图数据库用什么语言
 社区干货
社区干货
字节跳动自研万亿级图数据库 & 图计算实践
语言** ,支持 **灵活丰富的写入和查询接口** , **读写吞吐可扩展到千万 QPS** , **延迟毫秒级** 。目前,ByteGraph 支持了头条、抖音、西瓜、火山等几乎字节跳动全部产品线,遍布全球机房。ByteGraph 主要用于在线 OLTP 场景,而在离线场景下,图数据的分析和计算需求也逐渐显现。在这篇文章中,将从 ByteGraph 的适用场景、内部架构、关键问题分析几个方面作深入介绍,并将介绍图计算相关实践。 自研图数据库(Byte...
2022技术盘点之平台云原生架构演进之道|社区征文
下图为SmartOps架构全景: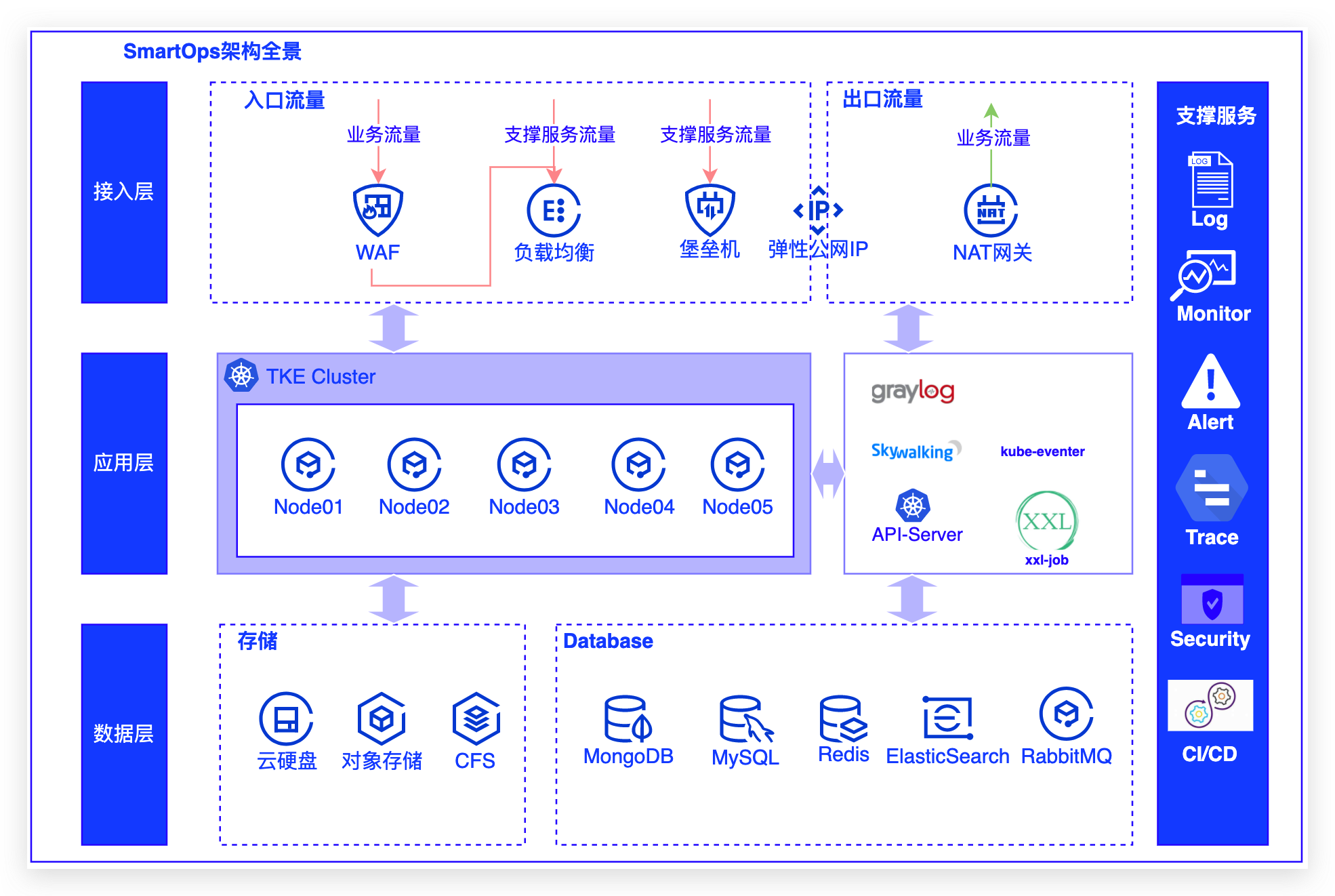- 接入层:通过WAF/SLB,配合NAT网关治理出方向流量,部署有堡垒机进行运维等其他辅助业务进行支撑;- 应用层:采用腾讯TKE进行业务容器部署,配合K8s原生服务注册发现/配置中心/分布式调度中心/日志/监控/告警/链路追踪/DevOps等构筑完整应用体系;- 数据层:存储使用有云硬盘/对象存储/CFS,数据库有Mon...
