Dotnetefcore中是否可以有两个主键对应同一导航属性?
 社区干货
社区干货
干货|湖仓一体架构在火山引擎LAS的探索与实践
通常可以支持服务在普通硬件上面去部署,整体的计算和存储的扩展性都得到了解决。基于开源技术生态,多个大型公司也参与到数据湖技术发展中来,整体生态繁荣度也在逐步提升。 但在这一阶段凸显出了一个问题... 从而可以快速地将这种小规模的数据去添加到Append Log。在读取时,通过Compaction就可以将LogFile和BaseFile里边的数据进行Merge去重,从而达到数据更新的效果。 针对日志数据入湖,通常来说是不需要主键的...
干货 |揭秘字节跳动基于 Doris 的实时数仓探索
经过了两个月的开发,目前已经支持三大数据组织模式,也支持数据存放在 HDFS、S3 和 TOS 上,数据格式也支持最常见的 Parquet、ORC、TEXT等。**基于这些能力,我们在性能上也做了持续的优化。** 例如,我们做了 table scan 里面最常见的几类优化,包括并发读取、RunTimeFilter、列裁剪、分区裁剪、Parquet 和 ORC 中的谓词下推、数据预取等。做了这些有效的优化以后,相对于 Trino, 在同样的场景下,也就是 Trino + HDFS 或者 Trino + ...
「火山引擎」数智平台 VeDI 数据中台产品双月刊 VOL.03
四款数据中台产品的功能迭代、重点功能介绍、平台最新活动、技术干货文章等多个有趣、有料的模块内容。> > 双月更新,您可通过关注「字节跳动数据平台」官网公众号、添加小助手微信加入社群获取产品动态~> > 接... 又支持主键更新的表引擎。它解决了社区版 ClickHouse 不能支持高效更新操作的痛点,帮助业务更简单地开发实时分析应用。HaUniqueMergeTree 引擎具有以下特点:- 用户配置唯一键,提供 upsert 更新写语义,查询自...
DataLeap 数据资产实战:如何实现存储优化?
每行由多个列值(column-value)对组成,也会对列进行排序和过滤,如果是非 column-family 的类型存储,则需要另行适配,适配时数据模型有两种方式:Key-Column-Value 和 Key-Value。**KCV 模型...
 特惠活动
特惠活动
 Dotnetefcore中是否可以有两个主键对应同一导航属性?
-优选内容
Dotnetefcore中是否可以有两个主键对应同一导航属性?
-优选内容
 Dotnetefcore中是否可以有两个主键对应同一导航属性?
-相关内容
Dotnetefcore中是否可以有两个主键对应同一导航属性?
-相关内容
湖仓一体架构在 LAS 服务的探索与实践
多个计算组件,或者多种架构范式导致的架构负担,让企业能够更专注地去解决他们的业务价值。; **●** FileGroup:也是 Hudi 的一个概念,可以理解为一个文件组,这个文件组中包含列存的 base file 和行存的 log file,主键表中相同主键的数据会被分配到同一...
浅谈AI机器学习及实践总结 | 社区征文
(机器学习是一种从数据中生产函数,而不是程序员直接编写函数的技术)说起函数就涉及到自变量和因变量,在机器学习中,把自变量叫做特征(feature)多个自变量分别可以定义为X1,X2..Xn,因变量叫做标签(label),可定义为... 验证模型是否能够被推广、泛化,评估模型是否过拟合测试集,用来评估模最终模型的泛化能力,相当于举一反三的能力## 机器学习分类主要分类是根据机器学习在训练过程中是否有标签。- 监督学习:训练的数据集全...
干货 | 实时数据湖在字节跳动的实践
(https://p3-volc-community-sign.byteimg.com/tos-cn-i-tlddhu82om/d060bf8fde3440d698788ef0c4f38eba~tplv-tlddhu82om-image.image?=&rk3s=8031ce6d&x-expires=1716049301&x-signature=yOPDyYgy%2BWW7UoOu0xFqCA... 其中最主要的两个问题是:首先,数据集市只保留了部分属性,只能解决预先定义好的问题;另外,数据集市中反映细节的原始数据丢失了,限制了通过数据解决问题。从解决问题的角度出发,希望有一个合适的存储来保存这些明细的...
揭秘|字节跳动基于Hudi的实时数据湖平台
一次写入过程对应时间线中的一个 commit,记录本次写入修改的文件。相较于传统数仓,Hudi 要求每条记录必须有唯一的主键,并且同分区内,相同主键只存在在一个 file group中。底层存储由多个 file group 构成,有其特定... 数仓场景中,对于一张底层分析表,往往是通过多个数据源的数据组合拼接而成,每个数据源都包含相同的主键列,和其他不同的属性列。在传统数仓场景中,需要先将每个数据源数据 dump 成 Hive 表,然后再将多张 Hive 表按主...
