kafka集群工作流程原理
 社区干货
社区干货
Kafka数据同步
其实现原理是通过从 Source 集群消费消息,然后将消息生产到 Target 集群从而完成数据迁移操作。用户只需要通过简单的consumer配置和producer配置,启动MirrorMaker,即可实现实时数据同步。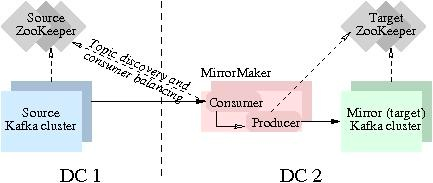本实验主要聚焦跑通Kafka MirrorMaker (MM1)数据迁移流程。实验中的Source Kafka版本为2.12,基于本地机器搭建。现实生产...
聊聊 Kafka:Topic 创建流程与源码分析 | 社区征文
这意味着一个主题分布在位于不同 Kafka 代理的多个“桶”上。数据的这种分布式放置对于可伸缩性非常重要,因为它允许客户端应用程序同时从/向多个代理读取和写入数据。当一个新事件发布到一个主题时,它实际上被附加... 副本数是必须小于集群的 Broker 数的,副本只有设置在不同的机器上才有作用。## 二、Topic 的创建方式### 2.1 zookeeper 方式(不推荐)```./bin/kafka-topics.sh --create --zookeeper localhost:2181 --part...
Kafka@记一次修复Kafka分区所在broker宕机故障引发当前分区不可用思考过程 | 社区征文
怀疑是Kafka某个节点有问题-失联-假死?## 思考过程从这个表象来看,某台机器有过宕机事件,宕机原因因环境而异,但Kafka的高可用性HA我们是耳熟能详的,为啥我们搭建的Kafka集群由多个节点组成,但其中某个节点宕掉... 可设置多个副本因子来保证高可用性(比如三个节点组成一个集群,副本数量为2,这样当任意一台节点丢失,kafka集群仍会正常工作Working...)。## 解决方案当然,把这个宕掉的节点拉起来,查看该分区的信息leader:xxxx ...
消息队列选型之 Kafka vs RabbitMQ
在面对众多的消息队列时,我们往往会陷入选择的困境:“消息队列那么多,该怎么选啊?Kafka 和 RabbitMQ 比较好用,用哪个更好呢?”想必大家也曾有过类似的疑问。对此本文将在接下来的内容中以 Kafka 和 RabbitMQ 为例分... 集群扩容;使用成本等。4. **业务需求:** 要明确你的业务需要什么样的消息队列功能。例如,是否需要支持延时消息、死信队列、事务消息等高级功能,还是只需要基本的生产和消费功能。5. **数据量:** 考虑你的数据量是...
 特惠活动
特惠活动
 kafka集群工作流程原理-优选内容
kafka集群工作流程原理-优选内容
 kafka集群工作流程原理-相关内容
kafka集群工作流程原理-相关内容
Kafka Exporter 接入
托管 Prometheus 服务提供基于 exporter 的方式来监控 Kafka 运行状态,本文为您介绍如何在集群中部署 kafka-exporter,并实现对 Kafka 的监控。 前提条件已注册并开通火山引擎容器服务(VKE)。 已创建托管 Prometheus 工作区,详情请参见 创建工作区。 VKE 集群已接入托管 Prometheus,详情请参见 容器服务接入。 已在 VKE 集群中创建 PodMonitor CRD 资源,详情请参见 创建 PodMonitor CRD 资源。 已在 VKE 集群中部署 Grafana 并接入...
Kafka 迁移上云(方案一)
本文介绍通过方案一将开源 Kafka 集群迁移到火山引擎消息队列 Kafka版的操作步骤。 注意事项业务迁移只迁移消息生产、消费链路和业务流量,并不会迁移 Kafka 旧集群上的消息数据。 创建Kafka实例、迁移消息收发链路... 云上和云下双集群同步处理消息消费,无法保证消费的有序性。迁移步骤如下: 启动新的消费者和生产者。为新建的消息队列 Kafka版实例开启新的消费者和生产者,在云端搭建新的消息生产和消费流程,并启动消息的生产与消费...
