提供的值与表定义不匹配。ID未自动生成。
 社区干货
社区干货
基于 Flink 构建实时数据湖的实践
目前 Iceberg 提供的 Flinksink 并不支持 Schema 变更,Iceberg 默认的 Flinksink 会给每一个需要写入的 Parquet 文件创建一个 Streamwrtier,而这个 Streamwriter 的 Schema 是固定的,否则 Parquet 文件的写入就会报... 上图示例中原始 Schema 是 id、name、age,在 Schema 匹配情况下的写入不会报错,所以 Row 1 可以写入;Row 2 写入时由于长度不符合,所以会报错:Index out of range;Row 3 写入时,由于数据类型不匹配,会报错:Class ca...
轻量级 Kubernetes 多租户方案的探索与实践
社区的 Kubernetes Multi-tenancy Working Group 定义了三种 Kubernetes 的多租户模型:- 第一种是 **Namespaces as a Service**,这种模型是多个租户共享一个 Kubernetes 集群,每个租户被限定在自己的 Namespac... 比如租户内部再想细分 Namespace 或者租户想要创建 CRD 资源,这些都是 Cluster scope 的资源,需要系统管理员来协调,也就是说它的用户体验是有损的。其次,Cluster 或 Control plane 的隔离方案引入了过多的额外开...
基于火山引擎微服务引擎 MSE 的全链路灰度落地实践
是火山引擎提供的一款面向微服务全生命周期的一站式微服务解决方案。产品提供开源增强的 Nacos 注册发现、配置管理,兼容原生 Spring Cloud 、gRPC 及 Service Mesh 架构丰富微服务治理能力。来源 | 火... 标识染色和流量路由能力。feature\_a 在服务 B、服务 D 没有对应特征版本(同理 feature\_b 在服务 A、服务 C 也无对应特征版本),针对未匹配灰度规则的流量,需要将流量自动回流至基线版本,保障业务逻辑闭环。同...
ByteHouse MaterializedMySQL 增强优化
同步一个 MySQL 库至 ClickHouse 的示例创建语句如下:```CREATE DATABASE db_name ENGINE = MaterializedMySQL(...)SETTINGS materialized_mysql_tables_list='user_table,catalog_sales'TABLE OVERRIDE user... 不兼容,在 ClickHouse 端执行会报错中断同步任务。可以通过设置 skip_ddl_patterns 参数,用 1 个或多个正则表达式将匹配的 DDL 语句过滤掉,从而避免了报错和中断同步任务。**系统日志表**ByteHouse 提供两个...
 特惠活动
特惠活动
 提供的值与表定义不匹配。ID未自动生成。
-优选内容
提供的值与表定义不匹配。ID未自动生成。
-优选内容
 提供的值与表定义不匹配。ID未自动生成。
-相关内容
提供的值与表定义不匹配。ID未自动生成。
-相关内容
干货| 火山引擎在行为分析场景下的ClickHouse JOIN优化
**ID**分shard存储。 ``` --列出了主要的字段信息 CREATE TABLE tob_apps_all ( `tea_app_id` UInt32, --应用ID `... 从右表hash table匹配数据* 优点是:速度快 缺点是:右表数据量大的情况下占用内存### **Merge join*** 对右表排序,内部 block 切分,超出内存部分 flush 到磁盘上,内存大小通过参数设定* 左表基于 blo...
Redis String 实现 ID 生成器,底层为啥用 SDS 存储数据?| 社区征文
比如通过 `char *s = "MageByte"`定义字符串变量。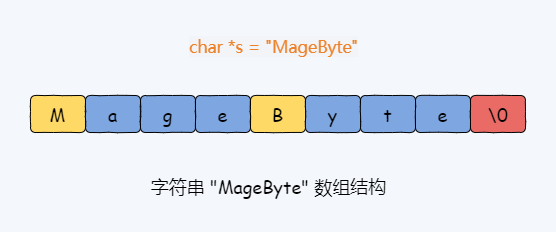图 2-1注意,**数组的最后一个字符串是 "\0",它表示字符串的结束**。因为 C 语言标准库 `string.h`中的字符串有以下几点不足,所以我才设计了 SDS。1. C 语言使用 `char*` 字符串数组来实现字符串,在创建字符串的时候就要需要手动检查和分配字符串空间。由于没有 `length`属性记录字符串长...
