Spark数据集根据过滤条件合并两行,并丢弃剩下的一行。
 社区干货
社区干货
数据库顶会 VLDB 2023 论文解读:Krypton: 字节跳动实时服务分析 SQL 引擎设计
数据通过 Kafka 流入不同的系统。对于离线链路,数据通常流入到 Spark/Hive 中进行计算,结果通过 ETL 导入到 HBase/ES/ClickHouse 等系统提供在线的查询服务。对于实时链路, 数据会直接进入到 HBase/ES 提供高并发低... 但是相同 PK 多行的合并算法不同列可以自定义。 **架构** 特惠活动
特惠活动
 Spark数据集根据过滤条件合并两行,并丢弃剩下的一行。-优选内容
Spark数据集根据过滤条件合并两行,并丢弃剩下的一行。-优选内容
 Spark数据集根据过滤条件合并两行,并丢弃剩下的一行。-相关内容
Spark数据集根据过滤条件合并两行,并丢弃剩下的一行。-相关内容
SELECT 语句
Spark SQL 中,JOIN 子句用于结合来自两个或多个表的数据。根据数据之间的关系,有几种不同类型的 JOIN: INNER JOIN:只返回两个表中匹配连接条件的行。 LEFT OUTER JOIN 或 LEFT JOIN:返回左表的所有行,即使右表中没... 根据当前行的相对位置访问行的值。窗口函数本身比较复杂,其包含三个主要部分: Rank 函数:用于排序,又分为几个子类 RNAK:为每个窗口内的行分配一个唯一的序号。如果存在相同的值,则会跳过序号。例如,如果有两行并列...
火山引擎DataLeap背后的支持者 - 工作流编排调度系统FlowX
> 更多技术交流、求职机会,欢迎关注字节跳动数据平台微信公众号,回复【1】进入官方交流群# 背景介绍## 业务场景在日常工作中,我们时不时需要对某些逻辑进行重复调度,这时我们就需要一个调度系统。根据不同的... 更好的集成了Hadoop 相关功能,方便用户可以简单跑起Spark/Hive 等任务。其中与Airflow 不同的是Azkaban 和Oozie是通过配置/DSL 的形式来进行DAG的配置。在社区活跃度上与Airflow相比有一定的差距。## 其他开源系...
Pulsar 在云原生消息引擎领域为何如此流行?| 社区征文
Apache Pulsar 是 Apache 软件基金会的顶级项目,是下一代云原生分布式消息流平台,集消息、存储、轻量化函数式计算为一体,采用计算与存储分离架构设计,支持多租户、持久化存储、多机房跨区域数据复制,具有强一致性、... 将这些消息合并成为原始的消息 M1,发送给处理进程。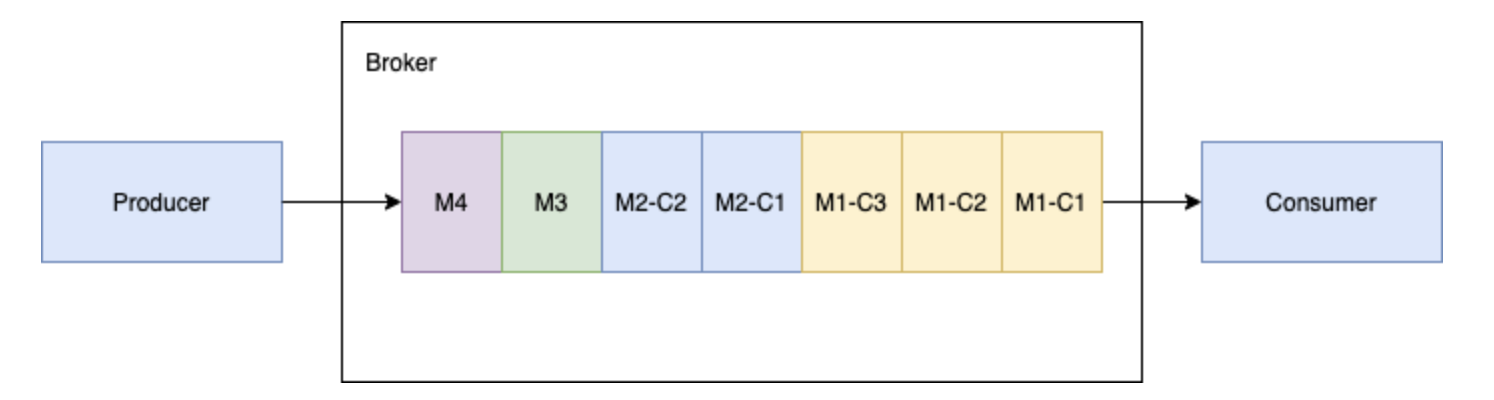##### 3.2.5.2 处理多个 producer 和一个订阅 consumer 的分块消息...
