消息队列堆栈溢出
 社区干货
社区干货
大数据量、高并发业务优化教程|社区征文
博主这里的大数据量、高并发业务处理优化基于博主线上项目实践以及全网资料整理而来,在这里分享给大家# 一. 大数据量上传写入优化> 线上业务后台项目有一个消息推送的功能,通过上传包含用户id的文件,给指定用户推送系统消息## 1.1 如上功能描述很简单,但是对于技术侧想要做好这个功能,保证大用户量(比如达到百万级别)下,系统正常运行,功能正常其实是需要仔细思考的,博主这里给出思路:1. 上传文件类型选择通常情况下大部...
一文带你读懂:云原生时代业务监控|社区征文
例如:队列的当前深度可以被定义为一个计量单元,在写入或读取时被更新统计;输入 HTTP 请求的数量可以被定义为一个计数器,用于简单累加;请求的执行时间可以被定义为一个柱状图,在指定时间片上更新和统计汇总。**(2)Logging**:特点是描述一些离散的(不连续的)事件。例如:应用通过一个滚动的文件输出 debug 或 error 信息,并通过日志收集系统,存储到 Elasticsearch 中;审批明细信息通过 Kafka,存储到数据库(BigTable)中;又或者,特...
火山引擎 DataLeap 计算治理自动化解决方案实践和思考
字节跳动数据平台目前使用了 1 万多个任务执行队列,支持 DTS、HSQL、Spark、Python、Flink、Shell 等 50 多种类型的任务。自动计算治理框架目前已经完成了离线任务的接入,包括 HSQL、Hive to X 的 DTS 任务、AB ... 但明天可能因数据量增加而导致内存溢出(OOM),后续运维包括复盘将需要投入大量时间成本。 3. **挑战:复杂的优化场景和目标** 特惠活动
特惠活动
 消息队列堆栈溢出-优选内容
消息队列堆栈溢出-优选内容
 消息队列堆栈溢出-相关内容
消息队列堆栈溢出-相关内容
2024年03月
队列顺序决定实际运行顺序。 自定义查询: 支持用户查询已建任务执行情况,帮助排查数据是否异常。通过输入ID即可快速查询导入到内存数据库中的数据情况。 新增 对权限管理移除用户权限归属问题逻辑优化。当管理... 还有效降低了内存溢出和CPU过载的风险。 新增 新增数据接入方式: 支持接入抖音来客的订单数据。 优化 接入字段更新: 对抖音短视频用户数据接入功能进行了优化,部分接入的中文字段名称发生变更,以提高数据管...
故障类型
内存溢出 JVM 堆(Heap)溢出或栈(Stack)溢出。 指定类返回值 自定义方法的返回值。目前支持 Int 或者 Strin,其中 String 类型参数值需要加双引号。 进程 CPU 使用率满载 使指定的 CPU 核数被 Java 进程满载。 Kill... 消息队列 Kafka 故障 脏数据 Kafka 中插入脏数据。 重复数据 Kafka 中插入一定数目的重复数据。 RocketMQ 故障 脏数据 RocketMQ 中插入脏数据。 重复数据 RocketMQ 中插入一定数目的重复数据。 RabbitMQ 故障 脏数...
应用性能前端监控,字节跳动这些年经验都在这了
堆栈反解析等清洗任务。 根据不同平台产品功能,分门别类落地在不同类型的存储中: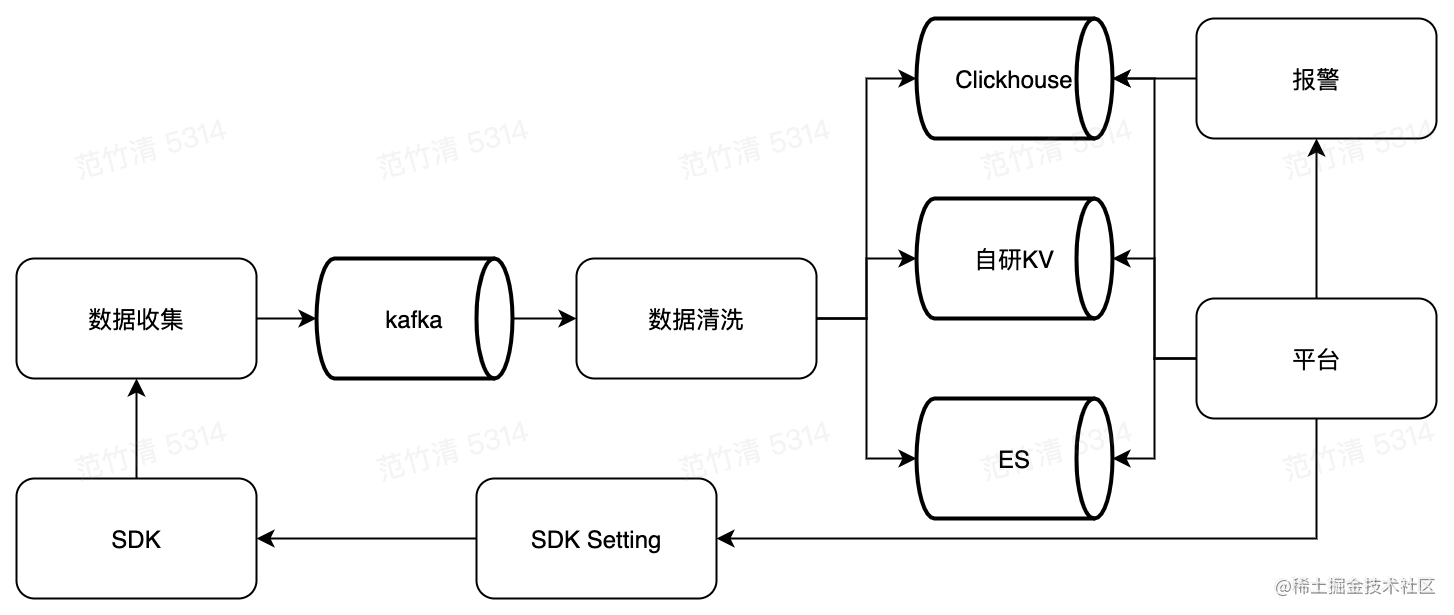- 数据收集层: 数据收集层是无状态的API服务,逻辑较轻。只提供针对SDK上报数据的鉴权校验, 拆包等工作, 然后写入消息队列 Kafka 供数据清洗层消费- 数据清洗层:数据清洗层是数据处理的逻辑中...
