如何组装/链接两个引用相同函数的汇编文件(用于引导加载程序)
 社区干货
社区干货
golang pprof
对应的场景是脚本/工具类的程序,一般运行一段时间就会停止,不会持续运行,这种情况下直接使用runtime包的pprof工具来采集进程的性能数据是最方便,直接在进程运行中持续写入pprof文件或者在结束后将各项性能数据写入... 当前函数及当前函数的子函数占用的cpu时间 || cum% | 当前函数及当前函数的子函数占用的cpu时间百分比 ...
云原生环境下的日志采集、存储、分析实践
Kubernetes 下如何采集日志呢? 官方推荐了四种日志采集方案:- DaemonSet:在每台宿主机上搭建一个 DaemonSet 容器来部署 Agent。业务容器将容器标准输出存储到宿主机上的文件,Agent 采集对应宿主机上的文件。- St... ES 的原始数据和索引使用相同的资源配置,也会导致高成本。 - 功能不足:比如 ES 的投递和消费能力弱、分析能力固化、没有告警能力、可视化能力有限。## 火山引擎统一日志平台 TLS在遇到这些问题以后,我们研发...
漫谈开源许可证:开发者需要知道的法理和事例
我们认为非自由程序是对用户的不公正。开源阵营刻意避开用户公正的问题,转而以 仅仅实用的益处 来立意。 **02** **开源许可证** 开源许可证可以看作是一种项目所... 与此相对的是有着互惠/相同方式共享要求的许可协议。这两种开源许可证都对软件可以如何使用、研究或修改提供同样自由。其主要差别是,当软件被分发(不论有无被修改)时, **宽松许可允许分发者限制他人对源代码的获取...
云原生环境下的日志采集、存储、分析实践
Kubernetes 下如何采集日志呢? 官方推荐了四种日志采集方案:- DaemonSet:在每台宿主机上搭建一个 DaemonSet 容器来部署 Agent。业务容器将容器标准输出存储到宿主机上的文件,Agent 采集对应宿主机上的文件。 -... 4. 客户端收到配置信息,热加载到本地配置,以新的配置进行采集。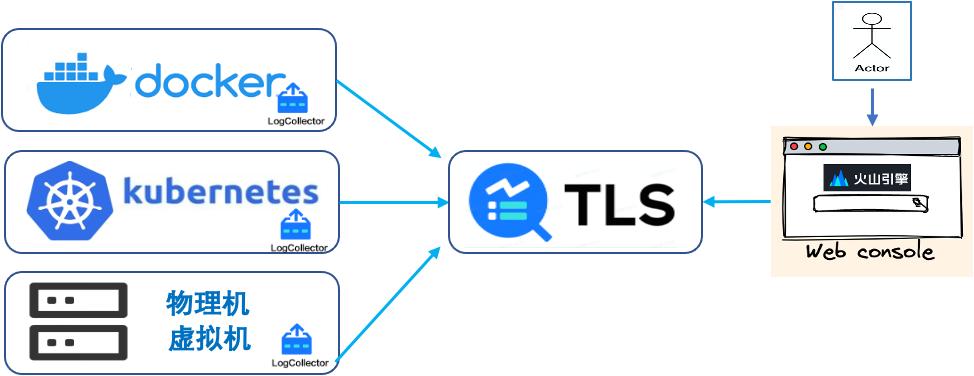中心化配置管理...
 特惠活动
特惠活动
 如何组装/链接两个引用相同函数的汇编文件(用于引导加载程序)-优选内容
如何组装/链接两个引用相同函数的汇编文件(用于引导加载程序)-优选内容
 如何组装/链接两个引用相同函数的汇编文件(用于引导加载程序)-相关内容
如何组装/链接两个引用相同函数的汇编文件(用于引导加载程序)-相关内容
云原生环境下的日志采集、存储、分析实践
Kubernetes 下如何采集日志呢? 官方推荐了四种日志采集方案:- DaemonSet:在每台宿主机上搭建一个 DaemonSet 容器来部署 Agent。业务容器将容器标准输出存储到宿主机上的文件,Agent 采集对应宿主机上的文件。- St... ES 的原始数据和索引使用相同的资源配置,也会导致高成本。 - 功能不足:比如 ES 的投递和消费能力弱、分析能力固化、没有告警能力、可视化能力有限。## 火山引擎统一日志平台 TLS在遇到这些问题以后,我们研发...
