如何删除哈希表中的数据?
 社区干货
社区干货
分布式数据缓存中的一致性哈希算法|社区征文
一致性哈希算法在分布式缓存领域的 MemCache,负载均衡领域的 Nginx 以及各类 RPC 框架中都有广泛的应用,它主要是为了解决传统哈希函数添加哈希表槽位数后要将关键字重新映射的问题。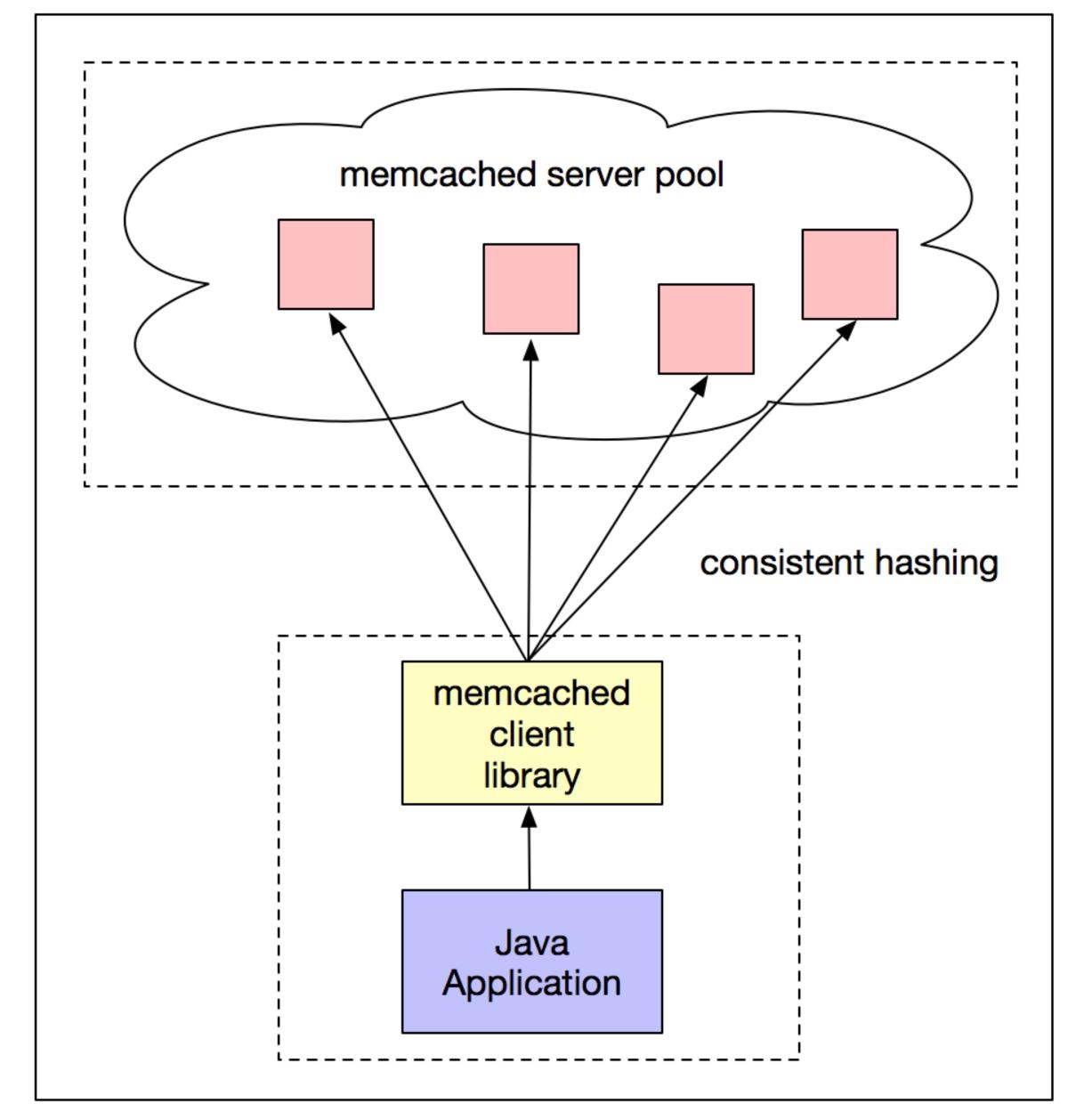本文会介绍一致性哈希算法的原理及其实现,并给出其不同哈希函数实现的性能数据对比,探讨 Redis 集群的数据分片实...
万字长文带你漫游数据结构世界|社区征文
将数据之间的关系表现在存储上,计算的时候可以较为高效的利用适配的算法,那么程序的运行效率肯定也会有所提高。常用的4种数据结构有:- 集合:只有同属于一个集合的关系,没有其他关系- 线性结构:结构中的数据... 那如何删除一个中间的节点呢?下面是具体的过程:或许你会好奇,`a5`节点只是指针没有了,那...
基于ClickHouse的复杂查询实现与优化|社区征文
若采用哈希表的方式进行去重,第二阶段需在Coordinator单机上去合并各个Worker的哈希表。这个计算量会很重且无法并行。**第二类,由于目前ClickHouse模式并不支持Shuffle,因此对于Join而言,右表必须为全量数据。** 无论是普通Join还是Global Join,当右表的数据量较大时,若将数据都放到内存中,会比较容易OOM。若将数据spill到磁盘,虽然可以解决内存问题,但由于有磁盘 IO 和数据序列化、反序列化的代价,因此查询的性能会受到影响。...
