对象存储流式写入
 社区干货
社区干货
基于火山引擎 EMR 构建企业级数据湖仓
开放存储:数据不局限于某种存储底层,支持包括从本地、HDFS 到云对象存储等多种底层。 - Table 格式:本质上是基于存储的、 Table 的数据+元数据定义。具体来说,这种数据格式有三个具体的实现:Delta Lake、Iceberg 和 Hudi。三种格式提出的出发点略有不同,但是它们的场景需求里都不约而同地包含了事务支持和流式支持。而它们在具体的实现中也采用了比较相似的做法,即在数据湖的存储之上定义一个元数据,并跟数据一样保存在...
火山引擎 Iceberg 数据湖的应用与实践
Iceberg 是一种适用于 HDFS 或者对象存储的表格式,把底层的 Parquet、ORC 等数据文件组织成一张表,向上层的 Spark,Flink 计算引擎提供表层面的语义,作用类似于 Hive Meta Store,但是和 Hive Meta Store 相比:- ... 这就导致 Hive 表在对象存储上的查询开销很大。而 Iceberg 的文件组织形式,从 Metadata File 到 Manifest List,再到 Manifest File,最后到实际的 Data File,通过这种层级关系保存了一个从 Iceberg 表到底层所有数...
字节跳动流式数仓和实时服务分析的思考与实践
同时还提供统一的存储,可满足所有面向实时分析服务的 User Case。其次,Flink Table Store 存储易用,可直接像 DFS 分布式文件系统或对象存储一样使用,这对整个效率的提升、存储成本和性能的平衡都有很大作用。### 2. **存储结构**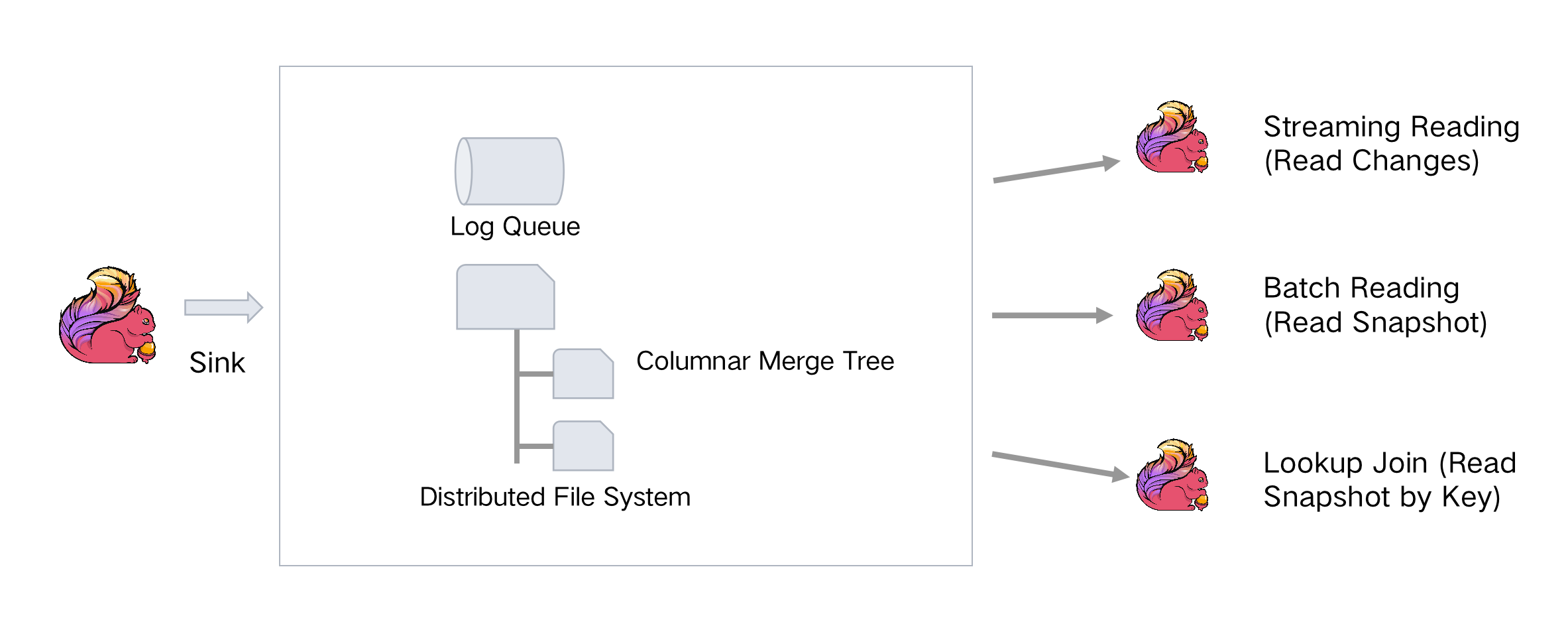Flink Table Store 的存储结构包括两部分:- 依赖于流式的其他...
关于大数据计算框架 Flink 内存管理的原理与实现总结 | 社区征文
## 背景介绍最近几年国内大数据apache开源社区计算框架最火的莫过于Flink,得益于阿里在后面的推动以及各大互联网大厂的参与,flink业已成为流式计算事实上的标准。一句话来介绍 Flink 就是 “Stateful Computatio... 对象序列化二进制存储,下面在来详细介绍下flink内存管理。## 完全JVM内存管理存在的问题基于JVM的数据分析引擎都需要面对将大量数据存到内存当中,就不得不面对JVM存在的几个问题:- java对象存储密度低:比如...
