给托管标识授予写入Cosmos DB容器的索引策略的权限
 社区干货
社区干货
打造新一代云原生"消息、事件、流"统一消息引擎的融合处理平台 | 社区征文
(https://p3-volc-community-sign.byteimg.com/tos-cn-i-tlddhu82om/0112eea951e04b3b8e730cdb48d22d48~tplv-tlddhu82om-image.image?=&rk3s=8031ce6d&x-expires=1714580429&x-signature=4n%2B5DYe0rNIDdh4ECZAZTj... 采用存储计算分离的模式可以避免直接将后端存储服务暴露给客户端。这样做有助于实现对流量的控制、隔离、调度、权限管理以及协议转换等功能。通过将存储和计算分离,可以更好地管理和保护后端存储服务,并提供一种更...
干货|8000字长文,深度介绍Flink在字节跳动数据流的实践
将埋点打上不同的动作类型标识。处理之后的埋点一般称之为UserAction,UserAction数据会和服务端展现等数据在推荐Joiner任务的分钟级窗口中进行拼接Join,产出Instance训练样本。:关键技术与总结
hive_db也是一类元数据。Type可具备继承关系。按面向对象的编程思想,可以理解type为一个Class。- 实例(Entity):代表一个type的具体事例。一个entity可能作为一个属性存在于另一个entity中,例如hive_table中的db... 写入不同的存储,供给在线搜索模块使用。- 在线部分:分为搜索理解、召回、精排三个主要阶段,步骤和概念上与通用搜索引擎对齐。针对上面分析的特点,火山引擎 DataLeap 研发人员在搜索优化时,有两个对应的策略:...
数据库顶会 VLDB 2023 论文解读:Krypton: 字节跳动实时服务分析 SQL 引擎设计
(https://p6-volc-community-sign.byteimg.com/tos-cn-i-tlddhu82om/91d64f61c95a4556967fa8db45cb22de~tplv-tlddhu82om-image.image?=&rk3s=8031ce6d&x-expires=1714580441&x-signature=tewOtvwR5hvKWyU6bVoujGL6R8o%3D)如图所示,Krypton 支持两层分区,第一层叫做 Partition,第二层我们称为 Tablet,每一层都支持 Range/Hash/List 的分区策略。每个 Tablet 都包含一组 Rowsets,每个 Rowset 内部数据按照 Schema 中定义的 Sort...
 特惠活动
特惠活动
 给托管标识授予写入Cosmos DB容器的索引策略的权限-优选内容
给托管标识授予写入Cosmos DB容器的索引策略的权限-优选内容
 给托管标识授予写入Cosmos DB容器的索引策略的权限-相关内容
给托管标识授予写入Cosmos DB容器的索引策略的权限-相关内容
从 ClickHouse 到 ByteHouse:实时数据分析场景下的优化实践
**问题一:写入吞吐量不足****挑战**:在有大量辅助跳数索引的场景下,索引的构建严重影响写入吞吐量。**解决方案**:异步构建索引。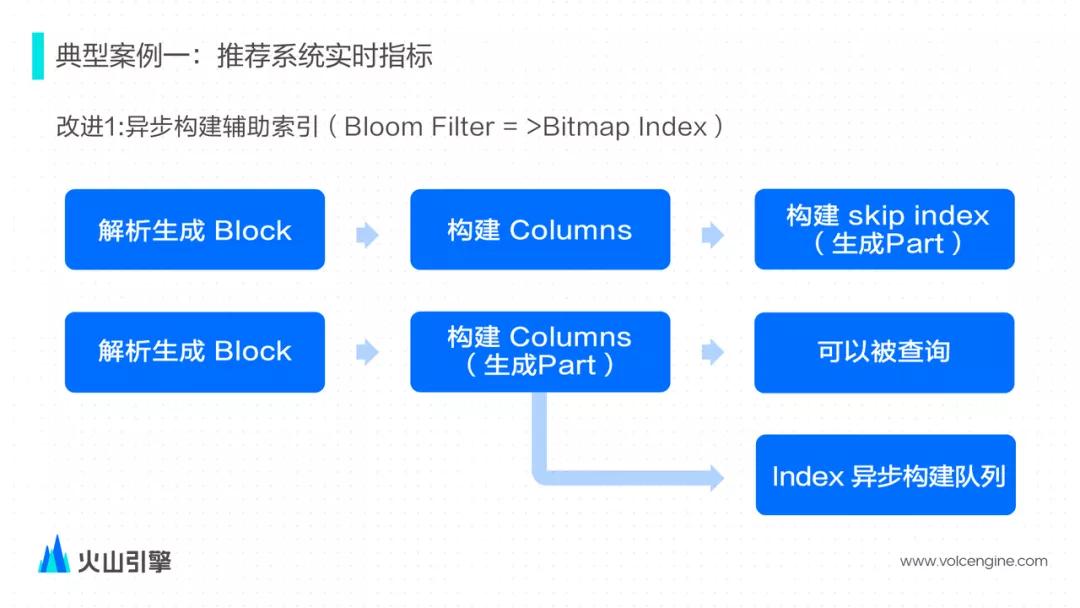社区版本的实现里的具体逻辑如下:- 解析输入数据生成内存中数据结构的 Block;- 然后切分 Block,并按照表的 schema 构建 columns 数据文件;- 最后扫描...
「火山引擎」数智平台 VeDI 数据中台产品双月刊 VOL.03
新增云原生 veDB MySQL 数据源,支持 veDB MySQL_to_LAS 通道作业。 - 新增 CloudFS 离线并优化读取能力,支持 CFS_to_LAS 通道作业。- **【新增开发规范及流水管理】** - 智能市场新增建表... **Bucket Index**:轻量且高效的索引方式,在大规模数据入湖、探索分析等场景中提供高效的写入和查询能力。- **Column Family**:解决部分列更新场景的性能问题,典型场景例如 GDPR 用户信息列删除。- **SQL...
