图数据库用于存储节点
 社区干货
社区干货
[数据库系统] 业界列式存储浅析
# 简介众所周知,在数据库存储引擎侧通常有两类存储模型,行式存储NSM(N-ary Storage Model)和列式存储DSM(Decomposition Storage Model),两种存储模型各有其特定的擅长场景。在以前,主流存储设备是机械磁盘的情况... C-Store的administrator可以选择性的指定数据库表必须是k-safe的。指定后,任意K个节点失效时仍然允许所有表能成功重建出来。、边(Edge)以及其上附着的属性** ;作为一个工具,图数据对外提供的接口都是围绕这些元素展开。**图数据库本质也是一个存储系统**,它和常见...
字节跳动数据库的过去、现状与未来
如下图所示,在这 4 年间,公司应用侧容器数量从 5 万个增长到了 750 万个,截至目前已经突破 **1000 万** 。这 1000 万个容器筑成了字节跳动坚实的云原生基础设施,支撑着整个业务体系的发展。从在线数据角度看,1000 万个容器构成了超过 10 万个微服务,这些微服务在线上运行期间会产生大量数据。在 2020 年,字节跳动的在线数据量级达到 EB 级;到 2021 年 5 月份,字节跳动数据库团队已支撑超过 **10 EB** 的存储规模。 特惠活动
特惠活动
 图数据库用于存储节点-优选内容
图数据库用于存储节点-优选内容
 图数据库用于存储节点-相关内容
图数据库用于存储节点-相关内容
火山引擎ByteHouse:分析型数据库如何设计列式存储
也采用列式存储设计,保证读写性能、支持事务一致性,又适用大规模的数据计算,为用户提供极速分析体验和海量数据处理能力,提升企业数字化转型能力。# 列式存储介绍分析型数据库中的列式存储,是一种数据库的物理存... 存储允许独立地更新表中的列,这使得增量更新和数据维护变得更加简单和高效。1. **数据分片和分布式处理**: 由于列式存储的特性,它非常适合于分布式计算环境。数据可以按列进行分片,并分布到不同的计算节点上进行...
stateless emr 支持计算存储分离;但 clickhouse、doris 都是存储计算一体的olap数据库;所以存储计算分离和不分离的利弊有哪些,选型时有什么关键的考量吗
stateless emr 支持计算存储分离;但 clickhouse、doris 都是存储计算一体的olap数据库;所以存储计算分离和不分离的利弊有哪些,选型时有什么关键的考量吗
抖音春晚幕后|支撑 12 亿红包雨的云原生基础设施
给后端数据库造成了巨大压力。为了确保活动的平滑顺畅不宕机,火山引擎采用 **自研架构的 Redis 系统**提供缓存服务:通过集中化元数据存储,实现了节点和集群性能的海量扩展;通过异步和多线程 IO 优化,将热点数据... **自研分布式图数据库系统** **ByteGraph** 用在了生产环境。在红包活动中,相比常见的 KV 存储系统和 MySQL 存储系统,图数据库在应对春晚千万级并发查询方面有更大的性能优势和更简洁高效的接口。而 ByteGra...
火山引擎 DataLeap:揭秘字节跳动数据血缘架构演进之路
冗余一份元数据存储到图数据库中。### 存储模型图中上半部分为**表级血缘**,只包括一种类型节点,即表节点,比如 Hive 表、 ClickHouse 表等。图中下半部分为**字段血缘**,第一版...
未来向量数据库的崛起与多元化场景创新 主赛道 | 社区征文
# 向量数据库的崛起与多元化场景创新## 前言:> 在如今的数字时代,数据被称作金子,对企业、科学家和管理者都有很大价值。但是,随着数据规模的不断增长,高效的管理、存储和检索数据变得越来越复杂。这引进了当今... 用于存储、检索和查询大规模的高维数据。它以多维向量的形式保存信息。根据数据的复杂性和细节,每个向量的维数变化很大,从几个到几千个不等。这些数据可能包括文本、图像、音频和视频,使用各种过程(如机器学习模型...
火山引擎 DataLeap 套件下构建数据目录(Data Catalog)系统的实践
存储依赖重,同时使用了MySQL、ElasticSearch、图数据库等系统存储元数据,维护成本很高;接入一种元数据会增加2~3个ETL任务,运维成本直线上升## 新版本目标基于上述痛点,火山引擎 DataLeap 研发人员重新设计实现... 选用的不同的存储:- Meta Store:存放全量元数据和血缘关系,当前使用的是HBase- Index Store:存放用于加速查询,支持全文索引等场景的索引,当前使用的是ElasticSearch- Model Store:存放推荐、打标等的算法...
