医院数据库er图的制作
 社区干货
社区干货
字节跳动自研万亿级图数据库 & 图计算实践
本文将对字节跳动自研的分布式图数据库和图计算专用引擎做深度解析和分享,展示新技术是如何解决业务问题,影响几亿互联网用户的产品体验。来源:字节跳动技术团队图状结构数据广泛存在 ... 并将介绍图计算相关实践。 自研图数据库(ByteGraph)介绍 从数据模型角度看,图数据库内部数据是有向属性图,其 **基本元素是 Graph 中的点(Vertex)、边(Edge)以及其上附着的属性...
干货 | 以一次Data Catalog架构升级为例,聊聊业务系统的性能优化
是基于LinkedIn Wherehows进行二次改造,产品早期只支持Hive一种数据源。后续为了支持业务发展,做了很多修修补补的工作,系统的可维护性和扩展性变得不可忍受。比如为了支持数据血缘能力,引入了字节内部的图数据库veGraph,写入时,需要业务层处理MySQL、ElasticSearch和veGraph三种存储,模型也需要同时理解关系型和图两种。更多的背景可以参照之前的[文章](https://mp.weixin.qq.com/s?__biz=MzkwMzMwOTQwMg==&mid=2247492653&idx=...
2022技术盘点之平台云原生架构演进之道|社区征文
下图为SmartOps架构全景: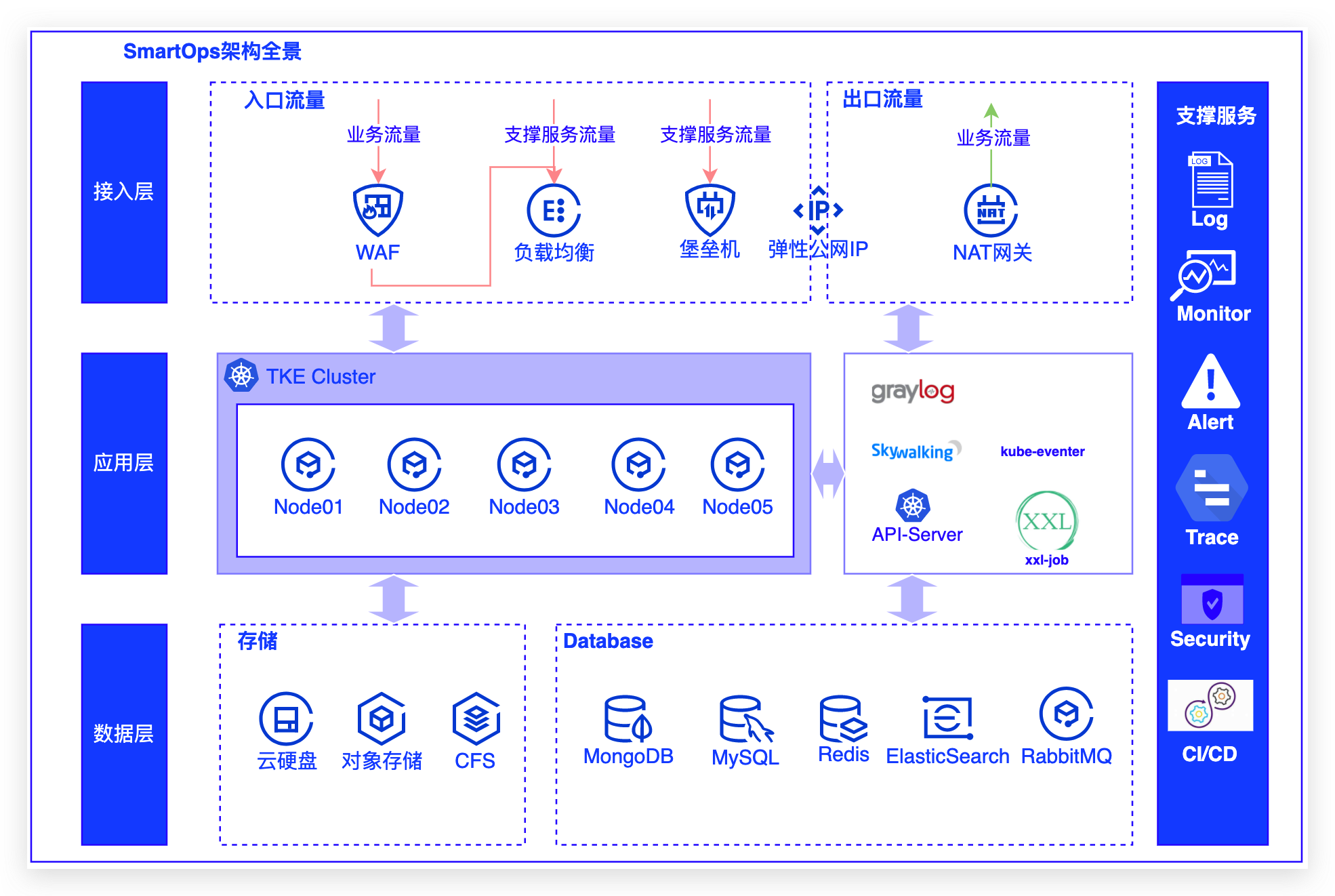- 接入层:通过WAF/SLB,配合NAT网关治理出方向流量,部署有堡垒机进行运维等其他辅助业务进行支撑;- 应用层:采用腾讯TKE进行业务容器部署,配合K8s原生服务注册发现/配置中心/分布式调度中心/日志/监控/告警/链路追踪/DevOps等构筑完整应用体系;- 数据层:存储使用有云硬盘/对象存储/CFS,数据库有Mon...
