检测由YOLO检测到的物体的角度
 社区干货
社区干货
基于深度学习的工业缺陷检测详解——从0到1|社区征文
用它去训练目标检测算法,我在这里使用的是yolov5进行迁移学习,得到一个基准模型。对这个基准模型的各类目标进行详细的性能评估,算法对轨面光带、剥离掉块、疲劳裂纹等这些伤损的各类难例都能进行较好的兼容。有了目... 就可以提出视觉测量的分析方法了,比如测量轨面的光带宽度、伤损的尺寸、轻重伤的总数这样的量化评价指标。有了视觉测量的信息之后,就可以分别定义各个尺度的数据分析、数据结构了,比如实例尺度的微观伤损形位的数据...
一个老程序员的计算机视觉蹒跚学习之路| 社区征文
主要使用 OpenCV 和人工智能 YOLO3 进行开发。但是遇到了一些难以解决的问题,一是基于 AI 的目标检测,依靠训练数据产生的目标识别能力存在不可控的问题,可能绝大多数情况识别都没有问题,但一旦存在问题时很难去解决... 物体标识的识别;1. 高级处理:识别图像整体、与视觉相关的认知。这一年多的学习,老猿学习进展缓慢,还停留在数字图像处理的低级处理的初始阶段,目前学习了图像处理的部分基础概念和一些基础操作,包括图像处理的步...
大模型的应用前景:从自然语言处理到图像识别 | 社区征文
目标检测、图像生成等任务。- 挑战与机遇:大型模型技术的发展也带来了一些磨练。大型模型务必实践和推理巨大的计算资源和存储量,并对硬件条件作出要求。此外,还应进一步研究与处理大型模型的可解释性、隐私保护... 物体检测与识别:大模型可以在图像中清晰地检测与识别物件。这对自动驾驶、安防监控、图像检索等应用具有重要意义。 图像形成与生成:大模型能够形成高质量图像,包含图像修补、图像提高和图像生成。这广泛用于...
使用pytorch自己构建网络模型总结|社区征文
前段时间在Git上下载了yolov5的代码,经过调试,最后运行成功。但是发现对网络训练的步骤其实很不熟悉,于是乎最近看了看基于pytorch的深度学习——通过学习,对pytorch的框架有了较清晰的认识,也可以自己来构建一些模... 并在测试集上进行测试,这时候我们可以保存我们训练好的模型。最后通过我们训练的模型来判断一些图片的类别**(从网络上下载一些图片,判断它是猫是狗或是其他的类型【当然这个数据集只有10种类型,如上图所示的10种】...
 特惠活动
特惠活动
 检测由YOLO检测到的物体的角度-优选内容
检测由YOLO检测到的物体的角度-优选内容
 检测由YOLO检测到的物体的角度-相关内容
检测由YOLO检测到的物体的角度-相关内容
基于深度学习的工业缺陷检测详解——从0到1|社区征文
用它去训练目标检测算法,我在这里使用的是yolov5进行迁移学习,得到一个基准模型。对这个基准模型的各类目标进行详细的性能评估,算法对轨面光带、剥离掉块、疲劳裂纹等这些伤损的各类难例都能进行较好的兼容。有了目... 就可以提出视觉测量的分析方法了,比如测量轨面的光带宽度、伤损的尺寸、轻重伤的总数这样的量化评价指标。有了视觉测量的信息之后,就可以分别定义各个尺度的数据分析、数据结构了,比如实例尺度的微观伤损形位的数据...
一个老程序员的计算机视觉蹒跚学习之路| 社区征文
主要使用 OpenCV 和人工智能 YOLO3 进行开发。但是遇到了一些难以解决的问题,一是基于 AI 的目标检测,依靠训练数据产生的目标识别能力存在不可控的问题,可能绝大多数情况识别都没有问题,但一旦存在问题时很难去解决... 物体标识的识别;1. 高级处理:识别图像整体、与视觉相关的认知。这一年多的学习,老猿学习进展缓慢,还停留在数字图像处理的低级处理的初始阶段,目前学习了图像处理的部分基础概念和一些基础操作,包括图像处理的步...
大模型的应用前景:从自然语言处理到图像识别 | 社区征文
目标检测、图像生成等任务。- 挑战与机遇:大型模型技术的发展也带来了一些磨练。大型模型务必实践和推理巨大的计算资源和存储量,并对硬件条件作出要求。此外,还应进一步研究与处理大型模型的可解释性、隐私保护... 物体检测与识别:大模型可以在图像中清晰地检测与识别物件。这对自动驾驶、安防监控、图像检索等应用具有重要意义。 图像形成与生成:大模型能够形成高质量图像,包含图像修补、图像提高和图像生成。这广泛用于...
