应用Gpytorch将内核应用于不同的维度
 社区干货
社区干货
AI安全技术总结与展望| 社区征文
其中人工智能应用于安全行业如利用人工智能技术识别恶意代码、自动化漏洞扫描、自动化构建鱼叉钓鱼邮件、锁定目标、生成高逼真度的假视频等。人工智能内生安全主要包括:框架安全,如TensorFlow、Caffe、PyTorch等深... 机器学习还能对不同的数据进行分类,在更细粒度上识别风险,保护数据的安全。 近来来,人工智能技术逐渐应用于各个安全产品,如SIEM、SOCK、SORA,通过分析平台日志,可构建异常检测模型、自动化编排响应。近年来,“...
Katalyst Memory Advisor:用户态的 K8s 内存管理方案
内存回收根据针对的目标不同,可以分为针对 Memcg 的和针对 Zone 的。内核原生的内存回收方式包含以下几种:* **Memcg 直接内存回收:** 如果一个 Cgroup 的 Memory Usage 达到阈值,则会触发 Memcg 级别的同步内存... memory.high 中配置的 Throttle 阈值可能不生效。2. 按照上述方式计算出的 memory.high 可能较低,导致频繁的 Throttle,影响业务性能。3. throttlingfactor 的默认值 0.8 过于激进,一些 Java 应用通常会用到 85% ...
从混合部署到融合调度:字节跳动容器调度技术演进之路
=&rk3s=8031ce6d&x-expires=1716049262&x-signature=4Xmobd0TkURUmk7Kp5ZUnuvuI1k%3D)**2016 年:启动****自研云引擎(TCE 平台)建设**。它早期的定位是为内部应用提供快捷高效的服务部署方案,专注于服务的生... 我们向上提供各种维度、资源类型的弹性资源抽象,推动业务由云原生化改造朝着面向云设计业务的方向演进,让业务在设计架构时,能够天然感知底层的多个维度、多种 QoS 类型的资源,实现 Service 化落地;另一方面,我...
QCon高分演讲:火山引擎容器技术在边缘计算场景下的应用实践与探索
广东电信的客户需要1000个几核几GB的算力资源,我们就可以进行快速交付,而不需要客户去针对于广东电信100个边缘节点逐个去开通,我们可以达到快速交付能力。**全生命周期管理**很多客户,特别一些创新性场景,从中心下沉边缘,或者某些新业务场景是没有针对边缘场景去部署和运维的能力的。因为边缘机房太多了,节点也会面临裁撤、下线。所以说火山引擎边缘容器会屏蔽这些差异,给客户统一提供像边缘应用的部署、版本的管理,包括一些...
 特惠活动
特惠活动
 应用Gpytorch将内核应用于不同的维度-优选内容
应用Gpytorch将内核应用于不同的维度-优选内容
 应用Gpytorch将内核应用于不同的维度-相关内容
应用Gpytorch将内核应用于不同的维度-相关内容
字节跳动端智能工程链路 Pitaya 的架构设计
**AI 的端侧应用**逐步从零星的探索走向**规模化应用**。行业里,FAANG、BATZ 都有众多落地场景,或是开创了新的交互体验,或是提升了商业智能的效率。**Client AI**是字节跳动产研架构下属的端智能团队,负责端智能... 可以将多种**数据源**(HDFS / Hive / Kafka / MySQL)和多种**机器学习引擎**(TensorFlow, PyTorch, XGBoost, LightGBM, SparkML, Scikit-Learn)连接起来。同时MLX Notebook还在标准SQL的基础上拓展了**MLSQL** **算...
火山引擎谭待:数据驱动x敏捷开发,业务高速增长的双引擎
面向不同用户群体运营的优化等; 客观的分析评估,一方面通过A/B测试,对不同的、新的迭代进行客观评估,另一方面则是通过ABI进一步地进行数据洞察,能够积累对于的insights,从而促进整个流程的转动。 这就是字节跳动构建整个数据驱动飞轮的过程,在这个过程中,我们把“业务过程数字化”、“数字化协同”、“客观的分析评估”这三个沉淀下来,固化成数据中台统一的能力,去支持不同应用的数据优化,同时中台能力,还能对业务不同维度,包括增...
一位老IT的2023年的技术总结 |社区征文
将集成较多的数据集,主要与业务系统联通或者其它设备的数据汲取过来,通过清洗、整合、编排后,输出一个错落有致、规范得体的数据指标。数据大屏、业务监控管理、用户画像都属于大数据系统的建设方案范围,主要它是能整合不同的数据, 一般采用维度模型建模的方式。**智能系统建设方案:** 该系统建设属于高端信息应用范畴,需要智能算法以及更有效率的计算框架,包括**音视频、** **边缘计算** **、AI、** **大模型**、 **AIGC**等等...
数据中台的学习与总结 主赛道 | 社区征文
评价反馈等多维度的数据,并进行清洗、整合、标准化等预处理。- 数据分析:通过 Spark、Hadoop 等分布式计算框架,对海量数据进行实时或离线的分析处理,提取用户画像、商品特征、评价情感等有价值的信息,并进行可视化展示。- 数据建模:通过 TensorFlow、PyTorch 等深度学习框架,构建基于卷积神经网络(CNN)、循环神经网络(RNN)、长长短期记忆网络(LSTM)等模型,实现对用户行为和商品属性之间关系的建模,并进行训练和测试。- ...
Katalyst:字节跳动云原生成本优化实践
即使增加缓冲区仍有很多资源处于业务已申请但未使用的状态。因此优化重点是从架构的角度尽可能地利用这些未使用的资源。### 资源治理方案字节内部尝试过若干不同类型的资源治理方案...
