数据库中er图是怎么来的
 社区干货
社区干货
达梦@记一次国产数据库适配思考过程|社区征文
这里记录一下迁移过程中遇到的问题,**在迁移的时候,报某些字段超长**。于是,查看了MySql中那些字段的类型及长度,都是varchar(50) 。这里应该是迁移有些字段,须在DM数据库中增加位宽,在MySql中varchar是表示字符,va... 则会执行图三批量插入insertBatch方法。上例,这样我们就能极其简易的指定 databaseId,很多小伙伴肯定会说为什么需要这样去指定?其背后的原理又是怎样的,我们是否能够扩展并自定义 databaseId?框架这层的应用真能...
2022技术盘点之平台云原生架构演进之道|社区征文
下图为SmartOps架构全景: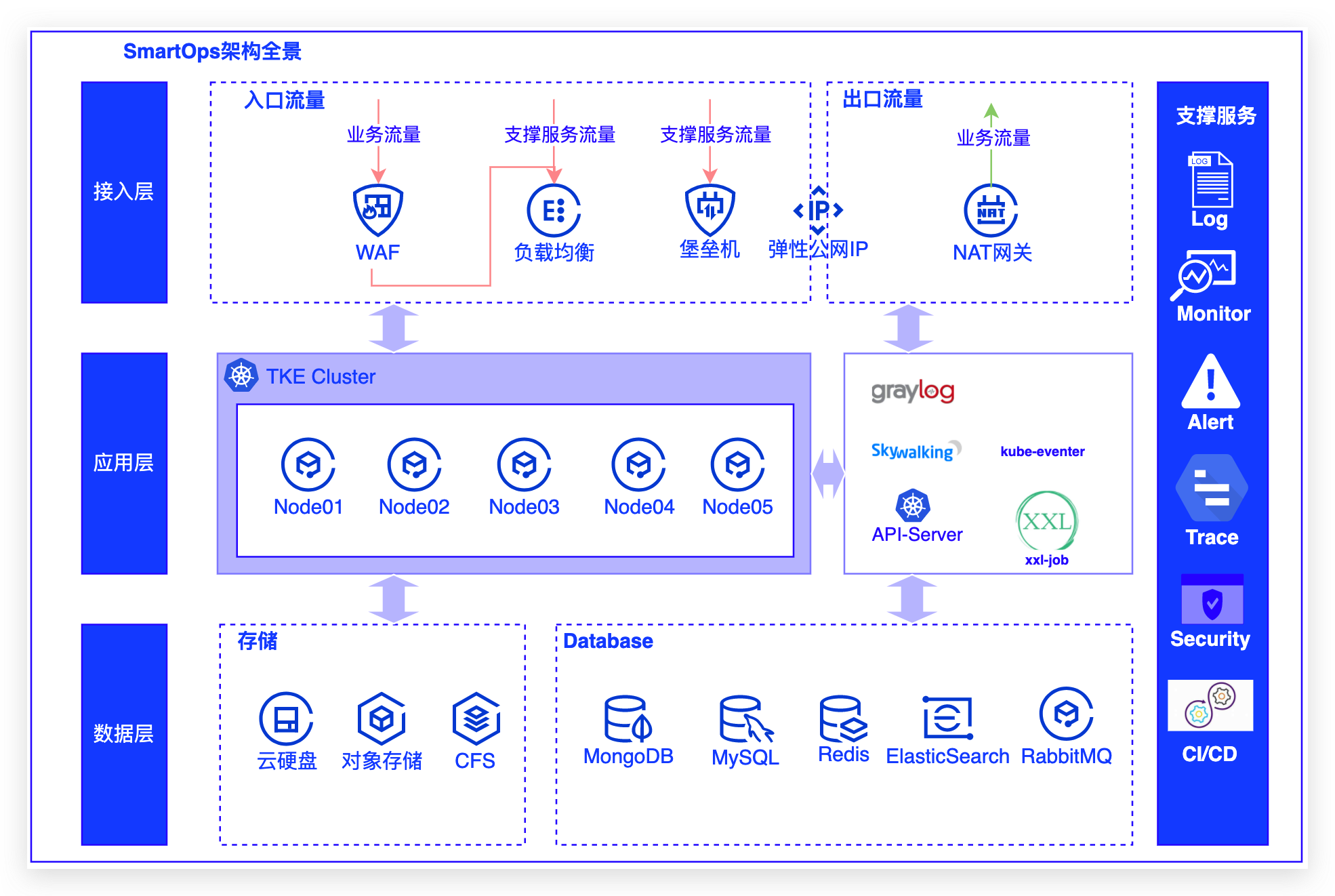- 接入层:通过WAF/SLB,配合NAT网关治理出方向流量,部署有堡垒机进行运维等其他辅助业务进行支撑;- 应用层:采用腾讯TKE进行业务容器部署,配合K8s原生服务注册发现/配置中心/分布式调度中心/日志/监控/告警/链路追踪/DevOps等构筑完整应用体系;- 数据层:存储使用有云硬盘/对象存储/CFS,数据库有Mon...