Kafka 迁移上云(方案二)
本文介绍通过方案二将开源 Kafka 集群迁移到火山引擎消息队列 Kafka版的操作步骤。 注意事项业务迁移只迁移消息生产、消费链路和业务流量,并不会迁移 Kafka 旧集群上的消息数据。 创建 Kafka 实例、迁移消息收发链路之前,请先确定 Kafka 实例可正常访问,以免因访问异常造成迁移失败。您可以访问 Kafka 实例详情页中的接入点,确认实例的网络连通性。 业务迁移之前,请确认您已根据业务需求选择了正确的迁移方案。迁移方案对比请参考...
流式导入
数据根据 Kafka Partition 自动均衡导入到 ByteHouse Shard。无需配置分片键。 默认数据消费 8 秒后可见。兼顾了消费性能和实时性。 更多原理请参考 HaKafka 引擎文档。 注意 建议 Kafka 版本满足以下条件,否则可能会出现消费数据丢失的问题,详见 Kafka 社区 Issue = 2.5.1 = 2.4.2 操作步骤 创建数据源在右上角选择数据管理与查询 > 数据导入 > 对应集群. 单击左侧选择 “+”,新建数据源。 配置数据源在右侧数据源配置界...
聊聊 Kafka:Topic 创建流程与源码分析 | 社区征文
这意味着一个主题分布在位于不同 Kafka 代理的多个“桶”上。数据的这种分布式放置对于可伸缩性非常重要,因为它允许客户端应用程序同时从/向多个代理读取和写入数据。当一个新事件发布到一个主题时,它实际上被附加... 副本数是必须小于集群的 Broker 数的,副本只有设置在不同的机器上才有作用。## 二、Topic 的创建方式### 2.1 zookeeper 方式(不推荐)```./bin/kafka-topics.sh --create --zookeeper localhost:2181 --part...
Routine Load
本文介绍 Routine Load 的基本原理、以及如何通过 Routine Load 导入至 StarRocks 中。本文图片和内容来源于开源StarRocks的从Apache Kafka持续导入。 1 基本原理导入流程如下: 客户端向FE提交创建导入作业的 SQL ... 3 最佳实践案例3.1 导入CSV格式数据在Kafka集群中执行以下操作,准备源数据 创建Topic shell /usr/lib/emr/current/kafka/bin/kafka-topics.sh --create --bootstrap-server `hostname -i`:9092 --topic ordertest1...
Kafka/BMQ
Kafka 连接器提供从 Kafka Topic 或 BMQ Topic 中消费和写入数据的能力,支持做数据源表和结果表。您可以创建 source 流从 Kafka Topic 中获取数据,作为作业的输入数据;也可以通过 Kafka 结果表将作业输出数据写入到 Kafka Topic 中。 注意事项使用 Flink SQL 的用户需要注意,不再支持 kafka-0.10 和 kafka-0.11 两个版本的连接器,请直接使用 kafka 连接器访问 Kafka 0.10 和 0.11 集群。Kafka-0.10 和 Kafka-0.11 两个版本的连接...
从 Kafka 导入数据
日志服务支持 Kafka 数据导入功能,本文档介绍从 Kafka 中导入数据到日志服务的操作步骤。 背景信息日志服务数据导入功能支持将 Kafka 集群的消息数据导入到指定日志主题。Kafka 数据导入功能通常用于业务上云数据迁移等场景,例如将自建 ELK 系统聚合的各类系统日志、应用程序数据导入到日志服务,实现数据的集中存储、查询分析和加工处理。日志服务导入功能支持导入火山引擎消息队列 Kafka 集群和自建 Kafka 集群的数据。创建导入...
什么是消息队列 Kafka版
消息队列 Kafka版开箱即用,业务代码无需改造,帮助您将更多的精力专注于业务快速开发,免除繁琐的部署和运维工作。 产品功能高效的消息收发:海量消息堆积的情况下,消息队列 Kafka版仍然维持Kafka集群对消息收、发的... 传统数据处理流程中先收集数据,然后将数据放到数据库中供查询和分析的处理架构已无法满足。消息队列 Kafka版配合 Flink 等流计算引擎,可以根据业务需求对实时数据进行计算分析,快速响应分析结果到下一节点。 流量削...