字节跳动 EB 级 Iceberg 数据湖的机器学习应用与优化
**相关产品**:https://www.volcengine.com/product/flink # 机器学习样本存储:背景与趋势在字节跳动,机器学习模型的应用范围非常广泛。为了支持模型的训练,我们建立了两大训练平台:推荐广告训练平台和通用的... 以及传统的 PyTorch 和 TensorFlow 等,用户可以根据需求选择适合的计算、训练框架。第二层即猛犸湖的**核心层**。对外为用户提供了 SDK 自助和元数据服务,平台能力上支持多种运维作业,如数据导入、维护等任务。值...
Katalyst Memory Advisor:用户态的 K8s 内存管理方案
该操作会将所有的 Zone 都扫描一遍,比较耗时。如果还不成功,则会触发整机 OOM 释放一些内存,再尝试进行快速内存分配。### 内存回收内存回收根据针对的目标不同,可以分为针对 Memcg 的和针对 Zone 的。内核原生... `memory.high` 中配置的 Throttle 阈值可能不生效。1. 按照上述方式计算出的 `memory.high` 可能较低,导致频繁的 Throttle,影响业务性能。1. `throttling factor` 的默认值 0.8 过于激进,一些 Java 应用通常会...
操作系统相关(Linux)
VNC无法使用root登录 如何排查ECS Linux实例因为资源过度使用而失去响应的问题 如何解决卸载Linux镜像的gcc导致Virtio驱动被删除的问题 如何规避由于操作系统内核版本过低,通用型(g3a/g3i)/计算型(c3a/c3i)/内存... gePages 如何在CentOS系统中编译src.rpm源码包 Ubuntu 20.04如何安装使用python2-paramiko库 如何解决下载Pytorch速度慢且出现read timeout报错的问题 如何为 CentOS 7 系统的 ECS 实例配置默认防火墙 Firewall 如...
浅谈AI机器学习及实践总结 | 社区征文
如何基于环境而做出行动反应,以获得最大化的累积奖励。其与监督学习的差异在于监督学习是从数据中进行学习,而强化学习是从环境给他的奖惩中学习。Q-learning,SARSA,深度强化网络、蒙特卡洛学习...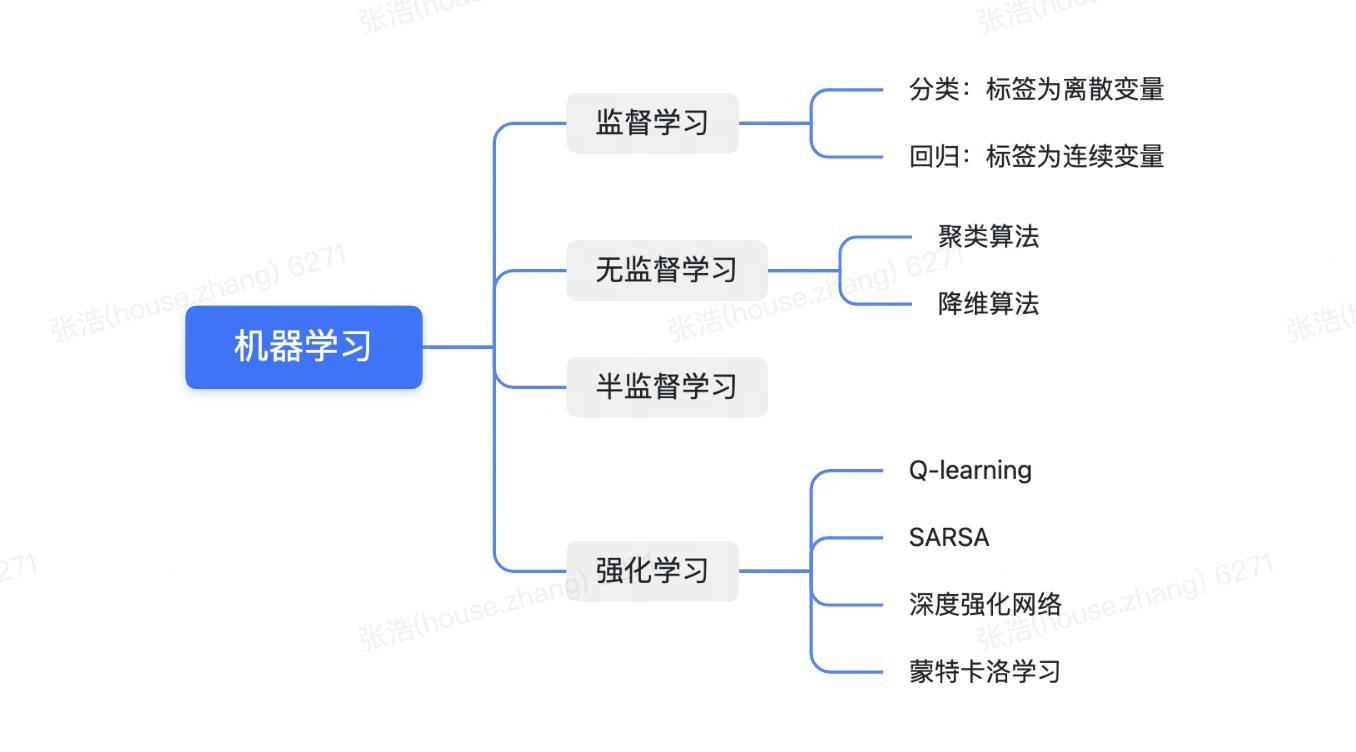## 如何理解深度学习常说的深度学习是一种使用深层神经网络的模型,可以应用于上述四类机器学...