字节跳动 NoSQL 的探索与实践
用户和内容的连接:用户发布内容之后的评论、点赞、转发等,自媒体还会关注广告点击及分成收益等数据。这三种数据关联到一起就会形成图状结构。### 自研分布式图数据库为了满足内部 social graph 在线增删改查的场景,字节跳动自研了分布式图存储数据库 ByteGraph。针对刚才提到的图状数据结构,ByteGraph 支持有向属性的图数据模型、Gremlin 查询语言以及丰富的写入和查询接口,具有海量存储和吞吐能力,单体集群可达万亿条...
字节跳动 NoSQL 的探索与实践
用户之间的关系:比如关注好友等;- 内容:视频、文章、广告等;- 用户和内容的连接:用户发布内容之后的评论、点赞、转发等,自媒体还会关注广告点击及分成收益等数据。这三种数据关联到一起就会形成图状结构。### 自研分布式图数据库为了满足内部 social graph 在线增删改查的场景,字节跳动自研了分布式图存储数据库 ByteGraph。针对刚才提到的图状数据结构,ByteGraph 支持有向属性的图数据模型、Gremlin 查询语言以及丰富...
 特惠活动
特惠活动
 图数据库用什么语言-优选内容
图数据库用什么语言-优选内容
 图数据库用什么语言-相关内容
图数据库用什么语言-相关内容
新功能发布记录
需要检查目标数据库的 ReadyOnly 配置是否满足迁移或同步要求。 2024-03-20 全部 预检查项(MySQL) 支持 Avro 订阅格式 (邀测)数据库传输服务 DTS 支持使用 Avro 格式进行信息投递。 2024-03-20 全部 数据订阅格式 订阅方案概览 CreateTransmissionTask 支持 Go SDK 数据库传输服务 DTS 新增支持 Go 语言的 SDK,让 Go 开发者能调用 API 接口管理 DTS 任务。 2024-03-18 全部 SDK 概述 2023 年 12 月功能名称 功能...
字节跳动 NoSQL 的探索与实践
用户和内容的连接:用户发布内容之后的评论、点赞、转发等,自媒体还会关注广告点击及分成收益等数据。这三种数据关联到一起就会形成图状结构。### 自研分布式图数据库为了满足内部 social graph 在线增删改查的场景,字节跳动自研了分布式图存储数据库 ByteGraph。针对刚才提到的图状数据结构,ByteGraph 支持有向属性的图数据模型、Gremlin 查询语言以及丰富的写入和查询接口,具有海量存储和吞吐能力,单体集群可达万亿条...
字节跳动 NoSQL 的探索与实践
用户之间的关系:比如关注好友等;- 内容:视频、文章、广告等;- 用户和内容的连接:用户发布内容之后的评论、点赞、转发等,自媒体还会关注广告点击及分成收益等数据。这三种数据关联到一起就会形成图状结构。### 自研分布式图数据库为了满足内部 social graph 在线增删改查的场景,字节跳动自研了分布式图存储数据库 ByteGraph。针对刚才提到的图状数据结构,ByteGraph 支持有向属性的图数据模型、Gremlin 查询语言以及丰富...
