Java网关进程在发送端口号之前退出Spark和Python
 社区干货
社区干货
Pulsar 在云原生消息引擎领域为何如此流行?| 社区征文
可跨机房在集群间无缝地完成消息复制。 - 极低的发布延迟和端到端延迟。 - 可无缝扩展到超过一百万个 topic。 - 简单的客户端 API,支持 Java、Go、Python 和 C++。 - 主题的多种订阅模式(独占、共享和故障转移... 消费者将在内存缓存所有的块消息,直到收到所有的消息块。将这些消息合并成为原始的消息 M1,发送给处理进程。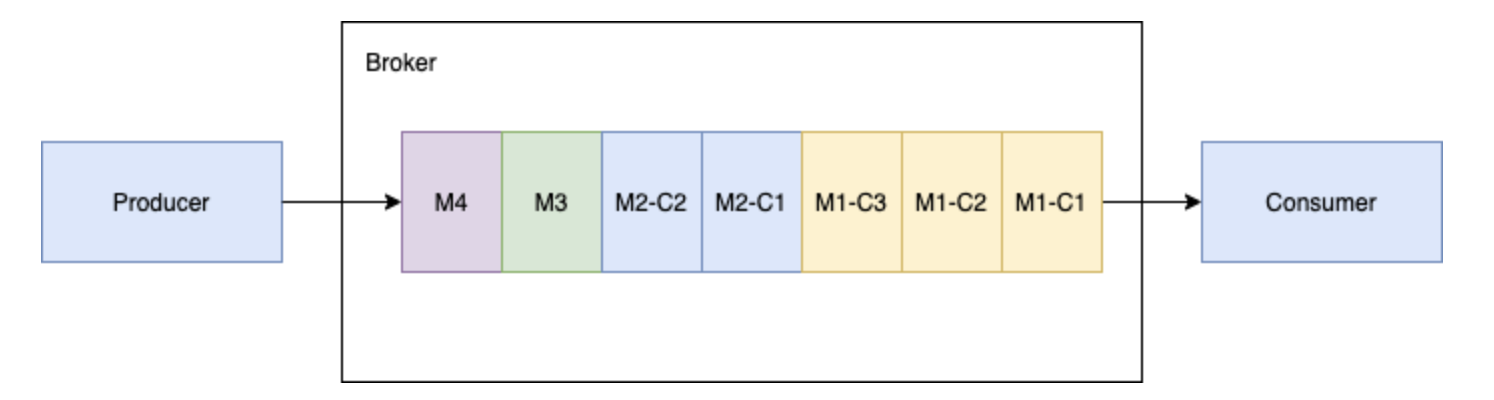##### 3...
干货|火山引擎DataTester:5个优化思路,构建高性能A/B实验平台
避免了长链接导致的很多网关超时问题,页面多次刷新时更快返回数据提高用户体验 。不同的训练框架有各自的调度和资源要求,这就给底层基础设施带来一些挑战。#### 存储侧存储可以认为是机器学习的刚需,在存储侧面临的挑战也很大:- 高性能和扩展性:现在的硬... 在用户界面层,平台支持 Web 页面、openAPI、交互式命令行、PythonSDK 等开发方式。往下一层我们提供了丰富的机器学习功能,包括数据标注、开发机、Job 化训练、离线批量推理、Kubeflow Pipeline 等。平台底层接...
字节跳动 EB 级 Iceberg 数据湖的机器学习应用与优化
然而 Hudi 在读取时的合并性能不太理想,涉及多种格式的转换、溢出磁盘引起额外 IO 等。此外 Hudi 不支持原生 Python API,只能通过 PySpark 的方式对于算法工程师来说不太友好。- Apache Iceberg 是一种开放的表... 同进程零复制、极低序列化开销、向量化计算等能力。Iceberg 社区也拥有对 Arrow 向量化读取的支持,但是不支持复杂嵌套类型,这对包含嵌套类型数据的训练样本极不友好,而猛犸数据集则能够很好的支持。在字节开源的...
 特惠活动
特惠活动
 Java网关进程在发送端口号之前退出Spark和Python
-优选内容
Java网关进程在发送端口号之前退出Spark和Python
-优选内容
 Java网关进程在发送端口号之前退出Spark和Python
-相关内容
Java网关进程在发送端口号之前退出Spark和Python
-相关内容
火山引擎大规模机器学习平台架构设计与应用实践
以及其他框架(SparkML、Ray 等)。不同的训练框架有各自的调度和资源要求,这就给底层基础设施带来一些挑战。#### 存储侧存储可以认为是机器学习的刚需,在存储侧面临的挑战也很大:- 高性能和扩展性:现在的硬... 在用户界面层,平台支持 Web 页面、openAPI、交互式命令行、PythonSDK 等开发方式。往下一层我们提供了丰富的机器学习功能,包括数据标注、开发机、Job 化训练、离线批量推理、Kubeflow Pipeline 等。平台底层接...
