如何考虑小时,按天过滤pandasdataframe的最近3天的值?
 社区干货
社区干货
边缘智变:深度学习引领下的新一代计算范式|社区征文
剖析和过滤,并把处理后的数据发送到云计算层。边缘服务器一般部署在网络边缘,与设备层紧密联系,能够快速反映设备层的需要,降低传送数据的延迟。云计算层该层专门从事全球数据处理、剖析和存储,并承担运用的思路解... 去除噪声和异常值。```import pandas as pd # 读取数据 data = pd.read_csv('patient_data.csv') # 去除异常值 data = data.replace([np.inf, -np.inf], np.nan) data = data.dropna() # 预处理数据...
基于火山引擎云搜索服务的排序学习实战
> 排序学习(LTR: Learning to Rank)作为一种机器学习技术,其应用场景非常广泛。例如,在**电商推荐**领域,可以帮助电商平台对用户的购买历史、搜索记录、浏览行为等数据进行分析和建模;可以帮助**搜索引擎**对用户的搜索关键词进行分析建模;可以为广告主提供最精准和最有效的**广告投放**方案;在**金融风控**领域,排序学习可以帮助金融机构分析客户的信用评级和欺诈风险,提高风控能力和业务效率。#### 本文相关产品-火山引擎云搜...
居家办公更要高效 - 自动化办公完美提升摸鱼时间 | 社区征文
天下我有,代码一粘,两手一摊,一劳永逸。多亏找到了这些神器,最近可被各种文档表格,各种数据搞疯了,脑瓜子嗡嗡的。在这上面还闹过一些小乌龙,为了相互转各种文档还当冤大头买了 wps 的超级会员我知道 java 写点... text_frame = shape.text_frame # 遍历文本框中的所有段落 for paragraph in text_frame.paragraphs: # 将文本框中的段落文字写入word中 wo...
技术人的 2023 总结:人工智能-基于机器学习的环境污染影响评估学习|社区征文
import pandas as pdimport numpy as npfrom sklearn.model_selection import train_test_splitfrom sklearn.linear_model import LinearRegressionfrom sklearn.metrics import mean_squared_errorimport matplotlib.pyplot as plt# 生成模拟环境数据np.random.seed(42)data = pd.DataFrame({ 'Temperature': np.random.uniform(10, 30, 1000), 'Humidity': np.random.uniform(30, 80, 1000), 'WindSpeed'...
 特惠活动
特惠活动
 如何考虑小时,按天过滤pandasdataframe的最近3天的值?
-优选内容
如何考虑小时,按天过滤pandasdataframe的最近3天的值?
-优选内容
 如何考虑小时,按天过滤pandasdataframe的最近3天的值?
-相关内容
如何考虑小时,按天过滤pandasdataframe的最近3天的值?
-相关内容
字节跳动 EB 级 Iceberg 数据湖的机器学习应用与优化
最近最新推出的 GPT-4 模型以及 Google 最近发布的第二代 PaLM 没有公布具体的模型细节。但可以猜测的是,这些模型的规模可能已经达到了万亿级的参数,这些进展为自然语言处理和其他相关领域的研究者们带来了新的机遇... 能够很方便的以零复制的方式对接 Spark Dataset、Pandas 等接口。.to(device) # 假设设备是边缘设备,例如手机或平板电脑 output_data = optimized_model(input_data)```# 边缘计算案例:实时视频流处理问题:传统的中央服务器处理方式在大规模... (frame): # 在这里添加你的视频处理逻辑,例如压缩、转码、分析等 # 作为示例,我们只是简单地转换帧的颜色空间并缩小其大小 frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB) # 转换颜色空间 ...
基于火山引擎云搜索的混合搜索实战
(https://registry.opendata.aws/amazon-berkeley-objects/)作为数据集,数据集无需本地下载,直接通过代码逻辑上传到 OpenSearch,详见下面代码内容。 **操作步骤**### **安装 Python 依赖**``` pip install -U elasticsearch7==7.10.1 pip install -U pandas pip install -U jupyter pip install -U requests pip install ...