什么是云数据库 veDB MySQL 版
云数据库 veDB MySQL 版是火山引擎自研新一代云原生关系型数据库。云数据库 veDB MySQL 版 100% 兼容 MySQL,适用于企业多样化的数据库应用场景。 产品介绍云数据库 veDB MySQL 版采用计算存储分离架构,最多支持 128TiB 的超大容量结构化数据存储,单个数据库集群最多可扩展至 16 个计算节点。基于云原生数据库设计理念,云数据库 veDB MySQL 版既融合了商业数据库高性能、高可靠、高可用的特征,又具有开源数据库简单开放、快速迭代...
分布式数据库在抖音春晚活动中的应用
用户需要根据业务架构去选择数据库的架构。我们顺着 Shared-Storage 这个方向继续往下深入看,下图是一个简要的 Shared-Storage 架构的分布式数据库架构图。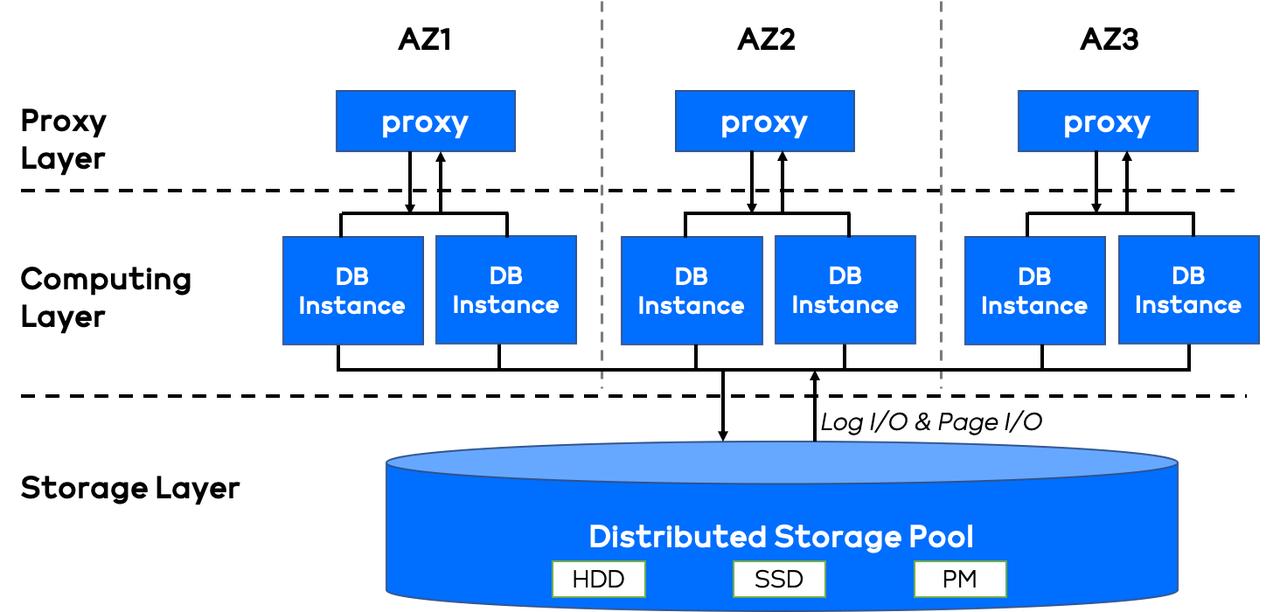可以看到,我们的系统分为三个层次:- 最上面是代理层;- 中间是计算层;- 最底层是分布式存储层。可以看到三层之间各个节点是...
VikingDB:大规模云原生向量数据库的前沿实践与应用
由于向量数据库能够高效存储和检索模型生成的向量,从而提供语义上更具有相关性的检索结果,因此向量数据库成了 ES 之外的 RAG 必不可少的检索工具,RAG 也成为了向量数据库最为重要的应用场景。简而言之, **向量库数... GPU 索引加速主要应用于同时对精度和延时都有极端需求,数据量又没那么大的场景。第四张图:SEF、M 是 HNSW 索引的两个参数,SEF 是搜索时 entry points 的长度,M 是索引图中每个点的邻居节点个数。这两个参数值越...