抖音大规模实践,火山引擎向量数据库是这样炼成的
在数据库中存储和对比的并不是图片和视频片段,而是通过深度学习等算法将其提取出来的“特征”,“特征”提取的过程称为 Embedding,提取出的“特征”用数学中的向量来表示。向量化的目的是为了通过向量相似来进行非结构化数据的检索,向量化后的数据才能够被 AI 模型更好的理解使用。 **向量数据库就是用于生产、存储、索引和分析来自机器学习模型产生的海量向量数据的数据库系统** 。其典型应用场景比如:基于大语言模型的智能客服...
抖音大规模实践,火山引擎向量数据库是这样炼成的
在数据库中存储和对比的并不是图片和视频片段,而是通过深度学习等算法将其提取出来的“特征”,“特征”提取的过程称为 Embedding,提取出的“特征”用数学中的向量来表示。向量化的目的是为了通过向量相似来进行非结构化数据的检索,向量化后的数据才能够被AI模型更好的理解使用。向量数据库就是用于生产、存储、索引和分析来自机器学习模型产生的海量向量数据的数据库系统。其典型应用场景比如:基于大语言模型的智能客服、基于企业...
[数据库系统] 业界列式存储浅析
# 简介众所周知,在数据库存储引擎侧通常有两类存储模型,行式存储NSM(N-ary Storage Model)和列式存储DSM(Decomposition Storage Model),两种存储模型各有其特定的擅长场景。在以前,主流存储设备是机械磁盘的情况... 数据排列结构如下图所示: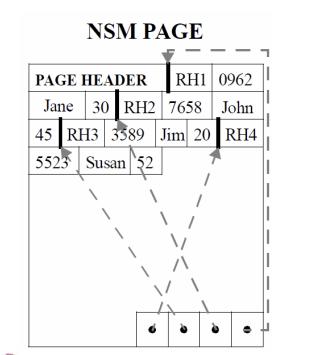列存和行存的区别主要是在存储时将多行数据的相同colum...
字节跳动 NoSQL 的探索与实践
这三种数据关联到一起就会形成 **图状结构** 。**自研分布式图数据库**为了满足内部 social graph 在线增删改查的场景,字节跳动自研了 **分布式图存储数据库 ByteGraph** 。针对刚才提到的图状数据结构,ByteGraph 支持有向属性的图数据模型、Gremlin 查询语言以及丰富的写入和查询接口,具有海量存储和吞吐能力,单体集群可达万亿条边,支持百万 QPS 图上多度读写。ByteGraph 也支持 Super Node 热点访问,单个过亿出度节点...
VikingDB:大规模云原生向量数据库的前沿实践与应用
VikingDB 在字节内部的应用向量数据库近来的火热来源于大语言模型的兴起,但在大模型兴起之前,VikingDB 已经在字节内部广泛应用,最初应用在推荐、广告、搜索的召回环节,后来逐步扩展到了消重、风控、对话、文档搜... 第二张图为量化方式的对比。量化本质上也是一种压缩,压缩就会带来精度的损失。压缩最彻底的是 Int8,对应的精度也最差,VikingDB 能做到 **精度损失在 3% 以内** 。第三张图中所示使用 GPU 加速的情况是个特例,由...
应用场景
智能问答 LLM(Large Language Models,大规模语言模型)支持的智能客服、领域知识问答。 知识库 将业务知识进行解析、切块、理解,文本向量化后存储到向量数据库 VikingDB,利用向量相似度检索技术,实现高效的知识库检索,从而提升知识库的利用和管理效果。 智能搜索 文本检索、图片搜索、音视频相似性检索。文本检索、语义检索:NLP(Natural Language Processing,自然语言处理)模型将文本转换为向量,这些模型试图表示单词的场景及其所...