干货|ByteHouse如何将OLAP性能提升百倍?
(https://p6-volc-community-sign.byteimg.com/tos-cn-i-tlddhu82om/a814681be2524f5981ae1e092ef1fc9d~tplv-tlddhu82om-image.image?=&rk3s=8031ce6d&x-expires=1716049231&x-signature=%2BH6MXn6nNIlZ8J0jYSKqXz... ByteHouse优化器融合了两个阶段,先展开所有分布式计划,然后基于全局代价生成最优解,并减少shuffle。其中,ByteHouse也会通过表的元数据信息和属性推论,利用数据分布来减少agg和join的shuffle开销。 优化器...
字节跳动实时数据湖构建的探索和实践
还可以进一步降低计算成本、提高效率。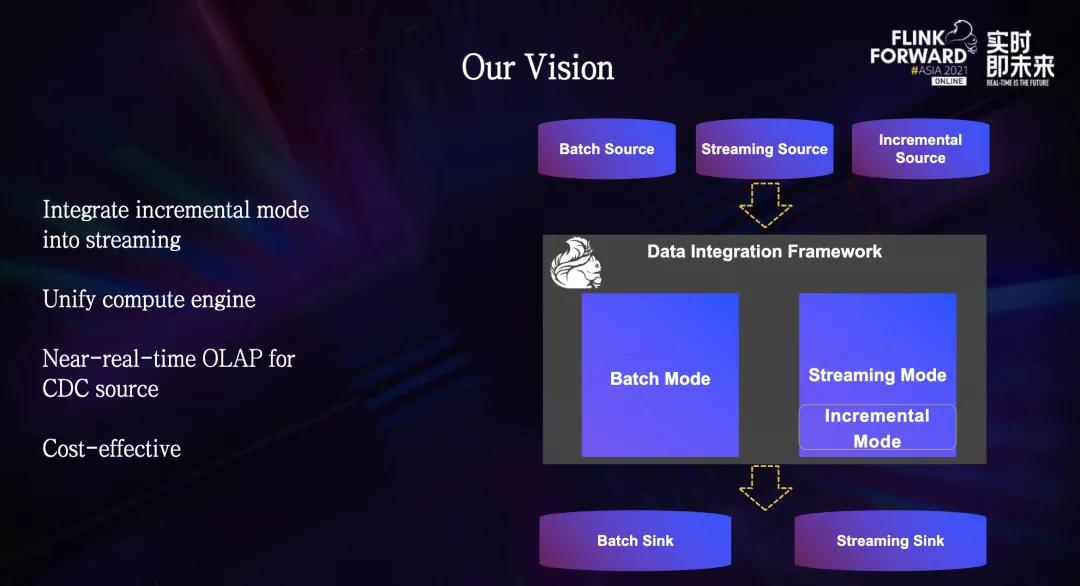经过一番探索,我们关注到了正在兴起的数据湖技术。## 关于数据湖技术选型的思考我们的目光集中在了Apache软件基金会旗下的两款开源数据湖框架Iceberg和Hudi中。Iceberg和Hudi两款数据湖框架都非常优秀。但两个项目被创建的目的是为了解决不同的问题,所...
字节跳动 EB 级 Iceberg 数据湖的机器学习应用与优化
在字节跳动的离线训练样本存储中,数据总量已经达到了 EB 级,每日还在以 PB 级的速度增长。这些数据被用于支持广告、搜索、推荐等模型的训练,覆盖了多个业务领域;这些数据还支持算法团队的特征调研、特征工程,并为模... (https://p6-volc-community-sign.byteimg.com/tos-cn-i-tlddhu82om/4aff02a315244154bce21def052cf60b~tplv-tlddhu82om-image.image?=&rk3s=8031ce6d&x-expires=1716049291&x-signature=uXlxuuHd%2BLgE9sQuZxgwef...
干货|字节跳动基于 Apache Hudi 的多流拼接实践
字节跳动存在较多业务场景需要基于具有相同主键的多个数据源实时构建一个大宽表,数据源一般包括 Kafka 中的指标数据,以及 KV 数据库中的维度数据。业务侧通常会基于实时计算引擎在流上做多个数据源的 JOIN 产出... **Merge BaseFile and LogFile:**Hudi 现有默认逻辑是对于每一条存在于 BaseFile 中的 Record,查看 Map 中是否存在 key 相同的 Record,如果存在,则用 Map 中的 Record 覆盖 BaseFile 中的 Record。在多流拼接中,...
