数据库中er图是什么概念
 社区干货
社区干货
2022技术盘点之平台云原生架构演进之道|社区征文
下图为SmartOps架构全景: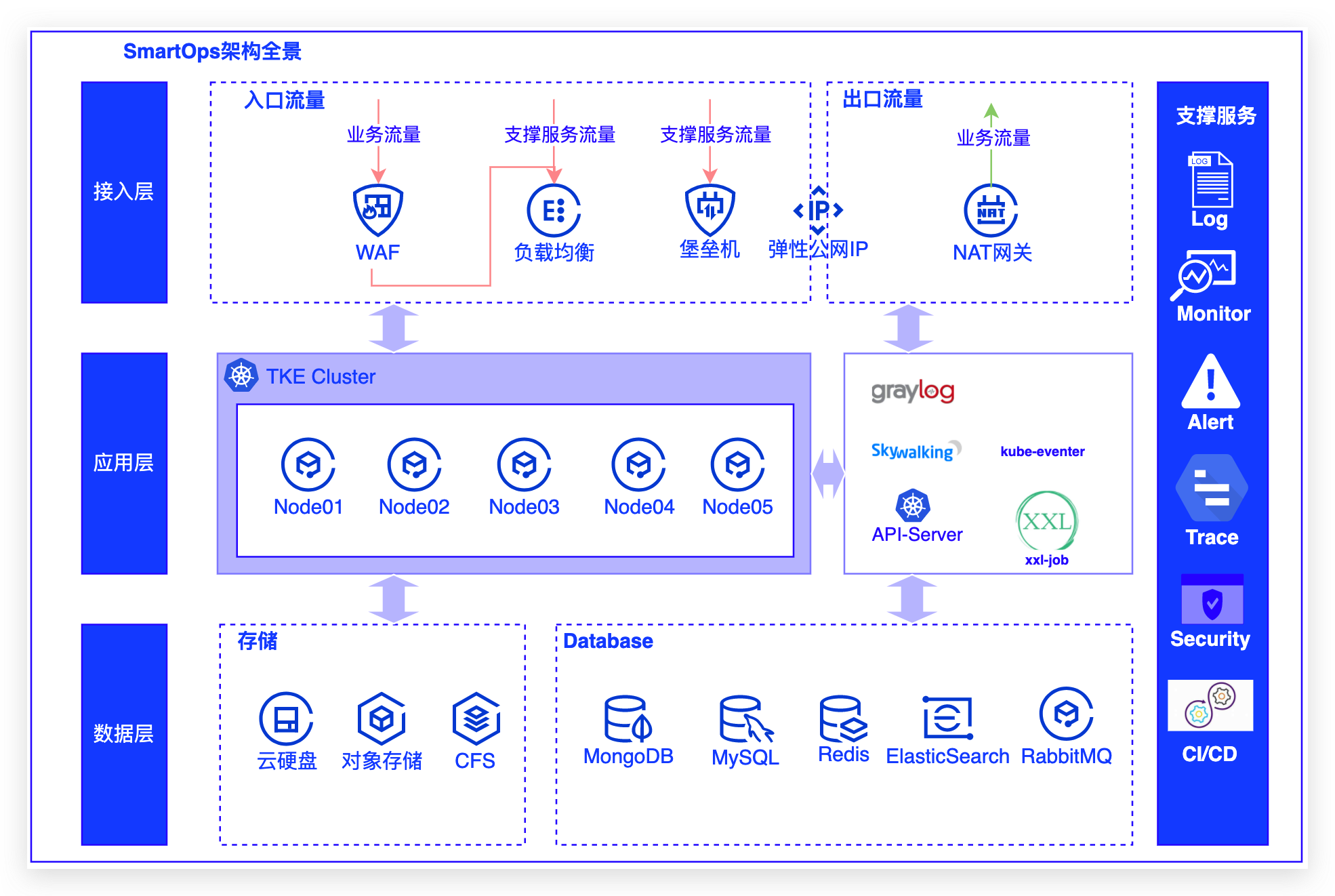- 接入层:通过WAF/SLB,配合NAT网关治理出方向流量,部署有堡垒机进行运维等其他辅助业务进行支撑;- 应用层:采用腾讯TKE进行业务容器部署,配合K8s原生服务注册发现/配置中心/分布式调度中心/日志/监控/告警/链路追踪/DevOps等构筑完整应用体系;- 数据层:存储使用有云硬盘/对象存储/CFS,数据库有Mon...
Hive SQL 底层执行过程 | 社区征文
DRIVER:驱动程序。接收查询的组件。该组件实现了会话句柄的概念。3. COMPILER:编译器。负责将 SQL 转化为平台可执行的执行计划。对不同的查询块和查询表达式进行语义分析,并最终借助表和从 metastore 查找的分区元数据来生成执行计划。4. METASTORE:元数据库。存储 Hive 中各种表和分区的所有结构信息。5. EXECUTION ENGINE:执行引擎。负责提交 COMPILER 阶段编译好的执行计划到不同的平台上。上图的基本流程是:**步骤...
[数据库系统] 业界列式存储浅析
# 简介众所周知,在数据库存储引擎侧通常有两类存储模型,行式存储NSM(N-ary Storage Model)和列式存储DSM(Decomposition Storage Model),两种存储模型各有其特定的擅长场景。在以前,主流存储设备是机械磁盘的情况... 每insert/update/delete 一行数据,由于会去更新存在在不同位置的column,会带来IO放大,且为随机IO。# 发展其实在1983年列存概念就在Cantor论文【11】中提出了,85年Copeland and Khoshafian在SIGMOD上首次提出了...
