图书馆建数据库er图
 社区干货
社区干货
2022技术盘点之平台云原生架构演进之道|社区征文
数据库有MongoDB分片集群/MySQL/Redis/ElasticSearch/RabbitMQ进行各类业务数据计算和存储## 三 流量管控... 镜像管理:构建出来的镜像使用镜像仓库Harbor进行管理- 容器编排:在CD过程中,利用kubectl set image进行容器编排部署,自建Kubernetes集群进行业务容器编排管理介绍 从数据模型角度看,图数据库内部数据是有向属性图,其 **基本元素是 Graph 中的点(Vertex)、边(Edge)以及其上附着的属性... Linkedln 在 KV 之上构建了 Social Graph 服务;微博是基于 Redis 构建了粉丝和关注关系。字节跳动的 Graph 在线存储场景, 其需求也是有自身特点的,可以总结为:* **海量数据存储**:百亿点、万亿边的数据规模;...
干货|以 100GB SSB 性能测试为例,通过 ByteHouse 云数仓开启你的数据分析之路
**/ 步骤三:创建数据库表 /** 在控制台页面中创建名为 ssb\_100 的数据库。  创建完毕后,进入到 SQL 工作表模块,通过如下建表语句建立四个数据表(事实表),并保...
数据库顶会 VLDB 2023 论文解读:Krypton: 字节跳动实时服务分析 SQL 引擎设计
读的时候多个版本的数据会按照不同的 Merge 算法合并为一份。Tablet 的 Commit Version 为该 Tablet 下 Rowset 的最大版本号,比如上图中 Tablet 2 的 Commit Version 为 Rowset 5 的版本号 21。每个 Query 都会带... 这篇文章我们完整的展示了一个 HSAP 系统的建设历程。欢迎感兴趣的朋友们与我们联系交流。 作者信息**陈恒**,字节跳动实时引擎团队负责人。数据库领域专家 & ...
 特惠活动
特惠活动
 图书馆建数据库er图-优选内容
图书馆建数据库er图-优选内容
 图书馆建数据库er图-相关内容
图书馆建数据库er图-相关内容
抖音大规模实践,火山引擎向量数据库是这样炼成的
=&rk3s=8031ce6d&x-expires=1715098861&x-signature=ER9zklN0PnOwxkgbPbCfwEsK3%2B4%3D)AI 时代,如何用好大模型是当前各行各业瞩目的焦点。向量数据库作为大模型“记忆体”,不仅能够为其提供数据存储,而且能通过... 广告业务来构建的,由于这些业务天然具有极大的数据规模,因此从一开始,就需要思考如何在向量索引中支持百亿数据的检索需求,比如图虫拥有几亿图片素材,数量规模早已超出单机内存的极限,举个例子,对于 1 亿条 128 维的...
【PHP】thinkPHP6中的MVC思想的小案例
这个模块主要用来实现与后台数据库的数据交互,比如说,对数据库的增删改查等基本操作。 C(Controller)指的是控制层,这个层处在M层和V层之间,主要用来接受V发送过来的请求并根据请求给出响应结果,如果需要操... 点击上方的【创建数据库】,录入相关信息后,点击确认。如图所示:,**除了图数据库之外,血缘本身也会依赖元数据的存储,如 Mysql 以及索引类存储。 **在...
语聚AI公测发布,大语言模型时代下新的生产力工具
2 选择助手类型,创建1个AI助手3 完成助手基础配置(动作意图/知识库/对话模型)4 直接在语聚AI开始使用,或集成到网页、其他应用系统开始使用**语聚AI的3大助手如何使用?分别适用于什么场景?下面为您分... 数据库、集简云开放平台的方式,与现有应用列表以外的应用软件/自研系统对接。**使用场景示例:**(上滑查看)**🛍️销售团队:**销售团队经常需要处理各种销售管理软件、CRM系统、邮件系统...
Go 语言微服务介绍与开发实战|社区征文
图的左边就是单体架构的示意图,如图所示:单体架构将所有的功能(如 UI、日志、数据层、系统逻辑、数据库等)都集成在一个系统中,像是一个紧耦合的架构。相反,微服务是独立的实体,每个功能都是单独的服务,如日志服务、文件服务、系统逻辑服务等,更易于修改和替换,每个服务都可以通过各种远程传输机制进行沟通,如 HTTP、REST 或者 RPC。服务之间的交换的数据格式可以是 JSON 或者 Protocol buffers, 微服务还可以处理各种请求点,如...
