关于堆内存中的块对齐的问题
 社区干货
社区干货
技术资讯:VSCode大更新,这两个. 功能终于有了
此版本中有许多更新,我们希望您会喜欢,其中一些主要亮点包括:- 浮动编辑器窗口 - 将编辑器拖放到桌面上。- 无障碍视图工作流程 - 更顺畅地往返于无障碍视图。- 更精细的扩展更新控制 - 选择要自动更新的扩展。- 源代码控制传入和传出视图 - 轻松查看待处理的存储库更改。- JavaScript 堆快照 - 可视化堆快照,包括内存对象图。- TypeScript 从嵌入提示转到定义 - 从嵌入提示悬停跳转到定义。- Python 类型层...
深入剖析 split locks,i++ 可能导致的灾难
上面的`i++`代码就不得不考虑数据一致性的问题:#### 1.1.1 并发写问题如果 CoreA 正在向 i 的内存地址中写入时,CoreB 同时向 i 的内存地址写入怎么办?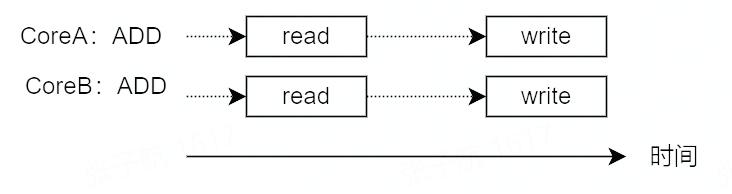并发写相同内存地址其实很简单,CPU 从硬件上保证了基础内存操作的原子性。具体的操作有:- 读/写 1 byte- 读/写 16 bit 对齐的 2 by...
关于大数据计算框架 Flink 内存管理的原理与实现总结 | 社区征文
完全基于jvm的堆内存管理存在较大的缺陷,flink基于jvm实现了独立的内存管理:可超出主内存的大小限制、承受更少的垃圾回收开销、对象序列化二进制存储,下面在来详细介绍下flink内存管理。## 完全JVM内存管理存在的问题基于JVM的数据分析引擎都需要面对将大量数据存到内存当中,就不得不面对JVM存在的几个问题:- java对象存储密度低:比如一个只包含boolean属性的对象占用16个字节,对象头占用8个,boolean属性占1个,对齐填充占...
字节跳动 EB 级 Iceberg 数据湖的机器学习应用与优化
问题及为实现降本增效目标需要调整的地方。 首先,需要**优化** **训练样本** **的存储大小**,减少存储成本。随着数据集的规模增长,存储需求、成本也会相应增加,这对于大规模的训练模型来说是一个挑战。其次,还需要**优化** **训练样本** **的读取速度**。随着芯片技术的迭代和算力的增长,训练模型所需的计算资源也在不断提升。然而如果样本的读取速度无法跟上算力的增长就会成为训练过程中的瓶颈,限制算力资源的有效利用...
 特惠活动
特惠活动
 关于堆内存中的块对齐的问题-优选内容
关于堆内存中的块对齐的问题-优选内容
 关于堆内存中的块对齐的问题-相关内容
关于堆内存中的块对齐的问题-相关内容
基于 LoserTree 的 Paimon 多路归并优化
背景介绍:介绍 Paimon 中读取数据的原理及优化思路;1. 多路归并算法:介绍堆排序和 LoserTree 的实现原理,并对算法复杂度进行分析和对比;1. 方案设计:分析在 Paimon 中使用 LoserTree 存在的问题,并提出一个基... 内存无法全量装入时,会将这些数据先组织为多个有序的子文件,然后再对这些子文件进行归并。在 Paimon 中,每个 RecordReader 已经是有序的,因此我们只需要进行归并流程操作。下面会主要对堆排序和 LoserTree 算法进行...
火山引擎大规模机器学习平台架构设计与应用实践
比如在算法问题上,一个方法比另外一好,其中的原因多种多样,可能是基础架构不同,也可能是算法不同。在字节跳动的实践中发现,基础架构对性能或迭代效率有影响,但大部分情况下对算法效果不应该有影响。我们不希望在算... 以此克服在 CPU 上更新参数会遇到的内存带宽瓶颈问题。BytePS 的整体架构以及 Communication Service 和 Summation Service 的交互方式如下所示。红色部分表示跨机通信,蓝色部分表示机内通信,绿色则是纯 CPU 部分...
