图数据库的作用是什么
 社区干货
社区干货
字节跳动自研万亿级图数据库 & 图计算实践
图数据对外提供的接口都是围绕这些元素展开。**图数据库本质也是一个存储系统**,它和常见的 KV 存储系统、MySQL 存储系统相比,主要区别在于目标数据的逻辑关系不同和访问模式不同,对于数据内在关系是图模型以及在图上游走类和模式匹配类的查询,比如社交关系查询,图数据库会有更大的性能优势和更加简洁高效的接口。**为什么不选择开源图数据库**图数据库在 90 年代出现,直到最近几年在数据爆炸的大趋势下快速发展,百花...
2022技术盘点之平台云原生架构演进之道|社区征文
数据库有MongoDB分片集群/MySQL/Redis/ElasticSearch/RabbitMQ进行各类业务数据计算和存储## 三 流量管控... Spring Cloud Kubernetes 配置中心方案简介:`spring-cloud-starter-kubernetes-config`是`spring-cloud-starter-kubernetes`下的一个库,作用是将kubernetes的configmap与SpringCloud Config结合起来。`spring-boo...
火山引擎 DataLeap 套件下构建数据目录(Data Catalog)系统的实践
图数据库等系统存储元数据,维护成本很高;接入一种元数据会增加2~3个ETL任务,运维成本直线上升## 新版本目标基于上述痛点,火山引擎 DataLeap 研发人员重新设计实现Data Catalog系统,希望能达成如下目标:- 产... 部分功能有借鉴意义 |## 升级思路根据调研结论,结合字节已有业务特点,火山引擎 DataLeap 研发人员敲定了以下发展思路:- 对于搜索、血缘这类核心能力,做深做强,对齐业界领先水平- 对于各...
字节跳动 NoSQL 的探索与实践
实际上图计算对于风控反作弊的异常识别和风险检测更适合。* **推荐模型**:图训练系统也支持推荐的核心模型,这也是字节跳动的的一个核心场景。目前 ByteGraph 在字节跳动内部的使用量有多大?这里列举一组数据:* 服务 **2000+** 内部用户(这里的用户指一个业务线或者一个小的 App)* **1000+**图数据库集群* 日均运行 **1000+** 图计算任务* 服务器规模 **1W+** 台。字节跳动为什么要自研这样一个庞大的系统?作...
 特惠活动
特惠活动
 图数据库的作用是什么-优选内容
图数据库的作用是什么-优选内容
 图数据库的作用是什么-相关内容
图数据库的作用是什么-相关内容
字节跳动 NoSQL 的探索与实践
实际上图计算对于风控反作弊的异常识别和风险检测更适合。* **推荐模型**:图训练系统也支持推荐的核心模型,这也是字节跳动的的一个核心场景。目前 ByteGraph 在字节跳动内部的使用量有多大?这里列举一组数据:* 服务 **2000+** 内部用户(这里的用户指一个业务线或者一个小的 App)* **1000+**图数据库集群* 日均运行 **1000+** 图计算任务* 服务器规模 **1W+** 台。字节跳动为什么要自研这样一个庞大的系统?作...
分布式数据库在抖音春晚活动中的应用
上图是现有的或者主流的大型数据库系统的架构,它分为三层:* 最上一层是应用,今日头条,抖音,西瓜视频等都是应用。* 中间层是数据库中间件层。* 底层是数据库层以及数据库下面的单机存储。这个架构应该是比较主流的大型后端的数据库架构,但这个架构有什么问题?首先是这个架构里使用了数据库中间件。 **中间件本身存在一定的使用限制** ,对用户不是很友好。举个例子,它可能在使用的过程中需要用户感知一些 sharding key...
分布式数据库在抖音春晚活动中的应用