干货 | 字节跳动埋点数据流建设与治理实践(下)
我们对脏数据问题、埋点字段类型错误问题和埋点数据的丢失重复问题进行了监控和治理。这次我们主要选取了其中部分治理项目和大家分享。**单机问题优化*** **Flink BacklogRescale**Yarn单机问题... 目前字节跳动Flink使用的Yarn Gang Scheduler会按条件约束选择性地分配Yarn资源,在任务启动时均衡的放置Container,但是由于时间的推移,流量的变化等各种因素,队列还是会出现负载不均衡的情况,所以反调度策略就是为...
一文理解 HyperLogLog(HLL) 算法 | 社区征文
HyperLogLog(HLL) 算法是一种估算海量数据基数的方法,被广泛用于各个数据库产品中。与精确的基数统计算法相比,HLL 具备**可合并性 (mergeability)** ,因而可以方便地对海量数据进行并行计算,被广泛地用于大数据多... 该算法族被广泛用于许多大数据基础组件中,用于支持基数、分位数等的快速计算。例如:- Hive/Spark 通过[官方 UDF/UDAF](https://github.com/apache/datasketches-hive) 的方式使用 DataSketch;- Apache Druid 通...
浅谈AI机器学习及实践总结 | 社区征文
而一批特征和标签的集合,就是机器学习的数据集。机器学习的学习过程就是在已知的数据集的基础上,通过反复的计算,选择最准确的函数去描述数据集中自变量X1,X2....Xn 和因变量Y之间的因果关系。这个过程就称之为机... 如果没有可以剔除残缺的数据,也可以用其他数据记录的平均值、随机值或者0来补值,这个补值的过程叫数据修复。- 第二种是处理重复的数据,如果完全重复的数据删掉就行,如果同一个主键出现两行不同的数据,就需要看看...
python反序列化
在程序执行结束后被自动丢弃 .2. Python进程会把编译好的字节码转发到PVM(Python虚拟机)中,PVM会循环迭代执行字节码指令,直到所有操作被完成。#### PVM与Pickle模块的关系Pickle是一门基于栈的编程语言 ... 简单来说就是将反序列化完成的数据以 key-value的形式储存在memo中,以便使用。- 指令处理器可读的操作码(稍重要)1. c: (称为GLOBAL操作符)读取本行的内容作为模块名module, 读取下一行的内容作为对象名obje...
消息队列选型之 Kafka vs RabbitMQ
所以落入后端数据库上的并发请求是有限的 。而请求是可以在消息队列中被短暂地堆积, 当库存被消耗完之后,消息队列中堆积的请求就可以被丢弃了。**消息队列发展历程**言归正传,先看看有哪些主... Spark、Flink 等都支持与 Kafka 集成。* **RocketMQ** 是阿里开源的消息中间件,目前已经捐献个 Apache 基金会,它是由 Java 语言开发的,具备高吞吐量、高可用性、适合大规模分布式系统应用等特点,经历过双十一的洗...
EMR 存算分离JobCommitter最佳实践
可以显式调用AbortUpload丢弃某一次Upload写入的内容。 CompleteUpload: 当前Upload的所有UploadPart写入成功之后,会调用CompleteUpload将多次UploadPart的数据排序合并,并写入到key中。 借助MPU能力,可以避免文... Load 1TB tpc-ds数据开启TOS JobCommtiter可带来 70% 的性能提升; 在Hive On Tez场景下,Load 1TB tpc-ds 数据开启TOS JobCommitter 可带来 93% 的性能提升。 4 Spark TPC-DS测试关于Spark2.x及Spark3.x开启使用T...