基于 LAS pyspark 的自有 python 工程使用&依赖导入
import pandas as pd df = pd.DataFrame({'address': ['四川省 成都市','湖北省 武汉市','浙江省 杭州市']}) res = df['address'].str.split(' ', expand=True) res.columns = ['province',... (3)通过 DataLeap 资源管理上传代码包和虚拟环境包(4)通过如下方式调用步骤1中的代码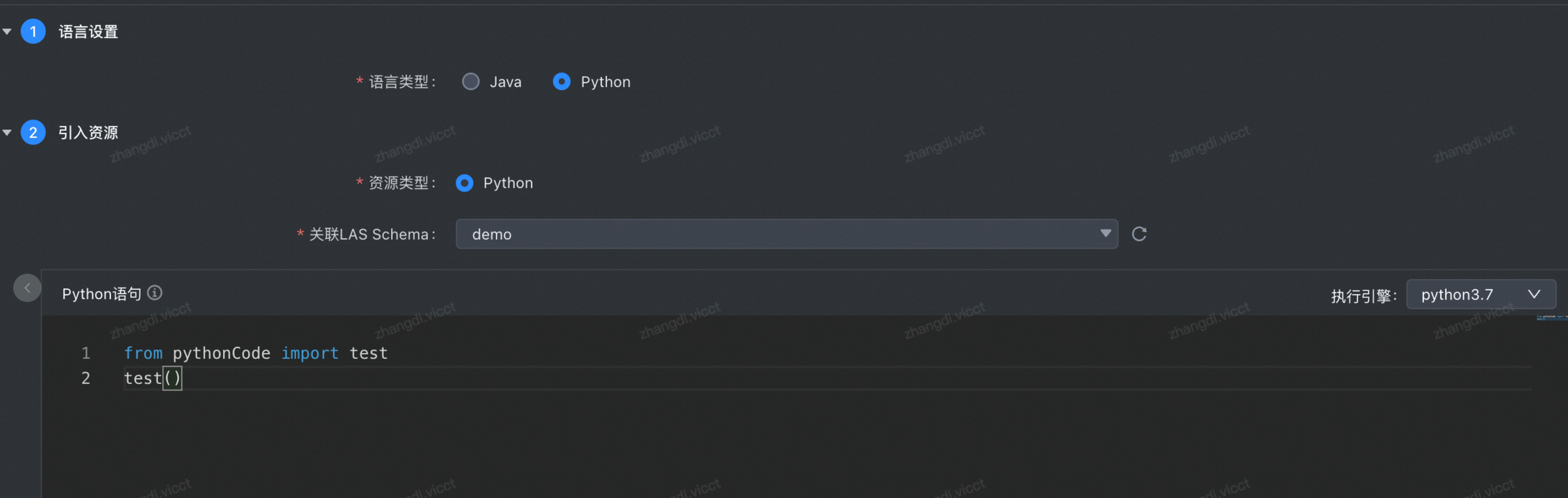> 【说...
字节跳动 EB 级 Iceberg 数据湖的机器学习应用与优化
最近最新推出的 GPT-4 模型以及 Google 最近发布的第二代 PaLM 没有公布具体的模型细节。但可以猜测的是,这些模型的规模可能已经达到了万亿级的参数,这些进展为自然语言处理和其他相关领域的研究者们带来了新的机遇... 能够很方便的以零复制的方式对接 Spark Dataset、Pandas 等接口。val distData = sc.parallelize(data)通过外部数据集构建RDD val distFile = sc.textFile("data.txt")RDD构建成功后,可以对其进行一系列操作,... 并转化为DataFrame,随后通过Map操作将名字转化为一个可读的形式并输出。 val namesDF = spark.sql("SELECT name FROM parquetFile WHERE age BETWEEN 13 AND 19")namesDF.map(attributes => "Name: " + attributes...
保姆级人工智能学习成长路径|社区征文
曾获得阿里云天池安全恶意程序检测第一名,科大讯飞恶意软件分类挑战赛第三名,CCF恶意软件家族分类第4名,科大讯飞阿尔茨海默综合症预测赛第4名,Datacon大数据安全分析比赛第五名,科大讯飞事件抽取挑战赛第七名。拥有... Pandas(Series、DataFrame的基本操作)、scikit-learn(数据划分、常用模型、交叉验证等内容)、imblearn(不均衡数据的处理)、梯度提升树(最常用的如XGBoost、LightGBM、CatBoost)、NLP常用库(jieba:中文分词、nltk:英...
一文了解 DataLeap 中的 Notebook
> 更多技术交流、求职机会,欢迎关注**字节跳动****数据平台****微信公众号,回复【1】进入官方交流群**# 概述Notebook 是一种支持 REPL 模式的开发环境。所谓「REPL」,即「读取-求值-输出」循环:输入一段代码,立... 同时还接入了 DataLeap 提供的 Python & SQL 代码智能补全功能。额外地,我们还开发了定制的可视化 SDK,使得用户在 Notebook 上计算得到的 Pandas Dataframe 可以接入 DataLeap 数据研发已经提供的数据结果分析模...
