Java网关进程在发送其端口号之前已退出Spark。
 社区干货
社区干货
干货 | 在字节跳动,一个更好的企业级SparkSQL Server这么做
构建SparkSQL服务器最好的方式是用如上Java接口,且大数据生态下行业已有标杆例子,即Hive Server2。Hive Server2在遵循Java JDBC接口规范上,通过对数据操作的方式,实现了访问Hive服务。除此之外,Hive Server2在实现... 那么就需要提供一个SparkSQL的JDBC Driver,而目前大数据领域Hive Server2提供的Hive-JDBC-Driver已经被广泛使用,从迁移成本来说最好的方式就是保持Hive的使用方式不变,只需要换个端口就行,也就是可以通过Hive的JDB...
Pulsar 在云原生消息引擎领域为何如此流行?| 社区征文
可跨机房在集群间无缝地完成消息复制。 - 极低的发布延迟和端到端延迟。 - 可无缝扩展到超过一百万个 topic。 - 简单的客户端 API,支持 Java、Go、Python 和 C++。 - 主题的多种订阅模式(独占、共享和故障转移... 消费者将在内存缓存所有的块消息,直到收到所有的消息块。将这些消息合并成为原始的消息 M1,发送给处理进程。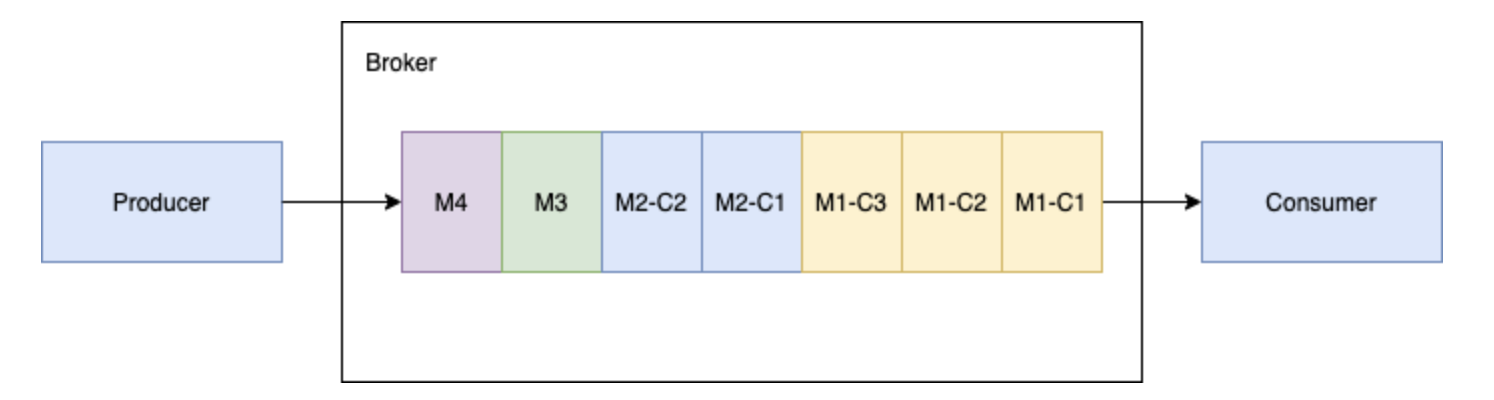##### 3...
干货 | 在字节跳动,一个更好的企业级SparkSQL Server这么做
> > > SparkSQL是Spark生态系统中非常重要的组件。面向企业级服务时,SparkSQL存在易用性较差的问题,导致> 难满足日常的业务开发需求。> **本文将详细解读,如何通过构建SparkSQL服务器实现使用效率提升和使用门... Java.sql包下定义了使用Java访问存储介质的所有接口,但是并没有具体的实现,也就是说JavaEE里面仅仅定义了使用Java访问存储介质的标准流程,具体的实现需要依靠周边的第三方服务实现。 例如,访问MySQL的mysq...
在字节跳动,一个更好的企业级 SparkSQL Server 这么做
构建SparkSQL服务器最好的方式是用如上Java接口,且大数据生态下行业已有标杆例子,即Hive Server2。Hive Server2在遵循Java JDBC接口规范上,通过对数据操作的方式,实现了访问Hive服务。除此之外,Hive Server2在实现... 那么需要提供SparkSQL的JDBC Driver。目前,大数据领域Hive Server2提供的Hive-JDBC-Driver已经被广泛使用,从迁移成本来说最好的方式就是保持Hive的使用方式不变,只需要换个端口就行,也就是可以通过Hive的JDBC Driv...
 特惠活动
特惠活动
 Java网关进程在发送其端口号之前已退出Spark。-优选内容
Java网关进程在发送其端口号之前已退出Spark。-优选内容
 Java网关进程在发送其端口号之前已退出Spark。-相关内容
Java网关进程在发送其端口号之前已退出Spark。-相关内容
EMR-3.8.0 版本说明
环境信息 版本 环境 OS veLinux(Debian 10兼容版) Python2 2.7.16 Python3 3.10.13 Java ByteOpenJDK 1.8.0_352 系统环境应用程序版本 Hadoop集群 Flink集群 Kafka集群 Pulsar集群 Presto集群 Trino集群 HBase集群 Doris集群 StarRocks集群 HDFS 3.3.4 3.3.4 - - 3.3.4 3.3.4 3.3.4 - - YARN 3.3.4 3.3.4 - - - - 3.3.4 - - MapReduce2 3.3.4 3.3.4 - - - - 3.3.4 - - Hive 3.1.3 - - - 3.1.3 3.1.3 - - - Spark 3.3.3 - - - - -...
