小卷积多线程下的PyTorch与mkl-dnn后端性能
 社区干货
社区干货
AI元年:一名前端程序员的技术之旅|社区征文
与我一同被裁的还有在公司待了2-3年的几个同事,有后端、测试、上位机。 在当前行业不景气的环境下,公司进行开“猿”节流的操作似乎也是正常的。或许对于大多数人来说,经历裁员是一种相对平常的事情,但对我而言,这... 它能在浏览器中使用卷积神经网络进行分类和回归任务。尽管该库现在已经停止维护,但在2018年,出现了许多JS的机器学习和深度学习框架,如`Tenforflow.js`、`synaptic`、`Brain.js`、`WebDNN`等等。由于浏览器的计算...
让欺诈风险无处遁形的计算机视觉| 社区征文
我们的识别模型主要应用了基于MKLDNN加速策略的分类网络模型,在多个任务上改善了轻量型模型的性能,整体网络使用串联结构,同时使用了深度可分离卷积作为Basic Block。Block不做short-cut连接,不会产生额外的拼接或者相加的操作,详细结构见下图3。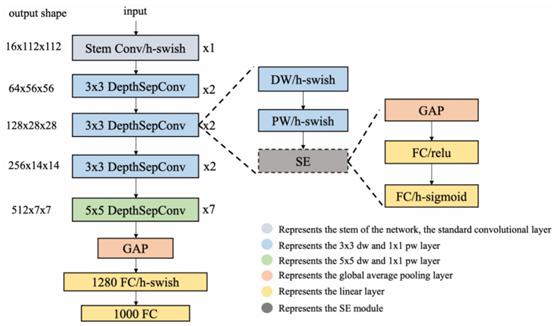图 3 基于MKLDNN加速策略的分类网络模型## 3.1创...
 特惠活动
特惠活动
 小卷积多线程下的PyTorch与mkl-dnn后端性能-优选内容
小卷积多线程下的PyTorch与mkl-dnn后端性能-优选内容
 小卷积多线程下的PyTorch与mkl-dnn后端性能-相关内容
小卷积多线程下的PyTorch与mkl-dnn后端性能-相关内容
搭建Llama-2-7b-hf模型进行推理
旨在为分布式深度学习训练提供高性能的通信支持。它提供了一组优化的通信算法和数据结构,可用于在分布式环境中实现高效的通信操作。 oneDNNoneDNN(oneAPI Deep Neural Network Library)是Intel®开发的一个深度学习... 执行如下命令,安装xFasterTransformer。 pip install torch==2.0.1+cpu --index-url https://download.pytorch.org/whl/cpupip install cmake==3.26.1 transformers==4.30.0 sentencepiece==0.1.99 tokenizers==...
GPU-部署Baichuan大语言模型
CUDNN:深度神经网络库,用于实现高性能GPU加速。本文以8.5.0.96为例。 运行环境:Transformers:一种神经网络架构,用于语言建模、文本生成和机器翻译等任务。深度学习框架。本文以4.30.2为例。 Pytorch:开源的Python机器学习库,实现强大的GPU加速的同时还支持动态神经网络。本文以2.0.1为例。 Anaconda:获取包且对包能够进行管理的工具,包含了Conda、Python在内的超过180个科学包及其依赖项,用于创建Python虚拟环境。本文以Anacon...
GPU-部署ChatGLM-6B模型
CUDNN:深度神经网络库,用于实现高性能GPU加速。本文以8.5.0.96为例。 运行环境:Transformers:一种神经网络架构,用于语言建模、文本生成和机器翻译等任务。本文以4.30.2为例。 Pytorch:开源的Python机器学习库,实现强大的GPU加速的同时还支持动态神经网络。本文以2.0.1为例。 Anaconda:获取包且对包能够进行管理的工具,包含了Conda、Python在内的超过180个科学包及其依赖项,用于创建Python虚拟环境。本文以Anaconda 3和Python 3...
搭建ChatGLM-6B大语言模型
如下图所示。 执行以下命令,安装相应的Intel依赖包。pip install mkl==2023.1.0 intel-openmp==2023.1.0 依次执行以下命令,在Conda环境下安装内存分配器Jemalloc。 conda install jemallocpip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cpupip install transformers 安装Gradio。 执行pip install gradio sentencepiece命令,安装Gradio。 执行pip list grep gradio命令进行验证,回...
HPC裸金属-基于NCCL的单机/多机RDMA网络性能测试
购买实例请参见购买高性能计算GPU型实例。 实例规格 实例数量 镜像类型 驱动安装/版本 是否绑定公网IP ecs.ebmhpcpni2l.32xlarge 2 Ubuntu 20.04 创建实例时勾选“后台自动安装GPU驱动”:系统将自动安装GPU驱动、CUDA和cuDNN库(驱动版本见下图)以及Faric manager安装包。 说明 实例创建完成后您只需启动NVIDIA-Fabric Manager即可。 是,如未绑定,请参见绑定公网IP。 方式一:在虚拟环境中测试网络性能步骤一:搭建Pytorch虚...
GPU-使用Llama.cpp量化Llama2模型
可以理解和生成更长的文本内容。 环境要求NVIDIA驱动: GPU驱动:用来驱动NVIDIA GPU卡的程序。本文以535.86.10为例。 CUDA:使GPU能够解决复杂计算问题的计算平台。本文以CUDA 12.2为例。 CUDNN:深度神经网络库,用于实现高性能GPU加速。本文以8.5.0.96为例。 运行环境: Transformers:一种神经网络架构,用于语言建模、文本生成和机器翻译等任务。深度学习框架。本文以4.30.2为例。 Pytorch:开源的Python机器学习库,实现强大的G...