使用pytorch自己构建网络模型总结|社区征文
前段时间在Git上下载了yolov5的代码,经过调试,最后运行成功。但是发现对网络训练的步骤其实很不熟悉,于是乎最近看了看基于pytorch的深度学习——通过学习,对pytorch的框架有了较清晰的认识,也可以自己来构建一些模... 并在测试集上进行测试,这时候我们可以保存我们训练好的模型。最后通过我们训练的模型来判断一些图片的类别**(从网络上下载一些图片,判断它是猫是狗或是其他的类型【当然这个数据集只有10种类型,如上图所示的10种】...
为自定义模型创建版本
您可以将版本对应的模型文件部署到一体机。ONNX 模型文件加密ONNX 模型支持模型文件加密功能,您可以将通过密码加密的模型文件上传到边缘智能控制台,而将对应的密码保管在一体机(无需上传到云端)。模型文件只能通过边缘智能提供的加密工具进行加密。如需上传加密的 ONNX 模型文件,您可以根据 ONNX 模型文件加密说明准备对应的模型文件。 前后处理版本前后处理版本适用于 图像分类 和 物体检测 模型。它定义了模型前处理和后处理的...
【Flocking算法】海王的鱼塘是怎样炼成的 | 社区征文
手动更换目标物体的位置。可以看到,鱼群跟随目标的移动而移动。## 七、分离### 1.躲避🐟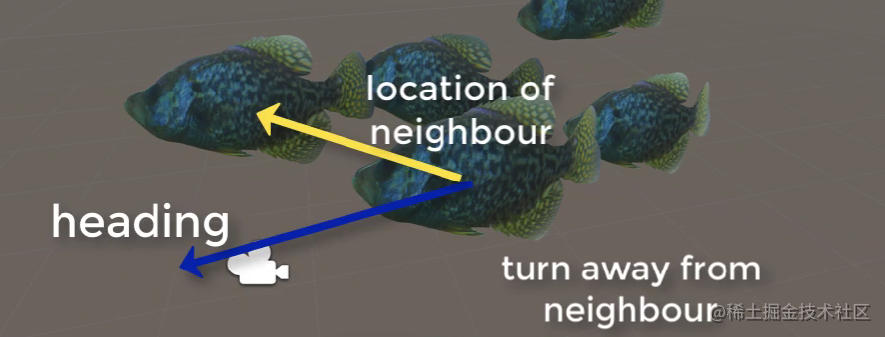为了避免鱼群内部的鱼相互碰撞,要指定一个分离的原则。如上图所示,鱼本来要向中心位置聚合的,但由于会碰撞到其他的鱼,所以需要转向。🐟和🐟之间的躲避变量是`avoid`,代码部分也在上面的Communit...
抖音世界杯的画质优化实践解析
FIFA 现场信号首先传到央视端进行合规安全处理,然后经过演播室的制作传输给 CDN 再进一步分发到用户侧。从画质角度来看整个链路可分为画质检测与画质优化两个部分,对于 CDN 之前的链路以画质监测为主,以发现问题/定... 通过人眼显著性区域检测和编码相结合的方式,让码率在画面上的分配更加合理。目前市面上没有专门针对足球场景的 saliency(显著性物体检测)数据集,通用的 saliency 数据集在世界杯这类特定场景中表现并不理想。 ...
万字长文带你弄透Transformer原理|社区征文
不管是物体分类,目标检测还是语义分割的榜单前几名基本都是用VIT实现的!!!朋友,相信你点进来了也是了解了VIT的强大,想一睹VIT的风采。🌼🌼🌼正如我的标题所说,作为一名CV程序员,没有接触过NLP(自然语言处理)的内容... 当然我会尽可能从一个CV程序员的角度来帮助大家理解,也会秉持我写文章的宗旨——通俗易懂,相信你耐心看完会有所收获。🌾🌾🌾- `第二篇:`介绍VIT,即transformer模型在视觉领域的应用,当你对第一篇transformer了解透...
CVPR 2024 满分论文 | 基于可变形3D高斯的高质量单目动态重建新方法
是指使用单眼摄像头观察并分析的动态环境,其中场景中的物体可以自由移动。单目动态场景重建对于理解环境中的动态变化、预测物体运动轨迹以及动态数字资产生成等任务至关重要。随着以神经辐射场(Neural Radiance ... 结合实现了高质量的重建与新视角渲染。实验结果表明,变形场可以准确地将规范空间下的3D高斯前向映射(forward-flow)到观测空间,不仅在D-NeRF数据集上实现了10+的PSNR提高,而且在相机位姿不准确的真实场景也取得了渲...