我们为什么还需要去开发分布式数据库?这个问题的答案其实也比较显而易见,就是原有的架构不能很好地满足我们内部应用的需求,所以我们才会去寻找第二条路。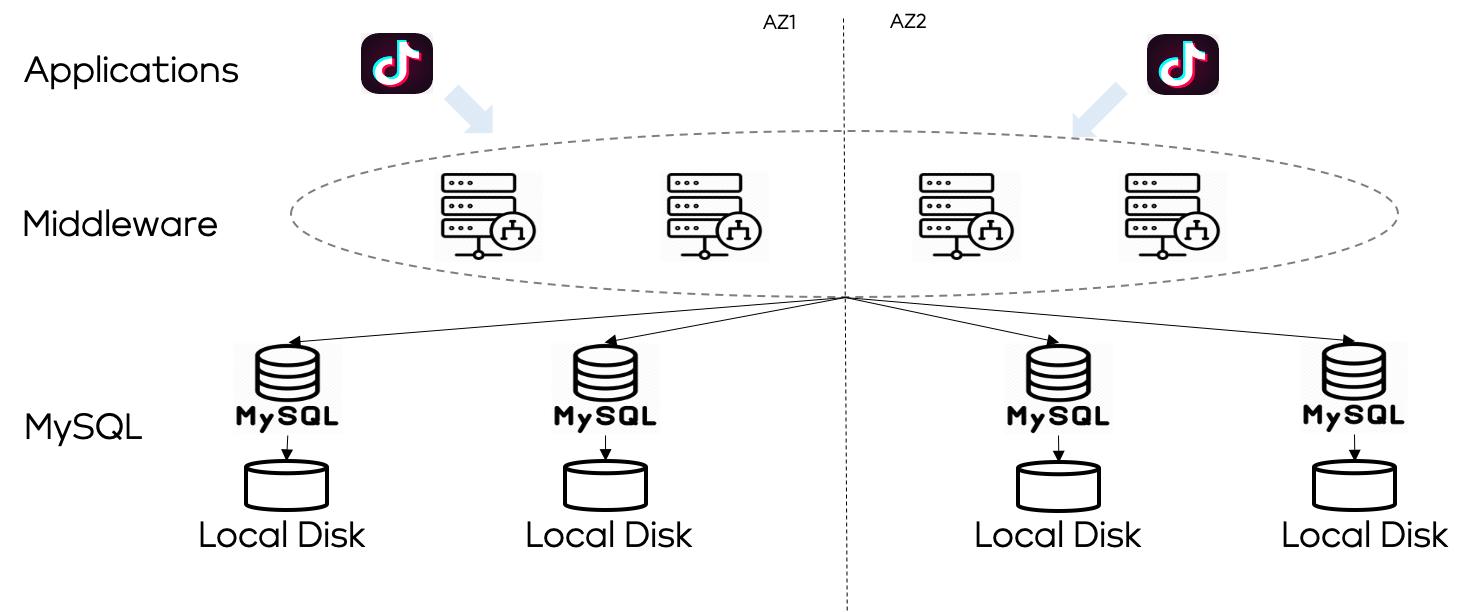上图是现有的或者主流的大型数据库系统的架构,它分为三层:- 最上一层是应用,今日头条,抖音,西瓜视频等都是应用。- 中间层是数据库中...
抖音大规模实践,火山引擎向量数据库是这样炼成的
AI时代,如何用好大模型是当前各行各业瞩目的焦点。向量数据库作为大模型“记忆体”,不仅能够为其提供数据存储,而且能通过数据检索、分析让大模型进行知识增强,成为生成式AI应用开发新范式的重要组成部分。用图片搜索图片或者文本搜索文本时,在数据库中存储和对比的并不是图片和视频片段,而是通过深度学习等算法将其提取出来的“特征”,“特征”提取的过程称为 Embedding,提取出的“特征”用数学中的向量来表示。向量化的目的是...
字节跳动 NoSQL 的探索与实践
业界以前的常用做法是使用 HBase 加上一个计算引擎。实际上图计算对于风控反作弊的异常识别和风险检测更适合。- 推荐模型:图训练系统也支持推荐的核心模型,这也是字节跳动的的一个核心场景。- 目前 ByteGraph 在字节跳动内部的使用量有多大?这里列举一组数据:- 服务 2000+ 内部用户(这里的用户指一个业务线或者一个小的 App)- 1000+ 图数据库集群- 日均运行 1000+ 图计算任务- 服务器规模 1W+ 台字节跳动为什么要自研这...
火山引擎DataLeap专家总结:3个必看的“数据血缘”建设经验!
把这个任务资产节点和表资产节点之间的边更新到图数据库中去。 **在实时更新的时候,我们有两种方案:** **方案一:**是在引擎侧,即在任务运行时,通过任务执行引擎把该任务在构建DAG后生成的血缘信息通过Hook送入。 **●****优点****:**在引擎侧的血缘采集是相对独立的,每个引擎在采集血缘的时候不会互相影响。**●****缺点:**1.每个引擎都需要适配一个血缘采集的Hook,一...
2022下半年《软考-系统架构设计师》备考经验分享
软件系统建模(UML图填空、问答)- 系统数据库设计(DFD图填空、问答)- 系统架构整体设计(表格填空、架构图填空、问答)- Web系统架构设计(表格填空、架构图填空、问答)- 单个场景详细设计:高可用设计、高性能设计、高可靠设计、微服务设计、可扩展性设计等(表格填空、架构图填空、问答)其中问答题一般有两种问法,一是概念问答类:- 请说明什么是xxx,并指出它的作用与特点;- 请说明A和B两种设计模式的区别和联系;二是方案...
基于 ByteHouse 构建实时数仓实践
高可用企业级分析性数据库,支持用户交互式分析 PB 级别数据。其自研的表引擎,灵活支持各类数据分析和保证实时数据高效落盘,实现了热数据按生命周自动冷存,缓解存储空间压力;同时引擎内置了图形化运维界面,可轻松对... 同时为 Flink SQL 数据转化与清洗提供缓冲作用,提高数据稳定性;ByteHouse 作为流式数据持久化存储层,使用 ByteHouse HaKafka 、HaUniqueMergeTree 表引擎可将 Kafka 临时数据高效稳定接入储存到 ByteHouse ,为后...
超复杂调用网下的服务治理新思路
第一个要点是微服务的数量。如果一个系统内的微服务数目只有几百个,那么绘制一张囊括所有微服务的调用图是有利于管理的;但如果超过了 1000 个,再把它们塞到一张图后整张图变得不可读,它的意义就不大了。第二点,... 如果用户想要在域外访问这个数据库,我们需要通过左下角的 Query、ETL 把它转化成一个离线数据库。整个大框是一个 domain,它不同于 DDD 的 domain,它被称为服务域,可以理解成是一组服务的集合。字节跳动内部也参考了...