「火山引擎数据中台产品双月刊」 VOL.06
【**新增权限管理功能**】 - 支持对表的脱敏权限进行权限授予、授权列表查看、历史授权的编辑、删除。 - 用户需要同时具备数据权限及加脱敏权限,才可查看未被脱敏的原始数据。- **【新增血缘查询功能】** - 支持记录 SQL 作业中参与计算的所有表,并在作业管理页面展示。- 【**优化** **JDBC** **连接功能】** - JDBC 连接功能优化,增加功能说明 & 连接教程,提升用户体验。### **云原生...
字节跳动基于数据湖技术的近实时场景实践
字节数据湖拥有良好的元数据管理能力,并在此之上实现了索引。使用行、列存储并用的存储格式,为高性能读写提供坚实的基础。 - 字节数据湖新增了多源拼接功能,对于需要融合多种数据源或者构建集市型数据集的场... 我们采取的策略是设计一种近实时的计算架构,在保留离线计算数据的丰富度和复杂度的同时,又兼顾实时计算的时效性高的特点,将两者进行优势互补。这种近实时的方案,能满足刚才提到的分析型、运维型的业务需求。另一...
基于火山引擎 EMR 构建企业级数据湖仓
流式写入的效率不高,写入越频繁小文件问题就越严重; - 有一定的维护成本:使用 Table Format 的用户需要自己维护,会给用户造成一定的负担; - 与现有生态之间有一些 gap:开源社区暂不支持和 Table format 之间的... 而向量化则是 MonetDB 提出的,所以计算引擎的精细化也是沿着数仓开辟的路子在走。Spark 等 Hadoop 体系均走了 Codegen 的道路,因为 Java 做 Codegen 比做向量化要更容易一些。但是现在人们发现可能向量化是一个更好...
「火山引擎」数据中台产品双月刊 VOL.03
新增云原生 veDB MySQL 数据源,支持 veDB MySQL_to_LAS 通道作业。 - 新增 CloudFS 离线并优化读取能力,支持 CFS_to_LAS 通道作业。- **【新增开发规范及流水管理】** - 智能市场新增建表... **Bucket Index**:轻量且高效的索引方式,在大规模数据入湖、探索分析等场景中提供高效的写入和查询能力。- **Column Family**:解决部分列更新场景的性能问题,典型场景例如 GDPR 用户信息列删除。- **SQL...
干货|8000字长文,深度介绍Flink在字节跳动数据流的实践
将埋点打上不同的动作类型标识。处理之后的埋点一般称之为UserAction,UserAction数据会和服务端展现等数据在推荐Joiner任务的分钟级窗口中进行拼接Join,产出Instance训练样本。字节跳动数据集成系统目前支持了几十条不同的数据传输管道,涵盖了线上数据库,例如Mysql Oracle和MangoDB;消息队列,...
字节跳动数据库的过去、现状与未来
Serverless DB、MemDB 等产品和技术,在运维体系上,也引入 AI 技术,使得运维更加智能化。## 字节跳动数据库的“过去”第一代数据库系统架构主要分三层,示意图如下: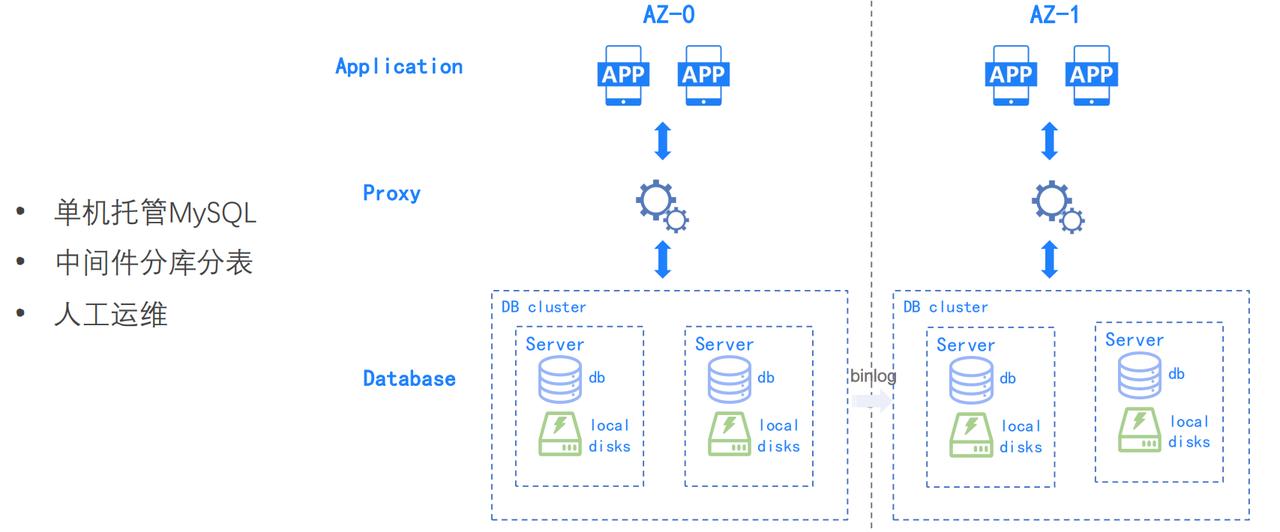- **Application 层:** 前文提到的 1000 万个容器及其构成的 10 万个微服务都部署在应用层;- **Proxy 层:** 代理层主要负责...