 特惠活动
特惠活动
 对象存储流式写入-优选内容
对象存储流式写入-优选内容
 对象存储流式写入-相关内容
对象存储流式写入-相关内容
读取 Kafka 数据写入 TOS 再映射到 LAS 外表
Flink 是一个兼容 Apache Flink 的全托管流式计算平台,支持对海量实时数据的高效处理。LAS 是湖仓一体架构的 Serverless 数据平台,提供海量数据存储、管理、计算和交互分析功能。本文通过一个示例场景模拟 Flink 与 LAS 的联动,从而体验跨源查询分析、元数据自动发现等能力。 场景介绍本文模拟场景主要实现:读取消息队列 Kafka 数据写入对象存储 TOS,并映射为湖仓一体分析服务 LAS 外表进行数据分析。在 Flink 控制台通过开发 Fl...
Spark流式读写 Iceberg(适用于EMR 2.x版本)
本文以 Spark 2.x 操作 Iceberg 表为例介绍如何通过 Spark Structured Streaming 流式读写 Iceberg 表。 1 前提条件适合 E-MapReduce(EMR) 2.x 的版本 已创建 EMR 集群,且安装有 Iceberg 组件。有两种方式可以安装... 流式写入 Spark Structured Streaming 通过 DataStreamWriter 接口流式写数据到 Iceberg 表,代码如下。 val name = TableIdentifier.of("default","spark2_streaming_demo")val tableIdentifier = name.toStringva...
Spark流式读写 Iceberg
本文以 Spark 3.x 操作 Iceberg 表为例介绍如何通过 Spark Structured Streaming 流式读写 Iceberg 表。 1 前提条件适合 E-MapReduce(EMR) 1.2.0以后的版本(包括 EMR 1.2.0) 不适配 EMR 2.x 的版本。EMR2.x 版本中... 流式写入 Spark Structured Streaming 通过 DataStreamWriter 接口流式写数据到 Iceberg 表,代码如下。 val tableIdentifier: String = "iceberg.iceberg_db.streamingtable"val checkpointPath: String = "/tmp/i...
使用说明
原始数据以流式或者批式的方式写入 Delta Lake,在 Delta Lake 内部完成 Bronze Table 到 Gold Table 的 transform 过程(类比数据仓库的 ODS 到 ADS 的过程)。不论是原始表、中间表和结果表,都支持上层多种查询引擎,数据则存储在大数据存储或者对象存储上。Lakehouse 架构(图片来源于 Delta Lake 官网) 与 Delta Lake 类似的表格式存储还有 Iceberg 和 Hudi,E-MapReduce(EMR) 上对于两者亦有提供,用户可以查阅相关文档。 2 Delta ...
基于火山引擎 EMR 构建企业级数据湖仓
开放存储:数据不局限于某种存储底层,支持包括从本地、HDFS 到云对象存储等多种底层。 - Table 格式:本质上是基于存储的、 Table 的数据+元数据定义。具体来说,这种数据格式有三个具体的实现:Delta Lake、Iceberg 和 Hudi。三种格式提出的出发点略有不同,但是它们的场景需求里都不约而同地包含了事务支持和流式支持。而它们在具体的实现中也采用了比较相似的做法,即在数据湖的存储之上定义一个元数据,并跟数据一样保存在...
存储选型最佳实践
本节主要介绍使用容器服务(VKE)时如何选择存储(对象存储、文件存储、弹性快存储)类型以及选择时的注意事项。 存储说明不同的业务类型,需要选择不同的存储类型以匹配业务需要,以下内容将对火山引擎提供的存储类型的... 文件存储 NAS 提供简单、易操作的对外接口,并支持按实际使用量计费,免去部署、维护费用的同时,最大化提升您的业务效率。更多信息,请参见 文件存储。 支持多场景:满足千亿级别海量文件 OPS、大文件高带宽读写、小 ...
火山引擎 Iceberg 数据湖的应用与实践
Iceberg 是一种适用于 HDFS 或者对象存储的表格式,把底层的 Parquet、ORC 等数据文件组织成一张表,向上层的 Spark,Flink 计算引擎提供表层面的语义,作用类似于 Hive Meta Store,但是和 Hive Meta Store 相比:- ... 这就导致 Hive 表在对象存储上的查询开销很大。而 Iceberg 的文件组织形式,从 Metadata File 到 Manifest List,再到 Manifest File,最后到实际的 Data File,通过这种层级关系保存了一个从 Iceberg 表到底层所有数...
如何使用函数服务实现对象存储同步刷新CDN
前言本实验使用函数服务,实现对象存储资源删除、上传时自动调用刷新CDN缓存的接口。 关于实验预计部署时间:20分钟 级别:初级 相关产品:函数服务、对象存储、内容分发网络 受众: 通用 实验说明点击此链接登录控制台... 第六步:将 Signature 签名写入 HTTP Header 中,并发送 HTTP 请求。 r = requests.post("https://{}{}".format(request_param["host"], request_param["path"]), headers=header, ...
字节跳动流式数仓和实时服务分析的思考与实践
同时还提供统一的存储,可满足所有面向实时分析服务的 User Case。其次,Flink Table Store 存储易用,可直接像 DFS 分布式文件系统或对象存储一样使用,这对整个效率的提升、存储成本和性能的平衡都有很大作用。### 2. **存储结构**Flink Table Store 的存储结构包括两部分:- 依赖于流式的其他...