搞流式计算,大厂也没有什么神话
消息队列。好在趁着字节的业务场景偏单一,主要聚焦在机器学习场景,张光辉和其团队将流式计算引擎从 Apache Storm 切换到了 Apache Flink。所谓团队,其实连他在内,也仅有两人。之后又在 2018 年与数据流团队合作完成了流式计算平台化的构建,包括任务的监控、报警,日志采集,异常诊断等工具体系。来到 2019 年,流式计算要支撑的业务场景已经相当丰富,扩展到了实时数仓、安全和风控等,并且还在不断增加。单个场景需求也变得...
2022 年每个开发者必知的云原生趋势 | 社区征文
消息队列等。**反例**:把缓存服务和应用服务打包到同一个容器镜像,通过/var/redis.sock这样的Domain Socket形式访问;或者把第三方应用服务的源码直接复制到自己的代码中,在一个进程中互相调用。5. Build, release, run-分离**构建、发布、运行**>Strictly separate build and run stages每个版本必须在构建、发布和运行阶段实行严格的分离。每个版本都应该被标记为唯一的ID,并支持回滚的能力。CI/CD系统有助于实现这一原则...
火山引擎ByteHouse:4000字总结,Serverless在OLAP领域应用的五点思考
> 更多技术交流、求职机会,欢迎关注字节跳动数据平台微信公众号,回复【1】进入官方交流群作为云计算的下一个迭代,Serverless可以使开发者更专注于构建产品中的应用,而无需考虑底层堆栈问题。伴随着近年来相关技术... kafka消息队列以及ETL任务执行等。对于长时间运行、计算密集型、高并发读写、需要持续运行的分析业务则不适合使用 Serverless 技术。### 应用Serverless技术存在哪些门槛在OLAP领域,无论是经典的MPP架构向Se...
从 ClickHouse 到 ByteHouse:实时数据分析场景下的优化实践
修改 Kafka Topic 的消息格式直接适配 ClickHouse 表的 schema;- 敏捷 BI 平台也适配了一下实时的场景,可以支持交互式的查询分析;- 如果实时数据有问题,也可以从 Hive 把数据导入至 ClickHouse 中,除此之外,... 第三步把构建好的 Part 放入到一个异步索引构建队列中,由后台线程构建索引文件。**效果**:在改成异步后,整体的写入吞吐量大概能提升 20%。**问题二:Kafka 消费能力不足****挑战**:社区版本的 Kafka 表,内部...
字节跳动 EB 级 Iceberg 数据湖的机器学习应用与优化
溢出磁盘引起额外 IO 等。此外 Hudi 不支持原生 Python API,只能通过 PySpark 的方式对于算法工程师来说不太友好。- Apache Iceberg 是一种开放的表格式,记录了一张表的元数据:包括表的 Schema、文件、分区、统... 数据湖和消息队列、流式计算可以相互连接,可以通过计算框架提供统一的历史批式、追新流式的管理和接口,同时服务于低延迟的在线流式训练、高吞吐的离线批式训练;并且将消息队列闲置的计算资源用来满足数据湖的数据管...
干货|4000字总结,Serverless在OLAP领域应用的五点思考
而无需考虑底层堆栈问题。 伴随着近年来相关技术成熟度的增加,市场对Serverless的接受程度也变得越来越高。可以说时至今日,Serverless已迈入了向成熟稳定方向发展的高速轨道。 作为一款... kafka消息队列以及ETL任务执行等。 对于长时间运行、计算密集型、高并发读写、需要持续运行的分析业务则不适合使用 Serverless 技术。