R - 对缺失年份处理正确的移动平均
 社区干货
社区干货
基于Prometheus的企业级监控体系探索与实践|社区征文
本文回顾我们基于Prometheus对微服务监控体系的一些探索和实践。Prometheus是CNCF基金会管理的第二个毕业项目(第一个是Kubernetes),由于其良好的架构设计和完善的生态,迅速成为了监控领域的主流解决方案,尤其是在... Prometheus性能不足:原生Prometheus并不支持高可用,也不能做横向扩缩容,当集群规模较大时,单一Prometheus会出现性能瓶颈,无法正常采集数据。- 运维难度大:每一级Prometheus都是单独管理的,缺乏全局管理工具。-...
火山引擎ByteHouse基于云原生架构的实时导入探索与实践
再小的节点故障率也会导致一定量的故障处理单,而本地存储的运维门槛加剧了故障处理成本,尤其对于单副本集群,节点故障甚至会导致丢数据的风险;其次,分布式架构的读写耦合导致查询和导入存在资源竞争的问题;另外,由于本地存储reshuffle功能的成本问题,分布式架构的扩容成本非常高,而且容易导致线上服务IO热点,进而影响整个集群的稳定性。最后,由于无中心化节点以及事务的缺失,一致性问题是目前社区最为人吐槽的缺陷。![picture....
Cloud Shuffle Service 在字节跳动 Spark 场景的应用实践
平均的 Fetch Chunk 大小甚至远远小于 1K ,量级是非常非常小的。![]()再看一个混部集群中 Spark 作业的 Shuffle Fetch-Failure 的实时监控。下图监控中每个点的含义是——在这个时刻处于 Running 状态的 Application 的 Fetch-Failure 次数的总和。![]()上文提到,每一个 Fetch-Failure 都可能意味着一定时间的超时等待和计算资源空跑,同时还可能意味着触发 Stage 重算,甚至作业的失败。所以,解决这个问题对于提升 Spar...
项目经验分享:机器学习在智能风控中的应用|社区征文
本项目的初衷是解决传统风险控制的一些缺陷。比如,传统方法一般采用系统及静态模型进行实时监控和预测,无法适应灵便的使用场景;此外,处理规模性数据的效率很低,无法提供精确的风险评估和投资决策。基于数据发掘算法... 处理缺失值等工作,这些工作虽然枯燥乏味,但是也是不能省略的,提供的数据质量较低会直接导致机器学习的失败。下面我展示数据清洗部分代码。```# 数据清洗transaction_data = transaction_data.drop_duplicates(...
 特惠活动
特惠活动
 R - 对缺失年份处理正确的移动平均-优选内容
R - 对缺失年份处理正确的移动平均-优选内容
 R - 对缺失年份处理正确的移动平均-相关内容
R - 对缺失年份处理正确的移动平均-相关内容
项目经验分享:机器学习在智能风控中的应用|社区征文
本项目的初衷是解决传统风险控制的一些缺陷。比如,传统方法一般采用系统及静态模型进行实时监控和预测,无法适应灵便的使用场景;此外,处理规模性数据的效率很低,无法提供精确的风险评估和投资决策。基于数据发掘算法... 处理缺失值等工作,这些工作虽然枯燥乏味,但是也是不能省略的,提供的数据质量较低会直接导致机器学习的失败。下面我展示数据清洗部分代码。```# 数据清洗transaction_data = transaction_data.drop_duplicates(...
字节跳动 EB 级 Iceberg 数据湖的机器学习应用与优化
相比于 BERT 的 3.4 亿个参数,GPT-3 的模型参数数量飙升至 1750 亿个。这一巨大的增长引发了广泛的关注,并且使得 GPT-3 在自然语言处理任务中取得了令人瞩目的成就。 然而随着模型参数的增长,模型的大小也成... 为了解决这个问题,人们开始尝试模型小型化的方法。Chinchilla 就是一种模型小型化的尝试,相较于其前代模型,将模型参数缩小了 4 倍,但样本量却增大了 4 倍,这种方法试图在保持相对较小的模型规模的同时利用更多的数...
