在数据数量上不如WikiSQL...
