统一视图到稍微不同的结构
 社区干货
社区干货
年终学习大礼包|云原生大数据知识地图
**云原生大数据**是大数据平台新一代架构和运行形态,是一种以平台云原生化部署、计算云原生调度、存储统一负载为特点,可以支持多种计算负载,计算调度更弹性,存储效能更高的大数据处理和分析平台。云原生大数据带来... 资源池可以承载不同类型的大数据集群,可以装 Flink 集群,也可以装 Spark 集群,而且这些集群都是按需拉起的,可以迅速回收,在不需要时可以释放掉。- **统一部署和运维安装**:原来的运维方式是每个集群要运维每个自...
年终学习大礼包|云原生大数据知识地图
是大数据平台新一代架构和运行形态,是一种以平台云原生化部署、计算云原生调度、存储统一负载为特点,可以支持多种计算负载,计算调度更弹性,存储效能更高的大数据处理和分析平台。云原生大数据带来了大数据在使用和... 资源池可以承载不同类型的大数据集群,可以装 Flink 集群,也可以装 Spark 集群,而且这些集群都是按需拉起的,可以迅速回收,在不需要时可以释放掉。* **统一部署和运维安装**:原来的运维方式是每个集群要运维每个自...
LAS Spark+云原生:数据分析全新解决方案
> 更多技术交流、求职机会,欢迎关注字节跳动数据平台微信公众号,回复【1】进入官方交流群随着数据规模的迅速增长和数据处理需求的不断演进,云原生架构和湖仓分析成为了现代数据处理的重要趋势。在这个数字化时代... 提供统一的视图和跨地域的数据访问能力。以及提供了对源数据请求的路由能力,可以根据元数据请求的类型,支持通过 Mapping 的方式,来路由不同的服务请求对应的底层元数据服务实例。第二层是 CatalogService 下层的...
9年演进史:字节跳动 10EB 级大数据存储实战
我们需要非常多的 NameNode 实现联邦机制来接入不同上层业务的数据服务。但当 NameNode 数量也变得非常多了以后,用户请求的统一接入及统一视图的管理也会有很大的问题。为了解决用户接入过于分散,我们需要一个独立... 每个副本都存在不同的 Data Node 上,以达到容错容灾的效果。每个副本在 Data Node 上都以文件的形式存储,元信息在启动时被加载到内存中。Data Node 会定时向 Name Node 做心跳汇报,并且周期性将自己所存储的副本...
 特惠活动
特惠活动
 统一视图到稍微不同的结构-优选内容
统一视图到稍微不同的结构-优选内容
 统一视图到稍微不同的结构-相关内容
统一视图到稍微不同的结构-相关内容
干货|ClickHouse进阶:性能提升20倍!深度解析Projection优化实践
**ClickHouse Projection是针对物化视图现有问题,在查询匹配,数据一致性上扩展了使用场景:** **●**支持normal projection,按照不同列进行数据重排,对于不同条件快速过滤数据**●**支持aggregat... 优化器会将查询切分为不同的plan segment分发到worker节点并行执行,segment之间通过exchange交换数据,在plan segment内部根据query plan 构建pipeline执行,以下面简单聚合查询为例,说明优化器如何匹配projection。...
干货|字节跳动数据湖技术选型的思考
在计算引擎上做到了流批统一。到了2021年,我们基于Flink构造了实时数据湖集成通道,从而完成了湖仓一体的数据集成系统的构建。字节跳动数据集成系统目前支持了几十条不同的数据...
字节跳动湖平台在批计算和特征场景的实践
是面向火山引擎和专有云场景下的大数据统一存储服务,支持高性能的缓存和带宽加速,提供兼容 HDFS API 的访问接口。* 最底层的实际物理存储,可以选择对象存储,比如 AWS S3,火山引擎的 TOS,或者可以直接使用 HDFS。... 结构:* Iceberg Catalog:保存表和存储路径的映射关系,其核心信息是保存 Version 文件所在的目录。+ Iceberg Catalog 共有8种实现方式,包括 HadoopCatalog,HiveCatalog,JDBCCatalog,RestCatalog 等+ 不同的实...
ByteHouse:基于ClickHouse的实时数仓能力升级解读
不同的业务线及产品背后,其实是有着大量的中台在进行支持。以抖音和今日头条为例,从内容运营的角度,核心逻辑是怎么样把优质的内容生产出来,准确地分发到不同的用户并且及时的收到反馈,以此来不断形成一个迭代闭环。... 基于已有架构,ClickHouse可以实现非常好的非侵入式部署,不管是前面是大数据平台数据湖,后面是什么样的BI应用,ClickHouse都可以和上下游去做到无缝的对接和整合。最后, ClickHouse硬件资源的利用率也比较高,可以用更...
一文了解 DataLeap 中的 Notebook
整体架构预览如图。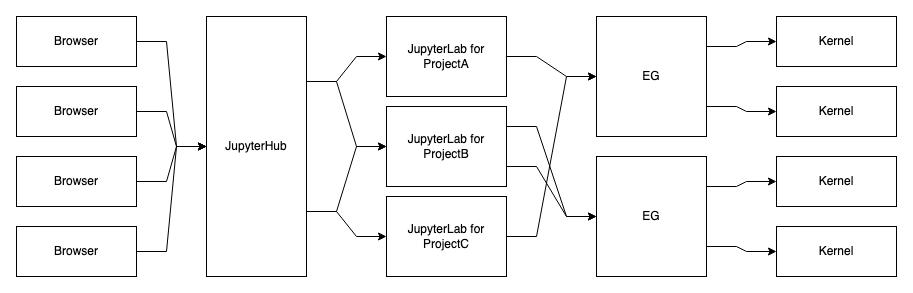### JupyterLab前端这一侧,我们选择了基于更现代化的 [JupyterLab](https://jupyterlab.readthedocs.io/en/stable/getting_started/overview.html) 进行改造。我们刨去了它的周边视图,只留下了中间的 Cell 编辑区,嵌入了 DataLeap 数据研发的页面中。为了和 DataLeap 的视觉...
基于 Apache Calcite 的多引擎指标管理最佳实践|CommunityOverCode Asia 2023
你有注意过 Spark 和 Presto 中同义但不同名的函数吗,比如 instr 和 strpos?接下来要介绍的统一 SQL 可以帮助你自动适应多引擎。第二个问题,你有纠结过 map 字段中有哪些 key 以及它的含义是什么吗?接下来要介绍... **1.1 整数除法在不同引擎的差异**SQL 查询在不同引擎之间是存在差异的,例如整数的除法。举一个点击率的例子,如下图所示,点击率等于点击数除以曝光数,但业务通常会将点击数、曝光数这两个指标定义为 in...
基于边缘计算 Client-Edge-Server 业务模型实践
近期,以 **《极致体验,揭秘抖音背后的音视频技术》** 为主题字节跳动第五期技术沙龙圆满落幕。在沙龙中,火山引擎边缘计算产品解决方案架构师王琦从架构的角度,跟大家探讨了 Client-Edge-Server 云边端架构(以下简称... 应用前端与后端架构均发生了明显的变化。- 首先,应用前端载体的移动化。从最早单机模式,逐渐区分出客户端、服务端,以及客户端类型去兼容浏览器的BS结构;再到现在,移动互联网高速发展,客户端的载体更加丰富。可...
干货 | 实时数据湖在字节跳动的实践
不同的人可能有着不同的解读。这个名词诞生以来,在不同的阶段被赋予了不同的含义。