崩溃趋势
然后分别计算每个时间粒度范围内的影响用户比例 将上一步获取到的影响用户比例相加后求平均,得出平均影响用户比例 用户数量计算通过uniq(device_id)得出 平均影响用户比例 时间范围内的crash影响用户数量 / sess... issue处理状态和处理人。 崩溃详情 崩溃指标 筛选维度同列表。 上报趋势、多维分析重在分析单个issue内容的分布。 多维分析右上角可切换维度展示。 标签管理可以配置自定义标签,格式为key-value。配置好的标签可打...
浅谈AI机器学习及实践总结 | 社区征文
分组和解决问题的技术。(机器学习是一种从数据中生产函数,而不是程序员直接编写函数的技术)说起函数就涉及到自变量和因变量,在机器学习中,把自变量叫做特征(feature)多个自变量分别可以定义为X1,X2..Xn,因变量叫... 判断是否正确等,判断两款运营策略哪种更有效。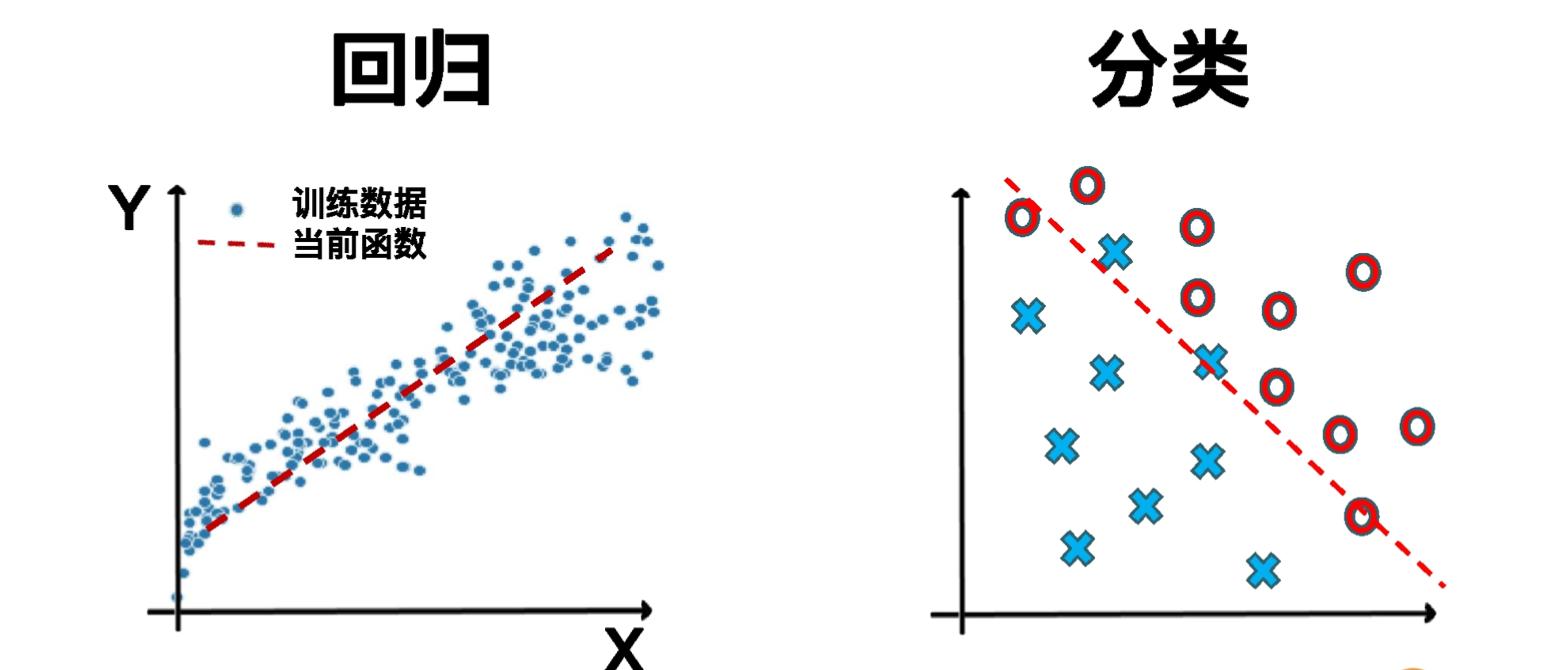分类算法:逻辑回归、决策树分类、...