ByteHouse MaterializedMySQL 增强优化
[MaterializedMySQL数据库引擎](https://xie.infoq.cn/link?target=https%3A%2F%2Fclickhouse.tech%2Fdocs%2Fen%2Fengines%2Fdatabase-engines%2Fmaterialized-mysql%2F),用于将 MySQL 中的表映射到 ClickHouse 中... 该表引擎支持配置 UNIQUE KEY 唯一键,提供 upsert 更新写语义,源端数据的更新操作在目标端可以实时去重更新。不需要依赖_version、_sign 虚拟列来标记删除更新,简化了业务逻辑,提高了易用性。## 同步范围通过 ...
 特惠活动
特惠活动
 如何删除哈希表中的数据?
-优选内容
如何删除哈希表中的数据?
-优选内容
 如何删除哈希表中的数据?
-相关内容
如何删除哈希表中的数据?
-相关内容
数据结构
本文汇总数据库传输服务 DTS 的 API 接口中使用的数据结构定义详情。 AccountMapping账号信息。在 TaskType 取值为 DataMigration 、ProgressType 取值为 Account 时,可设置的参数信息。被以下接口引用: MySQL2MyS... 删除等操作,保证数据同步的完整性和一致性。取值如下: true:表示开启外键检查。 false:表示关闭外键检查。 true ETLSettings ETLSettings 否 ETL 参数配置。 ETLSettings ErrorBehaviorSettings ErrorBehaviorS...
数据结构
本文汇总云数据库 veDB MySQL 版的 API 接口中使用的数据结构定义详情。 AccountObject账号列表信息。被 DescribeDBAccounts 接口引用。 名称 类型 示例值 描述 AccountName String testuser 账号名称。 AccountType String Normal 账号类型: Super:高权限账号。 Normal:普通账号。 AccountPrivileges Array of AccountPrivilegeObject 请参见返回示例。 账号的权限信息。详细信息,请参见 AccountPrivilegeObject。 AccountP...
干货 | 基于ClickHouse的复杂查询实现与优化
若采用哈希表的方式进行去重,第二阶段需在Coordinator单机上去合并各个Worker的哈希表。这个计算量会很重且无法并行。**第二类,由于目前ClickHouse模式并不支持Shuffle,因此对于Join而言,右表必须为全量数据。**无论是普通Join还是Global Join,当右表的数据量较大时,若将数据都放到内存中,会比较容易OOM。若将数据spill到磁盘,虽然可以解决内存问题,但由于有磁盘 IO 和数据序列化、反序列化的代价,因此查询的性能会受到影响。...
基于 Flink 构建实时数据湖的实践
> 本文整理自火山引擎云原生计算研发工程师王正和闵中元在本次 CommunityOverCode Asia 2023 数据湖专场中的《基于 Flink 构建实时数据湖的实践》主题演讲。 ***云原生大数据特惠专场:https://www.volcengine.... Flink 1.17 引入了行级更新和删除的功能(FLIP-282),我们在此基础上增加了批量 Upate 和 Delete 操作,通过 RowLevelModificationScanContext 接口实现 Iceberg 的行级更新。实践过程中,通过在 Context 中记录了两个...
干货 | 实时数据湖在字节跳动的实践
因为它能够改变我们在 Hive 数仓中遇到的数据更新成本高的问题,支持对海量的离线数据做更新删除。**第二是智能的查询加速。**用户使用数据湖的时候,不希望感知到数据湖的底层实现细节,数据湖的解决方案应该能够自动地优化数据分布,提供稳定的产品性能。**第三是批流一体的存储。**数据湖这个技术出现以来,被数仓行业给予了厚望,他们认为数据湖可以最终去解决一份存储流批两种使用方式的问题,从而从根本上提升开发效率...
基于 Flink 构建实时数据湖的实践
本文整理自火山引擎云原生计算研发工程师王正和闵中元在本次 CommunityOverCode Asia 2023 数据湖专场中的《基于 Flink 构建实时数据湖的实践》主题演讲。实时数据湖是现代数据架构的核心组成部分,随着数... Flink 1.17 引入了行级更新和删除的功能(FLIP-282),我们也在此基础上增加了批量 Upate 操作和批量 Delete 操作,可以通过 RowLevelModificationScanContext 接口实现 Iceberg 的行级更新。实践过程中,通过在 Contex...
基于 Flink 构建实时数据湖的实践
本文整理自火山引擎云原生计算研发工程师王正和闵中元在本次 CommunityOverCode Asia 2023 数据湖专场中的《基于 Flink 构建实时数据湖的实践》主题演讲。实时数据湖是现代数据架构的核心组成部分,随着数... Flink 1.17 引入了行级更新和删除的功能(FLIP-282),我们也在此基础上增加了批量 Upate 操作和批量 Delete 操作,可以通过 RowLevelModificationScanContext 接口实现 Iceberg 的行级更新。实践过程中,通过在 Contex...
干货 | 实时数据湖在字节跳动的实践
支持对海量的离线数据做更新删除。**第二是智能的查询加速。** 用户使用数据湖的时候,不希望感知到数据湖的底层实现细节,数据湖的解决方案应该能够自动地优化数据分布,提供稳定的产品性能。**第三是批流一体的... 更加注重数据的实时属性或者说流属性的一个数据湖发展方向。当然,正如业界对于数据湖的解读一直在演变,我们对数据湖的解读也不会局限于以上场景和功能。# **2. 落地实时数据过程中的挑战和应对方式**接下来介绍...
表管理
Hash:表示该索引可以通过哈希函数将数据值转换为唯一的哈希码。这种索引只能用于等值查询。 spgist:表示该索引是一种可以使用任何非叠加分区方法的索引类型,可以处理点数据并做到有效的范围查找。 是否并发 按需勾选是否并发。勾选后在创建索引的过程中允许正常的读写操作,降低阻塞时间。 备注 (可选)填写索引的备注信息。备注信息建议与您的业务相关。 说明 当需要删除某个索引时,您可以选择目标索引,单击删除索引。 在外...
