RDMA写操作和队列对关系是什么?
 社区干货
社区干货
火山引擎大规模机器学习平台架构设计与应用实践
**超强网络性能:** 机内 600GBps 双向 NVLink 通道,800Gbps RDMA 网络高速互联,支持 GPU Direct Access。 - **并行文件系统 vePFS:** 百 Gb 带宽,亚毫秒延迟,支持数亿小文件随机读取。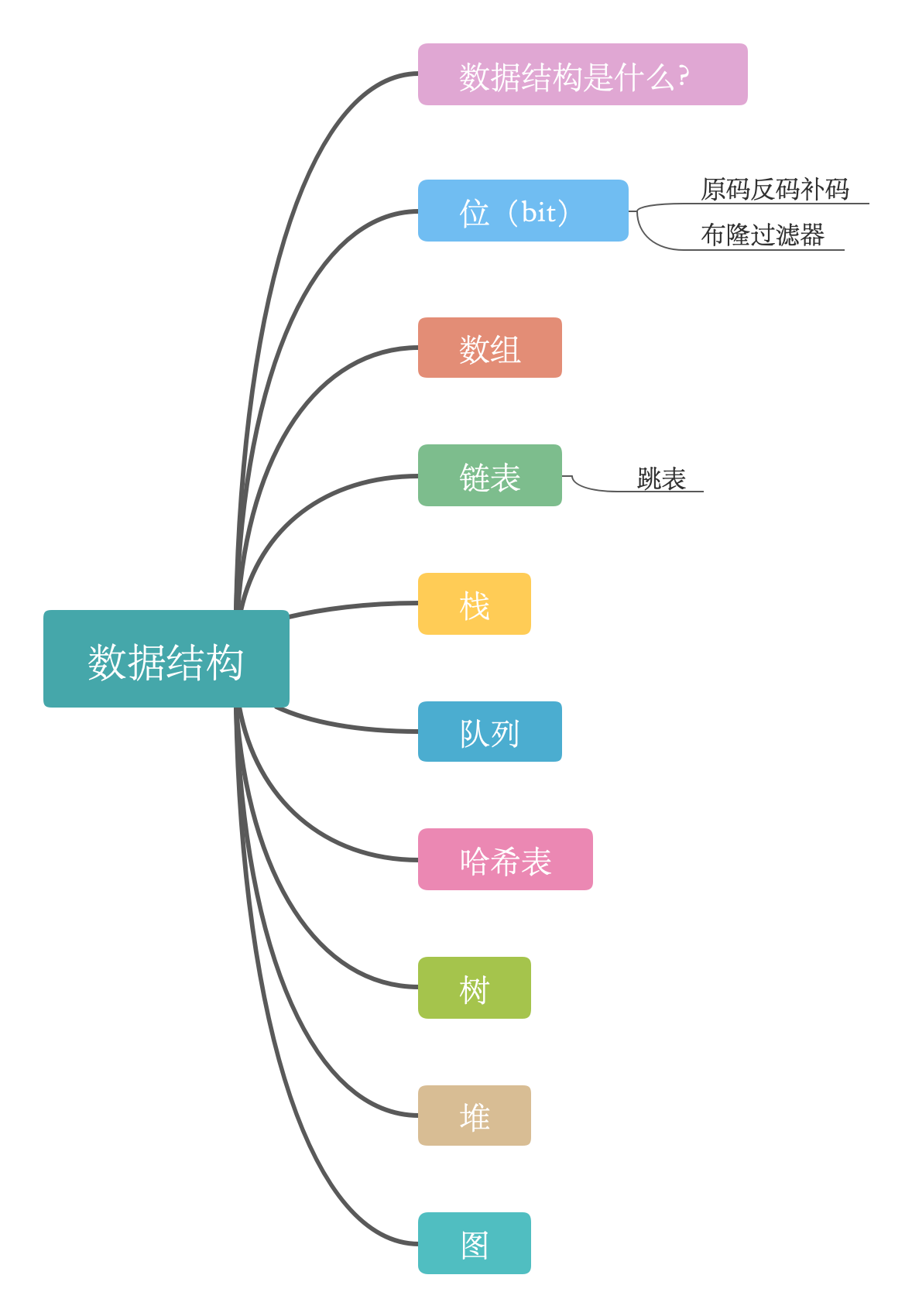# 数据结构是什么?> 程序 = 数据结构 + 算法是的,上面这句话是非常经典的,程序由数据结构以及算法组成,当然数据结构和算法也是相... **何为逻辑结构和存储结构?****数据元素之间的逻辑关系,称之为逻辑结构**,也就是我们定义了对操作对象的一种数学描述。但是我们还必须知道在计算机中如何表示它。**数据结构在计算机中的表示(又称为映像),称之为...