EMR 1.2.0版本说明
环境信息 系统环境版本 环境 OS veLinux(Debian 10兼容版) Python2 2.7.16 Python3 3.7.3 Java ByteOpenJDK 1.8.0_302 应用程序版本组件 Hadoop集群 Flink集群 Kafka集群 Presto集群 Trino集群 HBase集群 OpenSear... Spark 3.2.1 - - - - - - 3.2.1 Sqoop 1.4.7 - - - - - - - Kerby 2.0.1 - - - - - - - Tez 0.10.1 - - - - - - - Iceberg 0.12.0 - - 0.12.0 0.12.0 - - - Hudi 0.10.0 - - - - - - - HBase - - - - - 2.3.7 - - ...
EMR Spark
1 概述EMR Spark 任务适用于使用 Java\Python Spark 处理数据的场景,支持引用 Jar 资源包和 Python 语句的方式来定时执行 EMR Spark 任务。 2 使用前提若仅开通 Dataleap 产品湖仓一体的服务,不支持绑定 EMR 引擎。... 您可单击操作栏中的保存和调试按钮,进行任务调试。 注意 调试操作,直接使用线上数据进行调试,需谨慎操作。 本任务类型支持调试执行成功或失败后发送消息通知,您可根据业务情况,前往项目控制台 > 配置信息 > 消息通...
字节跳动 EB 级 Iceberg 数据湖的机器学习应用与优化
然而 Hudi 在读取时的合并性能不太理想,涉及多种格式的转换、溢出磁盘引起额外 IO 等。此外 Hudi 不支持原生 Python API,只能通过 PySpark 的方式对于算法工程师来说不太友好。- Apache Iceberg 是一种开放的表... 同进程零复制、极低序列化开销、向量化计算等能力。Iceberg 社区也拥有对 Arrow 向量化读取的支持,但是不支持复杂嵌套类型,这对包含嵌套类型数据的训练样本极不友好,而猛犸数据集则能够很好的支持。在字节开源的...
从100w核到450w核:字节跳动超大规模云原生离线训练实践
**Spark** **一起** **成为** **公司离线** **YARN** **集群的** **TOP** **计算框架** **。****云原生离线训练 3.0**云原生训练 2.0 资源部署在字节跳动深度定制的离线调度 YARN 集... 指对于原生的 TensorFlow 需要支持 Work 和 PS 服务的互相发现,所以基于这种策略,在所有角色都申请到资源后统一发送启动命令,实现 IP 加端口的相互传递。后面我们引入了 **Order 策略**,以弹性的方式申请 Wo...
关于 DataLeap 中的 Notebook你想知道的都在这
它是一个独立的进程。每一次「运行」动作,产生的效果是单个 Cell 的代码被运行。具体来讲,「运行」就是把 Cell 内的代码片段,通过 Jupyter Notebook 后端以特定格式发送给 Kernel 进程,再从 Kernel 接受特定格式的... 同时还接入了 DataLeap 提供的 Python & SQL 代码智能补全功能。额外地,我们还开发了定制的可视化 SDK,使得用户在 Notebook 上计算得到的 Pandas Dataframe 可以接入 DataLeap 数据研发已经提供的数据结果分析模...
「一周资讯精选」定期更新 [11.4-11.10] | 火山引擎开发者社区
[火山引擎 LAS Spark 升级:揭秘 Bucket 优化技术](https://developer.volcengine.com/articles/7293516897059307556)🔥**产品动态**1. [「火山引擎」数智平台VeDI增长营销季刊VOL.07](https://developer.vo... 灵活精准的流量管理——火山引擎 API 网关正式开启公测](https://developer.volcengine.com/articles/7257414049057964051)[4. 火山引擎发布新一代云原生监控引擎 VMP](https://developer.volcengine.com/artic...
字节跳动 MapReduce - Spark 平滑迁移实践
公司内部每天线上约运行 100万+ Spark 作业,与之相对比的是,线上每天依然约有两万到三万个 MapReduce 任务,从大数据研发和用户角度来看,MapReduce 引擎的运维和使用也都存在着一系列问题。在此背景下,字节跳动 Bat... Python,甚至 C++ 程序,虽然 Spark 有一个 Pipe 算子,但是让用户把已有的作业迁移到 Spark Pipe 算子还是有很大的工作量。最后,在有用户协助启动改造的情况下,还会面临很多其他问题,比如在主要计算逻辑的迁移之...
字节跳动 MapReduce - Spark 平滑迁移实践
《字节跳动 MapReduce - Spark 平滑迁移实践》主题演讲。随着字节业务的发展,公司内部每天线上约运行 100万+ Spark 作业,与之相对比的是,线上每天依然约有两万到三万个 MapReduce 任务,从大数据研发和用户角... Python,甚至 C++ 程序,虽然 Spark 有一个 Pipe 算子,但是让用户把已有的作业迁移到 Spark Pipe 算子还是有很大的工作量。最后,在有用户协助启动改造的情况下,还会面临很多其他问题,比如在主要计算逻辑的迁移之...