漫谈开源许可证:开发者需要知道的法理和事例
我们认为非自由程序是对用户的不公正。开源阵营刻意避开用户公正的问题,转而以 仅仅实用的益处 来立意。 **02** **开源许可证** 开源许可证可以看作是一种项目所... 与此相对的是有着互惠/相同方式共享要求的许可协议。这两种开源许可证都对软件可以如何使用、研究或修改提供同样自由。其主要差别是,当软件被分发(不论有无被修改)时, **宽松许可允许分发者限制他人对源代码的获取...
云原生环境下的日志采集、存储、分析实践
Kubernetes 下如何采集日志呢? 官方推荐了四种日志采集方案:- DaemonSet:在每台宿主机上搭建一个 DaemonSet 容器来部署 Agent。业务容器将容器标准输出存储到宿主机上的文件,Agent 采集对应宿主机上的文件。 -... 4. 客户端收到配置信息,热加载到本地配置,以新的配置进行采集。中心化配置管理...
功能发布记录(2023年)
新增支持引用 Jar 资源包形式,在资源中自定义 Connector; EMR 引擎任务类型,支持选择 Yarn 队列资源,对应项目可支持配置多个 Yarn 队列资源可供任务选择。 数据开发概述、流水线管理 Serverless Flink SQL、EMR F... 扩展程序说明 创建项目、修改项目配置信息 独享资源组管理 3 数据质量 数据质量双数据源校验支持 Hive 数据源,用于验证任意两种数据源之间的数据是否一致。 配置双数据源校验规则 2023/11/27序号 功能 功能...
一口气看完43个关于 ElasticSearch 的使用建议
类似的还有在脚本查询中使用了 Math.random() 等函数的查询也不会进行缓存。当有新的 Segment 写入到分片后,缓存会失效,因为之前的缓存结果已经无法代表整个分片的查询结果。所以分片每次**Refresh**之后,缓存会... 两者分别适用于哪种场景?SearchAfter 可以完全替代 Scroll 吗?Scroll 维护一份当前索引段的快照,适用于非实时滚动遍历全量数据查询,但大量Contexts 占用堆内存的代价较高;7.10 引入的新特性 Search After + PIT,...
系统集成在一些特定行业的相关概念
分析型处理则用于管理人员的决策分析,经常要访问大量的历史数据。数据仓库(DataWarehouse)是一个面向主题的、集成的、相对稳定的、反映历史变化的数据集合,用于支持管理决策。可从两个层面理解数据仓库:首先数... 对于传输文件的业务,必须压缩后传输,以减轻网络压力,提高传输速度。在接口中所使用的压缩工具必须基于通用无损压缩技术,压缩算法的模型和编码必须符合标准且高效,压缩算法的工具函数必须是面向流的函数,并且提供...
火山引擎 DataLeap 套件下构建数据目录(Data Catalog)系统的实践
Index Store:存放用于加速查询,支持全文索引等场景的索引,当前使用的是ElasticSearch- Model Store:存放推荐、打标等的算法模型信息,使用HDFS,当ML Service启用时使用### 元数据的消费- 数据的生产者... 火山引擎 DataLeap 研发人员调整了Apache Atlas加载类型文件的机制,使其可以从多个package,以我们定义过的目录结构和先后顺序加载。这也为后面的标准化奠定了基础。## 数据接入标准化为了最终达成降低接入和维...
火山引擎 DataLeap 构建Data Catalog系统的实践(三):关键技术与总结
用以描述两个Entity之间的关联模式。在实际应用这套类型系统时,我们有两个方面比较有特点:1. **继承与组合的广泛使用**
当一块新创建的数据盘挂载到边缘实例之后,还不能直接存储数据。通常您需要完成创建分区、创建文件系统、挂载文件系统等初始化操作后,系统才能读写数据。本文介绍了如何在Linux操作系统中初始化一块全新的数据盘。 ... 步骤二:为数据盘创建分区说明 parted分区工具适用于MBR分区和GPT分区。fdisk分区工具只适用于MBR分区。 以下内容描述如何通过parted分区工具创建GPT分区以及如何通过fdisk分区工具创建MBR分区。 使用parted创建...