干货 | 在字节跳动,一个更好的企业级SparkSQL Server这么做
> > > SparkSQL是Spark生态系统中非常重要的组件。面向企业级服务时,SparkSQL存在易用性较差的问题,导致> 难满足日常的业务开发需求。> **本文将详细解读,如何通过构建SparkSQL服务器实现使用效率提升和使用门... Java.sql包下定义了使用Java访问存储介质的所有接口,但是并没有具体的实现,也就是说JavaEE里面仅仅定义了使用Java访问存储介质的标准流程,具体的实现需要依靠周边的第三方服务实现。 例如,访问MySQL的mysq...
在字节跳动,一个更好的企业级 SparkSQL Server 这么做
构建SparkSQL服务器最好的方式是用如上Java接口,且大数据生态下行业已有标杆例子,即Hive Server2。Hive Server2在遵循Java JDBC接口规范上,通过对数据操作的方式,实现了访问Hive服务。除此之外,Hive Server2在实现... 那么需要提供SparkSQL的JDBC Driver。目前,大数据领域Hive Server2提供的Hive-JDBC-Driver已经被广泛使用,从迁移成本来说最好的方式就是保持Hive的使用方式不变,只需要换个端口就行,也就是可以通过Hive的JDBC Driv...
EMR-3.5.3 版本说明
环境信息 系统环境版本 环境 OS veLinux(Debian 10兼容版) Python2 2.7.16 Python3 3.7.3 Java ByteOpenJDK 1.8.0_352 应用程序版本 Hadoop集群 Flink集群 Kafka集群 Pulsar集群 Presto集群 Trino集群 HBase集群 S... Spark组件中修复HistoryServer状态异常问题,保证管控端的显示状态和HistoryServer的进程状态一致。 组件版本 下面列出了 EMR 和此版本一起安装的组件。 组件 版本 描述 zookeeper_server 3.7.0 用于维护配置信息、...
EMR-3.7.0 版本说明
环境信息 版本 环境 OS veLinux(Debian 10兼容版) Python2 2.7.16 Python3 3.10.13 Java ByteOpenJDK 1.8.0_352 系统环境应用程序版本 Hadoop集群 Flink集群 Kafka集群 Pulsar集群 Presto集群 Trino集群 HBase集群 Doris集群 StarRocks集群 HDFS 3.3.4 3.3.4 - - 3.3.4 3.3.4 3.3.4 - - YARN 3.3.4 3.3.4 - - - - 3.3.4 - - MapReduce2 3.3.4 3.3.4 - - - - 3.3.4 - - Hive 3.1.3 - - - 3.1.3 3.1.3 - - - Spark 3.3.3 - - - - -...
EMR-2.1.1 版本说明
环境信息 系统环境版本 环境 OS veLinux(Debian 10兼容版) Python2 2.7.16 Python3 3.7.3 Java ByteOpenJDK 1.8.0_352 应用程序版本 Hadoop集群 HBase集群 Flume 1.9.0 - OpenLDAP 2.4.58 2.4.58 Ranger 1.2.0 - ZooKeeper 3.7.0 3.7.0 Flink 1.15.1 - HDFS 2.10.2 2.10.2 MapReduce2 2.10.2 - YARN 2.10.2 - Airflow 2.4.2 - Hive 2.3.9 - Hue 4.9.0 - Knox 1.5.0 - Presto 0.267 - Trino 392 - Spark 2.4.8 - Sqoop 1.4.7 - Te...
EMR-3.6.1 版本说明
环境信息 系统环境版本 环境 OS veLinux(Debian 10兼容版) Python2 2.7.16 Python3 3.10.13 Java ByteOpenJDK 1.8.0_352 应用程序版本 Hadoop集群 Flink集群 Kafka集群 HBase集群 StarRocks集群 ClickHouse集群 Op... Spark 3.3.3 - - - - - - Sqoop 1.4.7 - - - - - - Tez 0.10.2 - - - - - - Iceberg 1.2.0 - - - - - - Hudi 0.12.2 - - - - - - HBase 2.3.7 - - 2.3.7 - - - OpenSearch - - - - - - 1.2.3 Doris - - - - - - - ...
EMR-3.5.4 版本说明
环境信息 系统环境版本 环境 OS veLinux(Debian 10兼容版) Python2 2.7.16 Python3 3.7.3 Java ByteOpenJDK 1.8.0_352 应用程序版本 Hadoop集群 Flink集群 Kafka集群 Pulsar集群 Presto集群 Trino集群 HBase集群 S... Spark 3.3.3 - - - - - - - - Sqoop 1.4.7 - - - - - - - - Tez 0.10.1 - - - - - - - - Iceberg 1.2.0 - - - - - - - - Hudi 0.12.2 - - - - - - - - HBase 2.3.7 - - - - - 2.3.7 - - OpenSearch - - - - - - - ...
EMR-2.1.0版本说明
环境信息 系统环境版本 环境 OS veLinux(Debian 10兼容版) Python2 2.7.16 Python3 3.7.3 Java ByteOpenJDK 1.8.0_302 应用程序版本 Hadoop集群 HBase集群 Flume 1.9.0 - OpenLDAP 2.4.58 2.4.58 Ranger 1.2.0 - ZooKeeper 3.7.0 3.7.0 Flink 1.15.1 - HDFS 2.10.2 2.10.2 MapReduce2 2.10.2 - YARN 2.10.2 - Airflow 2.4.2 - Hive 2.3.9 - Hue 4.9.0 - Knox 1.5.0 - Presto 0.267 - Trino 392 - Spark 2.4.8 - Sqoop 1.4.7 - Te...
