Kafka集群动态添加代理
 社区干货
社区干货
聊聊 Kafka:Topic 创建流程与源码分析 | 社区征文
以便始终有多个代理拥有数据副本,以防万一出现问题。常见的生产设置是复制因子为 3,即,你的数据将始终存在三个副本。此复制在主题分区级别执行。在设置副本时,副本数是必须小于集群的 Broker 数的,副本只有设置在不同的机器上才有作用。## 二、Topic 的创建方式### 2.1 zookeeper 方式(不推荐)```./bin/kafka-topics.sh --create --zookeeper localhost:2181 --partitions 3 --replication-factor 3 --topic topic_test...
Kafka@记一次修复Kafka分区所在broker宕机故障引发当前分区不可用思考过程 | 社区征文
包括不限于改Kafka,主题创建删除,Zookeeper配置信息重启服务等等,于是我们来一起看看... Ok,Now,我们还是先来一步步分析它并解决它,依然以”化解“的方式进行,我们先来看看业务进程中线程报错信息:```jsor... 怀疑是Kafka某个节点有问题-失联-假死?## 思考过程从这个表象来看,某台机器有过宕机事件,宕机原因因环境而异,但Kafka的高可用性HA我们是耳熟能详的,为啥我们搭建的Kafka集群由多个节点组成,但其中某个节点宕掉...
消息队列选型之 Kafka vs RabbitMQ
对此本文将在接下来的内容中以 Kafka 和 RabbitMQ 为例分享消息队列选型的一些经验。消息队列即 Message+Queue,消息可以说是一个数据传输单位,它包含了创建时间、通道/主题信息、输入参数等全部数据;队列(Queue)... 可以使整个系统更加灵活和可扩展。 **削峰**最重要的优势就是能用来平滑处理系统中的高峰流量。当系统面临瞬时高流量时,消息队列可以作为一个缓冲层,将大量的请求消息存储在队列中,然后按照系统处...
Kafka数据同步
然后将消息生产到 Target 集群从而完成数据迁移操作。用户只需要通过简单的consumer配置和producer配置,启动MirrorMaker,即可实现实时数据同步。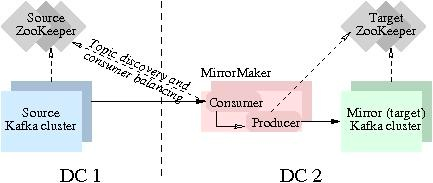本实验主要聚焦跑通Kafka MirrorMaker (MM1)数据迁移流程。实验中的Source Kafka版本为2.12,基于本地机器搭建。现实生产环境会更加复杂,如果您有迁移类的需求,欢迎...
 特惠活动
特惠活动
 Kafka集群动态添加代理-优选内容
Kafka集群动态添加代理-优选内容
 Kafka集群动态添加代理-相关内容
Kafka集群动态添加代理-相关内容
Kafka 迁移上云(方案二)
本文介绍通过方案二将开源 Kafka 集群迁移到火山引擎消息队列 Kafka版的操作步骤。 注意事项业务迁移只迁移消息生产、消费链路和业务流量,并不会迁移 Kafka 旧集群上的消息数据。 创建 Kafka 实例、迁移消息收发链路之前,请先确定 Kafka 实例可正常访问,以免因访问异常造成迁移失败。您可以访问 Kafka 实例详情页中的接入点,确认实例的网络连通性。 业务迁移之前,请确认您已根据业务需求选择了正确的迁移方案。迁移方案对比请参考...
Kafka 迁移上云(方案一)
本文介绍通过方案一将开源 Kafka 集群迁移到火山引擎消息队列 Kafka版的操作步骤。 注意事项业务迁移只迁移消息生产、消费链路和业务流量,并不会迁移 Kafka 旧集群上的消息数据。 创建Kafka实例、迁移消息收发链路... 并且创建和迁移源端同样数量和 ID 的 Group。 开启时,不仅可通过控制台创建 Group,还可以通过消费 SDK 解析获取并展示 Group 的信息。使用 SDK 时按需创建 Group 的方式请参考通过 SDK 设置 Group。 关闭后,只能通...