字节跳动基于 Apache Hudi 的多流拼接实践
=&rk3s=8031ce6d&x-expires=1714407613&x-signature=WtW0fEKj487%2Bjo2ErUb6MV8SVWo%3D)**文 |** **字节跳动数据平台数据湖团队** 字节跳动数据湖团队在实时数仓构建宽表的业务场景中,探索实践出的一种基于 H... 数据源一般包括 Kafka 中的指标数据,以及 KV 数据库中的维度数据。业务侧通常会基于实时计算引擎在流上做多个数据源的 JOIN 产出这个宽表,但这种解决方案在实践中面临较多挑战,主要可分为以下两种情况:## **1.1 ...
 特惠活动
特惠活动
 数据库中er图是什么概念-优选内容
数据库中er图是什么概念-优选内容
 数据库中er图是什么概念-相关内容
数据库中er图是什么概念-相关内容
火山引擎云搜索服务升级云原生新架构;提供数十亿级分布式向量数据库能力
而伴随着 Serverless 的兴起和大势所向,火山引擎**云搜索服务** **升级** **云原生** **新架构**。 ## 云搜索服务云原生版 ## k-NN,大模型时代下的原生向量搜索和数据库随着...
浅谈大数据建模的主要技术:维度建模 | 社区征文
还是基于传统 MPP 架构的数据仓库(如Teradata ),抑或是基于传统 Oracle 、MySQL 、MS SQL Server 关系型数据库的数据仓库,其实都面临如下问题:- 怎么组织数据仓库中的数据?- 怎么组织才能使得数据的使用最为方便... 熟客量就是度量。**但是,单单谈论度量,是没有意义的。度量和环境这两个概念构成了维度建模的基础。而所有维度建模也正是通过对度量和及其上下文和环境的详细设计来实现的。### 事实和维度在 Kimball 的维度...
干货|解析云原生数仓ByteHouse如何构建高性能向量检索技术
**本篇将结合ByteHouse团队对向量数据库行业和技术的前沿观察,详细解读OLAP引擎如何建设高性能的向量检索能力** ,并最终通过开源软件VectorDBBench测试工具,在 cohere 1M 标准测试数据集上,recall 98 的情况下,Q... **/ 向量检索定义****/**对于诸如图片、视频、音频等非结构化数据,传统数据库方式无法进行处理。目前,通用的技术是把非结构化数据通过一系列 Embedding 模型将它变成向量化表示,然后将它们存储到数据库或者...
以 100GB SSB 性能测试为例,通过 ByteHouse 云数仓开启你的数据分析之路
是由麻省州立大学波士顿校区的研究员定义的基于现实商业应用的数据模型。SSB 是在 TPC-H 标准的基础上改进而成,主要将 TPC-H 中的雪花模型改成了更为通用的的星型模型,将基准查询从复杂的 Ad-hoc 查询改成了结构更... 可以看到数据库表管理、数据加载、SQL 工作表、计算组、查询历史和角色管理等几大模块。分别具有如下作用:- 数据库表管理:用于创建和管理数据库、数据表以及视图等数据对象- 数据加载:用于从不同的离线和实...
基于 Apache Calcite 的多引擎指标管理最佳实践|CommunityOverCode Asia 2023
你有注意过 Spark 和 Presto 中同义但不同名的函数吗,比如 instr 和 strpos?接下来要介绍的统一 SQL 可以帮助你自动适应多引擎。第二个问题,你有纠结过 map 字段中有哪些 key 以及它的含义是什么吗?接下来要介绍... 如下图所示,点击率等于点击数除以曝光数,但业务通常会将点击数、曝光数这两个指标定义为 int,这就会导致使用 Presto 计算时查出 int 结果,而使用 Hive 则会查出一个 double 结果。,数据湖(Data Lake),信创自主可控,互联互通,数字化建设...... 这些概念越来越火热,前些时候大部分工作集中在信创自主可控,现阶段已告一段落。信息化,数字化建设也是不可或缺的一环,遇到挑战... 数据规模也需考虑集中存储。 ## 猜想是否能够在数据库中,通过一系列高级分析算法,对数据进行分析与处理? ## 预期成熟的海量数据解决方案 **1、** 生态圈丰富,成功案例较多,开源; **2、...
干货 | 基于ClickHouse的复杂查询实现与优化
作为该领域中的后起之秀,ClickHouse已凭借其性能优势引领了业内新一轮分析型数据库的热潮。但随着企业业务数据量的不断扩大,在复杂query场景下,ClickHouse容易存在查询异常问题,影响业务正常推进。> > > > > ... **第一种是依赖调度,**根据Stage依赖关系定义拓扑结构,产生DAG图,并根据DAG图调度Stage。依赖调度要等到依赖Stage启动以后,才会调度对应的Stage。例如两表Join,会先调度左右表读取Stage,之后再调度Join这个Stage,...
业务中台数据一致性方案|社区征文
事务的概念对于程序猿来说一定不陌生,这里的事务指的是数据库事务。所谓数据库事务,简单来理解就是一套关于数据一致性维护的数据库机制。 我们都知道,实际业务平台大部分的业务数据还是保存在关系型数据库中,在单体... 我们先来看下什么是 CAP 理论以及 BASE 理论。**CAP 理论**Consistency:数据一致性Avalibility:数据可用性Partition tolerance:分区容错性