「跨越障碍,迈向新的征程」盘点一下2022年度我们开发团队对于云原生的技术体系的变革|社区征文
**【安全问题,以及workaround的问题较多】** 其实新版本与旧版本区别主要在于应用了社区中经过cherrypick挑选出来的PR以及修复了安全性漏洞、没有workaround(临时解决办法)的bug。3. **【稳定性能力】NGINX-Ing... 堆内存不相符, 导致含有未知内存占用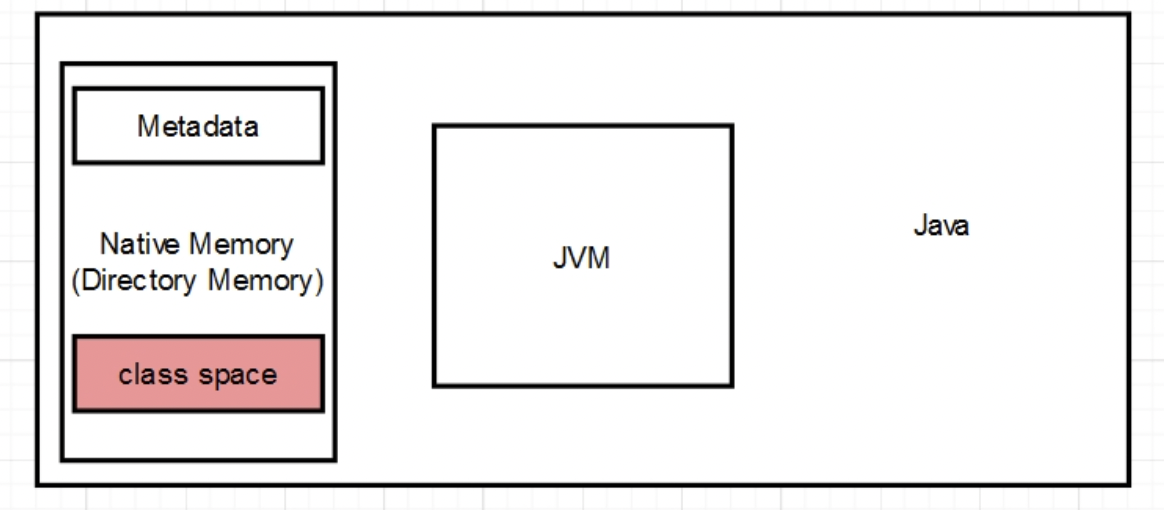两者都是和直接内存有关系,如果大家想了解为什么...
Go 生态下的字节跳动大规模微服务性能优化实践
一些性能相关的问题也开始逐渐暴露出来。本次分享将以字节跳动的性能优化工作为例,介绍基于 Go 生态的微服务体系下,分析系统性能、优化不同层次软件以提升运行性能、提高资源使用效率的一些实践和经验,会特别介绍... 内存等;三是运行时数据,包括 PProf 和 FuncProf 数据。其中,PProf 是通过采样方式,在一秒钟内默认打 100 个点,如果踩到了一个点就相当于占了 1% 时间。字节跳动基础架构语言团队在内部的 Go 发行版增加了 F...
数据一致性离不开的checkpoint机制 |社区征文
为了保证读写的效率,一般我们都会通过异步的方式来写数据,即先把数据写入内存,返回请求结果,然后再将数据异步写入。但是如果异步写入之前,系统宕机,会导致内存中的数据丢失。 **(write back)** 当系统出现故障重启后,通常要对前面的操作进行**replay**。但是从头开始代价太高了,所以通过checkpoint来减少进行**replay**的操作数。**checkpiont机制**保证在某一时刻,系统运行所在的易失性存储数据与持久化存储的数据保持完全同步,...
火山引擎大规模机器学习平台架构设计与应用实践
比如在算法问题上,一个方法比另外一好,其中的原因多种多样,可能是基础架构不同,也可能是算法不同。在字节跳动的实践中发现,基础架构对性能或迭代效率有影响,但大部分情况下对算法效果不应该有影响。我们不希望在算... 以此克服在 CPU 上更新参数会遇到的内存带宽瓶颈问题。BytePS 的整体架构以及 Communication Service 和 Summation Service 的交互方式如下所示。红色部分表示跨机通信,蓝色部分表示机内通信,绿色则是纯 CPU 部...
干货丨字节跳动基于 Apache Hudi 的湖仓一体方案及应用实践
文丨火山引擎LAS团队李铮本文对目前主流数仓架构及数据湖方案的不足之处进行分析,介绍了字节内部基于实时/离线数据存储问题提出的的湖仓一体方案的设计思路,并分享该方案在实际业务场景中的应用情况。最后还会为... Lambda 架构同样存在一系列尚待优化的问题,**涉及到计算、运维、成本等方面**: **●**实时与批量计算结果不一致引起的数据口径对齐问题:由于批量和实时计算走的是两个计算框架和计算程序,计算结果往往不同,经常...
Kubernetes 观测:基于 eBPF 的云原生深度可观测性实践
可观测性并非简单的数据堆砌,更重要的是将数据通过一定的关联纽带有机串联起来,而不同监控工具可能都有各自的元数据语义化标准,难以实现对齐统一。各个观测数据之间也缺乏必要的因果关系,在根因定位的时候难以实... 中运行沙盒程序。eBPF 被用于安全有效地扩展内核的功能,而无需更改内核源代码或加载内核模块,同时 eBPF 程序在加载的时候有严格的 Verifier 进行校验,可以确保代码的正确性,避免死循环或者非法内存访问等问题,这大...
字节跳动 EB 级 Iceberg 数据湖的机器学习应用与优化
问题及为实现降本增效目标需要调整的地方。首先,需要 **优化** **训练样本** **的存储大小**,减少存储成本。随着数据集的规模增长,存储需求、成本也会相应增加,这对于大规模的训练模型来说是一个挑战。其次,还需要 **优化** **训练样本** **的读取速度**。随着芯片技术的迭代和算力的增长,训练模型所需的计算资源也在不断提升。然而如果样本的读取速度无法跟上算力的增长就会成为训练过程中的瓶颈,限制算力资源...
