如何拆包一个包含字典的列表并合并不同键对应的多个值?
 社区干货
社区干货
系统集成在一些特定行业的相关概念
不同于企业现有的操作型数据库;其次数据仓库是对多个异构数据源的有效集成,集成后按主题重组,且放在数据仓库中的数据一般不再修改。数据仓库系统结构包含四个层次:l 数据源,数据仓库系统的基础;l 数据的存... 慢数据库追踪Top10:慢事物列表展示了一小时内(可选)响应时间超过250ms并且排列前十的数据库请求次数与平均响应时间等信息。缓存事务主要包括redis调用明细,耗时前五的查询性能趋势,总体吞吐量统计分析。缓存明...
干货|可视化BI平台:如何构建易用的数据流?
导致项目拆包时遇到了模块间紧紧咬合的问题,牵一发而动全身。 目前,DataWind前端团队正在进行模块架构的升级,本文将为大家详解基于**Redux + hook**如何升级数据流方案,以解决可视化查询模块内以及与其... 可以多个数据流实例同时使用,而不会相互干扰。7. 可同时用于组件和项目。最好能伸能缩,复杂组件有时候也用得上数据流。 **我们内部的数据产品搭建框架提供的数据流能力,就是尽力符合以上几点去做的,以...
干货 | UniqueMergeTree:支持实时更新删除的ClickHouse表引擎
然后生成对应的列存文件。每个Batch写入的文件对应一个版本号,版本号能用来表示数据的写入顺序。同一批次的数据不包含重复key,但不同批次的数据包含重复key,这就需要在读的时候去做合并,对key相同的数据返回去最... 下面是一个使用示例。首先我们建了一张UniqueMergeTree的表,表引擎的参数和ReplacingMergeTree是一样的,不同点是可以通过UNIQUE KEY关键词来指定这张表的唯一键,它可以是多个字段,可以包含表达式等等。 特惠活动
特惠活动
 如何拆包一个包含字典的列表并合并不同键对应的多个值?
-优选内容
如何拆包一个包含字典的列表并合并不同键对应的多个值?
-优选内容
 如何拆包一个包含字典的列表并合并不同键对应的多个值?
-相关内容
如何拆包一个包含字典的列表并合并不同键对应的多个值?
-相关内容
Pulsar 在云原生消息引擎领域为何如此流行?| 社区征文
将这些消息合并成为原始的消息 M1,发送给处理进程。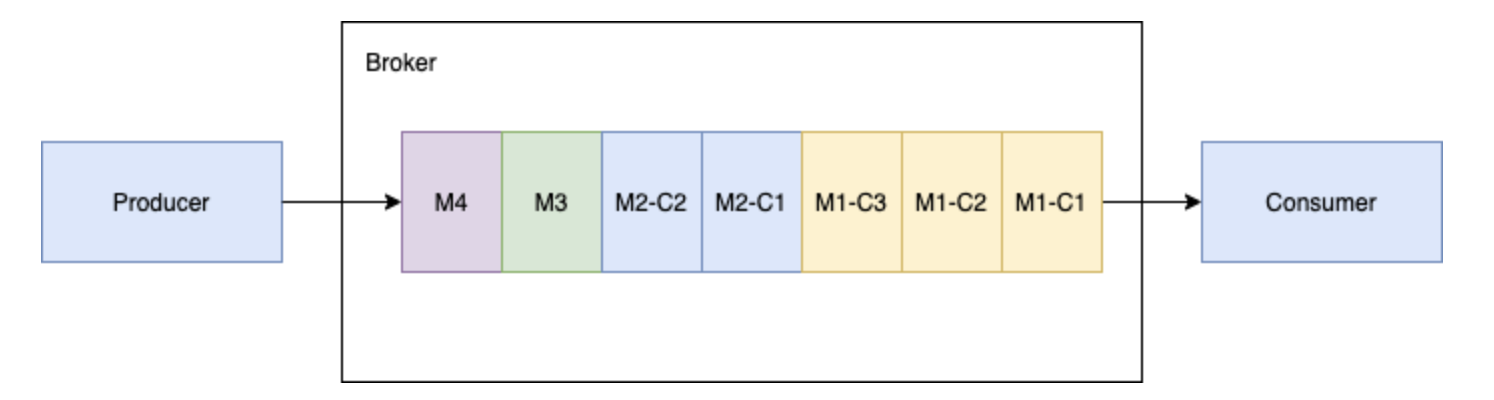##### 3.2.5.2 处理多个 producer 和一个订阅 consumer 的分块消息当多个生产者发布块消息到单个主题,这个 Broker 在同一个 Ledger 里面保存来自不同生产者的所有块消息。 如下所示,生产者1发布的消息 M1,M1 由 M1-C1, M1-C2 和 M1-C3 三个块组成。 生产者2发布的消息 M2,M2 由 M2...