一文读懂火山引擎云数据库产品及选型
数据库系统在上世纪 70 年代初出现,至今已经发展了半个多世纪,其理论、技术与产品已经非常丰富,呈现出百花齐放的景象。根据其特点可以大概分为关系型数据库管理系统(RDBMS),非关系型数据库(NoSQL),NewSQL、云原生数据库、分布式数据库等等。每一类数据库中使用不同的技术实现,又可以分化出不同的产品类型。根据 DB-Engines 的统计,数据库产品数量已经有将近 400 种,数据库厂商也有几百家,如下图所示,不同数据库产品的实际应用规模...
未来向量数据库的崛起与多元化场景创新 主赛道 | 社区征文
**图像向量**:依据深度学习模型获得的图像特点向量捕捉图像的重要信息,如色彩、外型、线框等,可用作图像鉴别、检索等任务;**文本向量**:通过词嵌入技术如 Word2Vec、BERT 等生成的文本特征向量,这些向量包含了文... 向量数据库的优势?向量数据库与传统的关系型数据库有很大提升。传统的关系型数据库是基于表格的数据集合而向量数据库是基于向量的,它的数据是按照向量维度的一个个数据的集合。在向量数据库中,每个向量都有一个唯...
 特惠活动
特惠活动
 数据库中er图是怎么来的-优选内容
数据库中er图是怎么来的-优选内容
 数据库中er图是怎么来的-相关内容
数据库中er图是怎么来的-相关内容
观点|SparkSQL在企业级数仓建设的优势
支持标准JDBC接口访问的HiveServer2服务器,管理元数据服务的Hive Metastore,以及任务以MapReduce分布式任务运行在YARN上。标准的JDBC接口,标准的SQL服务器,分布式任务执行,以及元数据中心,这一系列组合让Hiv... 对于企业数仓架构来说,最重要的是如何基于企业业务流程来设计架构,而不是基于某个组件来扩展架构。 **文 |** **字节跳动数据平台数据湖团队** 字节跳动数据湖团队在实时数仓构建宽表的业务场景中,探索实践出的一种基于 H... 数据源一般包括 Kafka 中的指标数据,以及 KV 数据库中的维度数据。业务侧通常会基于实时计算引擎在流上做多个数据源的 JOIN 产出这个宽表,但这种解决方案在实践中面临较多挑战,主要可分为以下两种情况:## **1.1 ...
火山引擎 DataLeap:揭秘字节跳动数据血缘架构演进之路
血缘中涉及的元数据会冗余一份,并存储到图里。- 在血缘存储方面(见上图右边部分),除了图数据库之外,血缘本身也会依赖元数据的存储,如 Mysql 以及索引类存储。- 在血缘消费层面,第一版只支持通过 API 进行消费。**最后总结该版本的三个关键点:**- 血缘数据每天以离线方式**全量更新**。- 通过对比血缘快照来判断血缘更新操作,后面将为大家详细解答为什么要通过对比的方式。- 冗余一份元数据存储到图数据库中。...
[数据库系统] 业界列式存储浅析
# 简介众所周知,在数据库存储引擎侧通常有两类存储模型,行式存储NSM(N-ary Storage Model)和列式存储DSM(Decomposition Storage Model),两种存储模型各有其特定的擅长场景。在以前,主流存储设备是机械磁盘的情况... 但是在90s年到2000s年,列存的主要研究领域还是停留在怎么样打破内存墙,在2001年,Ailamaki等人提出了PAX(Partition Attributes Cross)【1】格式,开始研究怎么样结合列存的优势到行存中。2017年 google spanner 发表...
干货 | 以一次Data Catalog架构升级为例,聊聊业务系统的性能优化
是基于LinkedIn Wherehows进行二次改造,产品早期只支持Hive一种数据源。后续为了支持业务发展,做了很多修修补补的工作,系统的可维护性和扩展性变得不可忍受。比如为了支持数据血缘能力,引入了字节内部的图数据库ve... 实际工作中更多的是贴合业务场景做优化。比如用户直接访问前端界面的系统,通常不需要将响应时间优化到ms以下,几十毫秒和几百毫秒,已经是满足要求的了。**优化范围选择**对于一个业务类Web服务来说...
基于 Apache Calcite 的多引擎指标管理最佳实践|CommunityOverCode Asia 2023
接下来要介绍的统一 SQL 可以帮助你自动适应多引擎。第二个问题,你有纠结过 map 字段中有哪些 key 以及它的含义是什么吗?接下来要介绍的虚拟列语法可以让你不再纠结。第三个问题,你是如何复用相同的 case wh... 但是均满足不了字节跳动高速发展的业务需求。因为使用 UDF 的变更发布成本很高,Hive UDF 发布 Maven Jar、上传到 HDFS 非常麻烦;一次枚举所有城市,国内业务可以做到但会增加维护的 overhead,且国际化业务不可能办到...