如何构建企业内的 TiDB 自运维体系
上图是我们目前的接入方式和整体架构。TiDB 的部署架构这里就不做赘述了,需要了解的同学可以参考官方文档。我们之所以采用 SLB 来做 TiDB 的负载均衡接入,就是为了简化接入成本与运维成本,访问流量的负载均衡以及节... TiDB Server、PD 采用无本地 SSD 机型,TiKV 采用本地 SSD 机型。既兼顾了性能,又能降低成本。详细的机型选择会在后面的内容提到。# 3 MySQL 与 TiDB 的对比圈内一直流传着一句话,没有一种数据库是"银弹"。绝大...
 特惠活动
特惠活动
 医院数据库er图的制作-优选内容
医院数据库er图的制作-优选内容
 医院数据库er图的制作-相关内容
医院数据库er图的制作-相关内容
干货 | ByteHouse:基于ClickHouse 的实时计算能力升级
不希望在数据库当中只存聚合的数据。**●****交互式分析需求的灵活性。**数千个维度都要能够达到秒级的快速响应。 最后,在满足前述两点基础上,还要做到**成本可控。**最开始,团队内部其实也列出了... **使ByteHouse能够做很多开源ClickHouse做不到的场景。******●** 高可用表引擎:**相比社区的ReplicatedMergeTree,高可用表引擎支持的整体表数量更多,支持的集群规模更大,稳定性更高。 ****●** ...
火山引擎 DataLeap 套件下构建数据目录(Data Catalog)系统的实践
做好一个Data Catalog产品,本身是一个门槛低、上限高的工作,需要有一个持续打磨提升的过程。## 旧版本痛点字节跳动Data Catalog产品早期为能较快解决Hive的元数据收集与检索工作,是基于LinkedIn Wherehows进行... 图数据库等系统存储元数据,维护成本很高;接入一种元数据会增加2~3个ETL任务,运维成本直线上升## 新版本目标基于上述痛点,火山引擎 DataLeap 研发人员重新设计实现Data Catalog系统,希望能达成如下目标:- 产...
一文读懂火山引擎云数据库产品及选型
为什么要做数据库选型 **数据库选型的重要性与难点**发展数字经济是当下各行各业的重要方向。支撑数字经济的底座是软件,特别是基础软件,可以说基础软件是整个数字经济的坚实底座。在基础... 又出现了 NoSQL 数据库技术,其理论基础主要是由 Eric Brewer 提出的 CAP 定理以及 Dan Pritchett 提出的 BASE 原则。再往后,业界将关系型数据库与 NoSQL 数据库的优势进行了融合,出现了 NewSQL 数据库,随着云原...
干货|字节跳动基于 Apache Hudi 的多流拼接实践
以及 KV 数据库中的维度数据。业务侧通常会基于实时计算引擎在流上做多个数据源的 JOIN 产出这个宽表,但这种解决方案在实践中面临较多挑战,主要可分为以下两种情况:**01 - 维表 JOIN*** **场景挑... 更新过程中不需要做多流数据合并,下游读取时再 Merge 多流数据,因此不需要缓存维度数据,同时可以在执行 Compact 时进行 Merge,加速下游查询。**此外,多流拼接方案还支持:*** 内置通用模板,支持数据去重等通用...