火山引擎 DataLeap 计算治理自动化解决方案实践和思考
=&rk3s=8031ce6d&x-expires=1714580457&x-signature=mvQuvfIrTYIK7xANIXDuIQXaBJ0%3D) 在手动调参的过程中,我们常常面临以下困境:- **系统复杂度**:大数据计算系统与数据处理架构涵盖多种技术和组件,对... **专业知识缺乏**:通常由数据分析师来执行优化任务,但他们更侧重于业务场景而非底层逻辑。因此,我们希望通过自动化方案沉淀专业知识,提供一站式解决方案。- **一致性与可重复性缺失**:不同人员操作可能...
Cloud Shuffle Service 在字节跳动 Spark 场景的应用实践
下图是字节跳动内部一个 Spark 作业的 Shuffle Chunk Size 情况。这个作业只有 400 兆的 Shuffle 数据,但是它的 M 乘以 R 量级是 4 万乘 4 万。简单算一下,在这个例子中,平均的 Fetch Chunk 大小甚至远远小于 1K ,... 超时甚至引发 Stage Retry;* 磁盘 IOPS 无法在操作系统层面进行隔离,Shuffle 过程中不同 Application 作业会互相影响;* 在离线混部场景下,我们希望利用在线服务业务低峰期的 CPU,但缺少对应的磁盘资源。...
规则管理
存储场景:治理对象为火山引擎 E-MapReduce(EMR)Hive 表或湖仓一体分析服务(LAS)表相关的治理。 计算场景:治理对象为数据开发项目中任务相关的治理。 质量场景:治理对象为 EMR Hive 、LAS 表或任务相关的治理。 *... 对应的优化建议,用于在检测结果中展示建议详情,以提供治理行动参照。 *治理操作 依据选择的规则条件,您可根据实际情况,选择添加不同的治理操作: 表类型推荐操作:修改TTL 删除表 补齐元信息 处理表风险 更改存储格...
字节跳动 EB 级 Iceberg 数据湖的机器学习应用与优化
相比于 BERT 的 3.4 亿个参数,GPT-3 的模型参数数量飙升至 1750 亿个。这一巨大的增长引发了广泛的关注,并且使得 GPT-3 在自然语言处理任务中取得了令人瞩目的成就。然而随着模型参数的增长,模型的大小也成为... 为了解决这个问题,人们开始尝试模型小型化的方法。Chinchilla 就是一种模型小型化的尝试,相较于其前代模型,将模型参数缩小了 4 倍,但样本量却增大了 4 倍,这种方法试图在保持相对较小的模型规模的同时利用更多的数...
构建满足流批数据质量监控用火山引擎DataLeap
是否存在缺失的情况。数据缺失主要包括记录的缺失和记录中某个字段信息的缺失,两者都会造成统计结果不准确,所以说完整性是数据质量最基础的保障。在做监控时,需要考虑两个方面:数据条数是否少了;某些字段的取值是否... **User Story 3**某内部指标平台,业务数据由 Hive 定期同步到 ClickHouse;希望每次同步任务后检查 Hive 与 ClickHouse 中的指标是否一致。通过上面的介绍,大家应该也大致清楚了当前数据质量需要解决的问题。可...