sonic:基于 JIT 技术的开源全场景高性能 JSON 库
可以同时结合模型定义(Go struct)与 JSON 语法,将读取到的 value 绑定到对应的模型字段上去,同时完成数据解析与校验;- **查找(get)& 修改(set)** :指定某种规则的查找路径(一般是 key 与 index 的集合),获取需... 自动生成跳转表,加速 generic decoding 的分支跳转; - 使用寄存器传递参数(当前 Go Assembly 并未支持,见“SIMD & asm2asm”章节)。### Lazy-load对于大部分 Go JSON 库,泛型编解码是它们性能表现最差的...
火山引擎ByteHouse基于云原生架构的实时导入探索与实践
由于社区官方不会做云服务的限制,所以社区开源的只是分布式架构。社区的开源实现是一个经典的分布式架构。首先它是无中心的多节点集群,有分片(shard)的概念:每个集群有多个shard,每个shard相互独立;集群内每张表... 保证一致性和原子性。由于架构的升级和演进,实时导入技术也在新架构下做了适配和优化。下面仍旧以Kafka导入为例,看看ByteHouse云原生新架构下的实时导入的实现。当用户创建一张Kafka表消费时,集群会在Server上...
基于 Flink 构建实时数据湖的实践
目前 Iceberg 提供的 Flinksink 并不支持 Schema 变更,Iceberg 默认的 Flinksink 会给每一个需要写入的 Parquet 文件创建一个 Streamwrtier,而这个 Streamwriter 的 Schema 是固定的,否则 Parquet 文件的写入就会报... 上图示例中原始 Schema 是 id、name、age,在 Schema 匹配情况下的写入不会报错,所以 Row 1 可以写入;Row 2 写入时由于长度不符合,所以会报错:Index out of range;Row 3 写入时,由于数据类型不匹配,会报错:Class ca...
一口气看完43个关于 ElasticSearch 的使用建议
因为匹配到的时间一直在变化。因此, 可以从业务的角度来考虑是否一定要用 Now,尽量使用绝对时间值,不需要解析相对时间表达式且利用 Query Cache 能够提高查询效率。例如时间范围查询中使用 Now/h,使用小时级别的单... 聚合查询的中间结果和最终结果都会在内存中进行,嵌套过多,会导致内存耗尽。如:``` SearchSourceBuilder sourceBuilder = new SearchSourceBuilder(); // 创建主要查询 sourceBuilder....
CreateVpcEndpointService
调用CreateVpcEndpointService接口,创建一个终端节点服务。 调用说明单个终端节点服务在每个可用区默认最多可添加100个服务资源。 调试API Explorer您可以通过API Explorer在线发起调用,无需关注签名生成过程,快速... 未开通私有DNS私网域名功能时,该参数只能传入公网域名。 ClientToken String 否 123e4567-e89b-12d3-a456-42665544**** 客户端Token,用于保证请求的幂等性。 该参数值由客户端自动生成,确保不同请求的取值唯...
火山引擎ByteHouse:10亿数据、查询<10s,论基于OLAP搭建广告系统的正确姿势
越来越多的广告企业和从业者开始探索精细化营销的新路径,取代以往的全流量、粗放式的广告轰炸。精细化营销意味着要在数以亿计的人群中优选出那些最具潜力的目标受众,这无疑对提供基础引擎支持的数据仓库能力,提出了... 因为id\_tags中active\_users定义为BitMap64的类型, 数组值[1,3,5], [2,4,6]会被自动转化为BitMap64。之后的计算和存储都会是BitMap64类型。大批量文件导入时,我们可以利用ByteHouse提供的导入服务,目前离线(...
数据清洗
「订单表」中只有”商品id“,没有商品的具体信息,需要连接「商品信息表」,根据”商品id“匹配到”商品名称“、”商品品类“等信息。 离线任务 多表连接 将多张表根据某些字段联合成一张新表 将[学生表]、[成绩表]... 转换成“姓名-科目1成绩-科目2成绩-科目3成绩-科目4成绩-科目5成绩-科目6成绩”100行的数据。 离线任务 替换缺失值 将缺失的数据替换为该列的最大/最小/平均值、最高频值或自定义值 「订单表」中部分订单的“优惠金...