干货|湖仓一体架构在火山引擎LAS的探索与实践
=&rk3s=8031ce6d&x-expires=1714926029&x-signature=OUeQAkd418rCGeCAOmFFerdTDjA%3D) 火山引擎湖仓一体分析服务LAS(Lakehouse Analytics Service),是面向湖仓一体架构的 Serverless 数据处理分析服务,提供... 一种从1980年开始的基于传统数据库技术来做的BI分析场景。在这种架构下,通常计算和存储是高度一体的。整体系统能支撑的计算能力,依赖于服务提供商的硬件配置,整体成本高,存在物理上限,扩展起来比较麻烦。 ...
基于 Flink 构建实时数据湖的实践
本文整理自火山引擎云原生计算研发工程师王正和闵中元在本次 CommunityOverCode Asia 2023 数据湖专场中的《基于 Flink 构建实时数据湖的实践》主题演讲。实时数据湖是现代数据架构的核心组成部分,随着数... ERT/UPDATE 等标准 SQL 语法** ,满足 OLAP 用户的交互需求。* **强大的连接器生态系统** 。Flink 为输入和输出定义了全面的接口,并实现了许多嵌入式连接器,如数据库、数据湖仓库。用户也可以基于这些接口轻松实现...
2022下半年《软考-系统架构设计师》备考经验分享
如下图所示,软考有3个级别5个专业,很多同学在报名的时候不知道如何选择科目。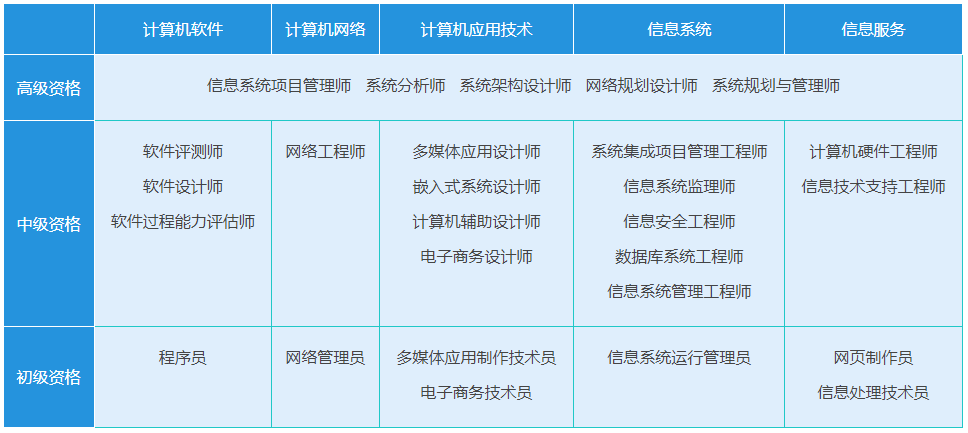软考高级比中级的难度要大一些。中级考试为基础... 数据库系统(设计范式、关系代数、SQL、数据架构、并发控制等)、计算机网络(常见网络设备、常用协议、组网方式等)、嵌入式系统(嵌入式操作系统、多核处理等),每个部分基本就是学校里面所学知识的简化版。针对这一部...
第一现场|字节跳动开源BitSail:重构数据集成引擎,走向云原生化、实时化
也做了深度的考量。据 Gartner 数据,2021 年数据集成全球市场规模达 38.5 亿美元。王宇飞认为,目前数据集成的市场需求正在快速增长,一方面是因为随着硬件成本降低,传统的 ETL 模式开始转变为 EL(T... 主要用于在关系型数据库和 Hadoop 之间传输数据的 Sqoop,虽然属于 Hadoop 生态,但社区一直不太活跃,同时 Sqoop 基于 EMR 架构,本身效率要差一些,且只支持批式传输、不支持实时传输。最终团队决定基...
OLAP引擎也能实现高性能向量检索,据说QPS高于milvus!
本篇将结合ByteHouse团队对向量数据库行业和技术的前沿观察,详细解读OLAP引擎如何建设高性能的向量检索能力,并最终通过开源软件VectorDBBench测试工具,在 cohere 1M 标准测试数据集上,recall 98 的情况下,QPS性能已可以超过专用向量数据库(如milvus)。# 向量检索现状分析## 向量检索定义对于诸如图片、视频、音频等非结构化数据,传统数据库方式无法进行处理。目前,通用的技术是把非结构化数据通过一系列 embedding 模型将它...