Kafka/BMQ
Kafka 连接器提供从 Kafka Topic 或 BMQ Topic 中消费和写入数据的能力,支持做数据源表和结果表。您可以创建 source 流从 Kafka Topic 中获取数据,作为作业的输入数据;也可以通过 Kafka 结果表将作业输出数据写入到 Kafka Topic 中。 注意事项使用 Flink SQL 的用户需要注意,不再支持 kafka-0.10 和 kafka-0.11 两个版本的连接器,请直接使用 kafka 连接器访问 Kafka 0.10 和 0.11 集群。Kafka-0.10 和 Kafka-0.11 两个版本的连接...
Kafka@记一次修复Kafka分区所在broker宕机故障引发当前分区不可用思考过程 | 社区征文
包括不限于改Kafka,主题创建删除,Zookeeper配置信息重启服务等等,于是我们来一起看看... Ok,Now,我们还是先来一步步分析它并解决它,依然以”化解“的方式进行,我们先来看看业务进程中线程报错信息:```jsor... 怀疑是Kafka某个节点有问题-失联-假死?## 思考过程从这个表象来看,某台机器有过宕机事件,宕机原因因环境而异,但Kafka的高可用性HA我们是耳熟能详的,为啥我们搭建的Kafka集群由多个节点组成,但其中某个节点宕掉...
流式导入
更多原理请参考 HaKafka 引擎文档。 注意 建议 Kafka 版本满足以下条件,否则可能会出现消费数据丢失的问题,详见 Kafka 社区 Issue = 2.5.1 = 2.4.2 操作步骤 创建数据源在右上角选择数据管理与查询 > 数据导入 > 对应集群. 单击左侧选择 “+”,新建数据源。 配置数据源在右侧数据源配置界面,根据界面提示,依次输入以下信息:源类型:选择 Kafka 数据源类型 源名称:任务名称,和其他任务不能重名。 Kafka 代理列表: 填写对应的...
使用前必读
消息队列 Kafka版是一款火山引擎提供的消息中间件服务。Kafka 基于高可用分布式集群技术,提供了高可靠、可扩展、灵活路由的托管消息队列,泛应用于秒杀、流控、系统解耦等场景。 调用说明消息队列 Kafka版提供了 Op... 使用限制每个火山引擎账号在消息队列 Kafka版的每个地域下可以创建 2 个实例。如果需要更多实例,请在配额中心申请提高配额。 每个API的流控限制不同,查询类 API 的流控限制为 100 次/秒,其他 API 为 20 次/秒。如...
使用前必读
消息队列 Kafka版是一款火山引擎提供的消息中间件服务。Kafka 基于高可用分布式集群技术,提供了高可靠、可扩展、灵活路由的托管消息队列,泛应用于秒杀、流控、系统解耦等场景。 调用说明消息队列 Kafka版提供了全新... 使用限制每个火山引擎账号在消息队列 Kafka版的每个地域下可以创建 5 个实例。如果需要更多实例,请在配额中心申请提高配额。 在 V2 版本中,除以下 API 以外,其余的 API 流控限制均为 20 次/秒。如果服务端返回 ...
Kafka 消费者最佳实践
本文档以 Confluent 官方 Java 版本客户端 SDK 为例,介绍使用火山引擎 Kafka 实例时的消费者最佳实践。 广播与单播在同一个消费组内部,每个消息都预期仅仅只被消费组内的某个消费者消费一次,因而使用同一个消费组的... 可以通过在消息中添加额外的标识字段等方式在消费到消息后,再进行二次校验。 Topic 消费消费者支持通过以下方式指定 Topic: 订阅(Subscribe):标准的消费者使用方式,客户端封装了一套完整的消费订阅模型,包括每个消...
从 Kafka 导入数据
日志服务导入功能支持导入火山引擎消息队列 Kafka 集群和自建 Kafka 集群的数据。创建导入任务后,您可以通过日志服务控制台或服务日志查看导入任务详情。此外,日志服务还会为导入的日志数据添加以下元数据字段。 字... Kafka实例 ID 当您使用的是火山引擎消息队列 Kafka 版时,应设置为 Kafka 实例 ID。获取方式请参考查看实例详情。 是否需要鉴权 如果您使用的是公网服务地址,建议开启鉴权,并根据 Kafka 侧的配置完成如下配置。...