Cloud Shuffle Service 在字节跳动 Spark 场景的应用实践
Shuffle 过程中不同 Application 作业会互相影响;* 在离线混部场景下,我们希望利用在线服务业务低峰期的 CPU,但缺少对应的磁盘资源。**02****External Shuffle Service 的优化**针对上述问题和需求,我们先对 ESS 进行了优化。**参数调优**首先是参数调优。为了实现参数调优,我们研发了一个旁路系统,如下图。--------------------------------- 和 Delta File (log 文件),Delta File...
干货|Hudi Bucket Index 在字节跳动的设计与实践
Hudi 是一个流式数据湖平台,提供 ACID 功能,支持实时消费增量数据、离线批量更新数据,并且可以通过 Spark、Flink、Presto 等计算引擎进行写入和查询。Hudi 官方对于文件管理和索引概念的介绍如下,> Hudi提供类似 Hive 的分区组织方式,与 Hive 不同的是,Hudi 分区由多个 File Group 构成,每个 File Group 由 File ID进行标识。File Group 内的文件分为 Base File (parquet 格式) 和 Delta File(log 文件),Delta File 记录对 Bas...
揭秘|字节跳动基于Hudi的实时数据湖平台
Timeline 由一个个 commit 构成,一次写入过程对应时间线中的一个 commit,记录本次写入修改的文件。相较于传统数仓,Hudi 要求每条记录必须有唯一的主键,并且同分区内,相同主键只存在在一个 file group中。底层存储由多个 file group 构成,有其特定的 file ID。File group 内的文件分为 base file 和 log file, log file 记录对 base file 的修改,通过 compaction 合并成新的 base file,多个版本的 base file 会同时存在。在...
干货|Hudi Bucket Index 在字节跳动的设计与实践
Hudi 是一个流式数据湖平台,提供 ACID 功能,支持实时消费增量数据、离线批量更新数据,并且可以通过 Spark、Flink、Presto 等计算引擎进行写入和查询。Hudi 官方对于文件管理和索引概念的介绍如下,> > > Hudi提供类似 Hive 的分区组织方式,与 Hive 不同的是,Hudi 分区由多个 File Group 构成,每个 File Group 由 File ID进行标识。File Group 内的文件分为 Base File ( parquet 格式) 和 Delta File( log 文件),Delta File 记...
Hudi Bucket Index 在字节跳动的设计与实践
Hudi 是一个流式数据湖平台,提供 ACID 功能,支持实时消费增量数据、离线批量更新数据,并且可以通过 Spark、Flink、Presto 等计算引擎进行写入和查询。Hudi 官方对于文件管理和索引概念的介绍如下,> Hudi提供类似 Hive 的分区组织方式,与 Hive 不同的是,Hudi 分区由多个 File Group 构成,每个 File Group 由 File ID进行标识。File Group 内的文件分为 Base File ( parquet 格式) 和 Delta File( log 文件),Delta File 记录对 B...
干货|Hudi Bucket Index 在字节跳动的设计与实践
Hudi 是一个流式数据湖平台,提供 ACID 功能,支持实时消费增量数据、离线批量更新数据,并且可以通过 Spark、Flink、Presto 等计算引擎进行写入和查询。Hudi 官方对于文件管理和索引概念的介绍如下,> Hudi 提供类似 Hive 的分区组织方式,与 Hive 不同的是,Hudi 分区由多个 File Group 构成,每个 File Group 由 File ID 进行标识。File Group 内的文件分为 Base File ( parquet 格式) 和 Delta File( log 文件),Delta File 记录对...