ByteFUSE的演进与落地
队列业务,符号表业务以及编译业务等,字节内部部署机器和日常挂载点均已**达到万级规模**,**总吞近百GB/s,容量十几PB**,其性能与稳定性能够满足业务需求。## 背景ByteNAS是一款全自研、高性能、高扩展,多写多读... Mount/Umount操作会在CSI-Dirver中启动/销毁FUSE Client,CSI-Driver会记录每个挂载点的状态,当CSI-Drvier异常退出重启时会recover所有挂载点来保证高可用性。- **FUSE** **Client:** 即上面提到的ByteFUSE Daem...
 特惠活动
特惠活动
 RDMA写操作和队列对关系是什么?-优选内容
RDMA写操作和队列对关系是什么?-优选内容
 RDMA写操作和队列对关系是什么?-相关内容
RDMA写操作和队列对关系是什么?-相关内容
火山引擎大规模机器学习平台架构设计与应用实践
**超强网络性能:** 机内 600GBps 双向 NVLink 通道,800Gbps RDMA 网络高速互联,支持 GPU Direct Access。 - **并行文件系统 vePFS:** 百 Gb 带宽,亚毫秒延迟,支持数亿小文件随机读取。# 数据结构是什么?> 程序 = 数据结构 + 算法是的,上面这句话是非常经典的,程序由数据结构以及算法组成,当然数据结构和算法也是相... **何为逻辑结构和存储结构?****数据元素之间的逻辑关系,称之为逻辑结构**,也就是我们定义了对操作对象的一种数学描述。但是我们还必须知道在计算机中如何表示它。**数据结构在计算机中的表示(又称为映像),称之为...
ByteFUSE的演进与落地
队列业务,符号表业务以及编译业务等,字节内部部署机器和日常挂载点均已**达到万级规模**,**总吞近百GB/s,容量十几PB**,其性能与稳定性能够满足业务需求。## 背景ByteNAS是一款全自研、高性能、高扩展,多写多读... Mount/Umount操作会在CSI-Dirver中启动/销毁FUSE Client,CSI-Driver会记录每个挂载点的状态,当CSI-Drvier异常退出重启时会recover所有挂载点来保证高可用性。- **FUSE** **Client:** 即上面提到的ByteFUSE Daem...
干货 | 基于ClickHouse的复杂查询实现与优化
我们也进行了功能和性能上的增强,例如支持一个Stage处理多个Join,这样便可以减少Stage的数目和一些不必要的传输,用一个Stage就可以完成整个Join的过程。InterpreterPlanSegment的执行会上报对应的状态信息,如出现执行异常,会将异常信息报告给查询片段调度器,调度器会取消Query其他的Stage的Worker执行。ExchangeManager是PlanSegment数据交换的媒介,能平衡数据上下游处理的能力。整体而言,我们的设计采用Push与队列的方式,当上...
年终学习大礼包|云原生大数据知识地图
更好的隔离控制:限制每个 Pod 的 CPU 时间片和内存使用量- 更灵活的资源使用方式:空闲资源利用和队列抢占**全局资源湖**- ResLake 具有资源的全局视图、全局资源池和 Quota 管控- 不限机房、不限集... 调用关系等,从而可以在故障时定位到具体出问题的调用环节;- **开源组件管理**:通过 Helm Chart 来对组件进行部署,通过 Operator 对运行组件进行整个生命周期的管理,包括开始、终止、清理等一系列操作。因此,开源...
火山引擎大规模机器学习平台架构设计与应用实践
800Gbps RDMA 网络高速互联,支持 GPU Direct Access。* **并行文件系统 vePFS**:百 Gb 带宽,亚毫秒延迟,支持数亿小文件随机读取。、Gang 调度、堆叠调度** 等。