数据库顶会 VLDB 2023 论文解读 - Krypton: 字节跳动实时服务分析 SQL 引擎设
读的时候多个版本的数据会按照不同的 Merge 算法合并为一份。Tablet 的 Commit Version 为该 Tablet 下 Rowset 的最大版本号,比如上图中 Tablet 2 的 Commit Version 为 Rowset 5 的版本号 21。每个 Query 都会带上... 线上对于这样的 Query Latency 要求比较高,所以我们采用了 MV 来加速这个 Query 的执行,具体做法如下:1. 为原始表创建两个 MV,一个按照天聚合,一个按照小时进行聚合。2. 将 Query 中的时间窗口拆分成三部分:...
万字长文,Spark 架构原理和 RDD 算子详解一网打进! | 社区征文
t_70#pic_center)### 1.2 各部分功能图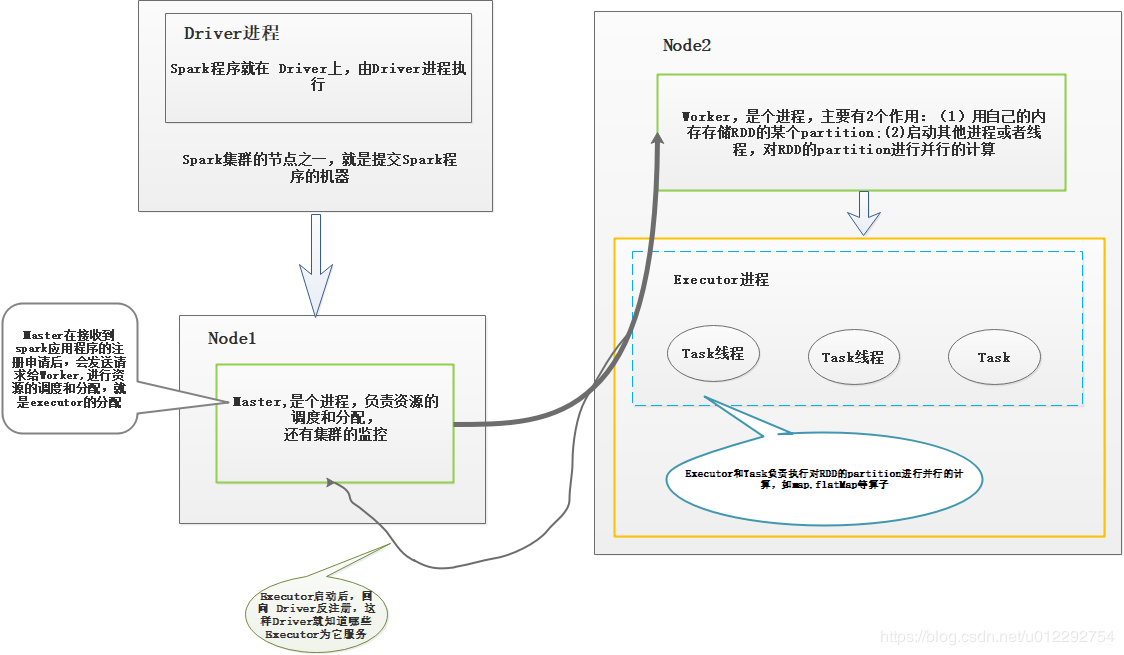> - Driver 注册了一些 Executor后,就可以开始正式执行 spark 应用程序了。第一步是创建 RDD,读取数据源;> - HDFS 文件被读取到多个 Worker节点,形成...
硬核干货!一文掌握 binlog 、redo log、undo log|社区征文
只要是对数据库有变更的操作都会记录到 binlog 里面来,我们可以把数据库的数据看做银行账户里的余额,而 binlog 就相当于我们银行卡的流水记录。账户余额只是一个结果,至于这个结果怎么来的,那就必须得看流水了。在实际应用中, binlog 的主要应用场景分别是 **主从复制** 和 **数据恢复**。1. **主从复制** :在 Master 端开启 binlog ,然后将 binlog 发送到各个 Slave 端, Slave 端重放 binlog 来达到主从数据一致。1. **数...
干货|揭秘字节跳动对Apache Doris 数据湖联邦分析的升级和优化
我们参考数据库的设计理念,增加了 Catalog 一层,将原有的 Database 和 Table 挂在 Internal Catalog 下,目前已经实现了 Hive Catalog、JDBC Catalog 和 ElasticSearch Catalog。 在该架构下,增加新的 Ca... 无需创建外表。其他类型的 Catalog 也类似。### **/****Multi-Catalog的元数据技术原理****/** 那么, Catalog 如何与外部元数据对接? 以 Hive MetaStore举例。元数据架构设计如下图所示...
