Kafka轮询和重新平衡问题
 社区干货
社区干货
Kafka 消息传递详细研究及代码实现|社区征文
## 背景新项目涉及大数据方面。之前接触微服务较多,趁公司没反应过来,赶紧查漏补缺。Kafka 是其中之一。Apache Kafka 是一个开源的分布式事件流平台,可跨多台计算机读取、写入、存储和处理事件,并有发布和订阅事... push 和 pull 比较:两者区别是,push 是发送方定义发送速率,而不管接收方接收速率,而 pull 是接收方在能承受的范围内自己定义接收速率。push 容易造成 consumer 超载、无法进行消费、吞吐量很低、延迟高等问题。...
一文了解字节跳动消息队列演进之路
**本文将主要从字节消息队列的演进过程及在过程中遇到的痛点问题,和如何通过自研云原生化消息队列引擎解决相关问题方面进行介绍。****Kafka 时代**在初期阶段,字节跳动使用 Apache Kafk... 这种设计也考虑到了计算资源和存储资源难以平衡的问题。BMQ 在执行扩缩容操作时,可以直接通过对计算资源和存储资源做出独立调整,能够降低资源浪费,还进一步提升了整体资源的利用率。 **高吞吐**...
Redis 使用 List 实现消息队列有哪些利弊?|社区征文
Kafka`等,有人会问:“Redis 适合做消息队列么?”在回答这个问题之前,我们先从本质思考:- 消息队列提供了什么特性?- Redis 如何实现消息队列?是否满足存取需求?今天,码哥结合消息队列的特点一步步带大家分析... 程序需要不断轮询并判断是否为空再执行消费逻辑,这就会导致即使没有新消息写入到队列,消费者也要不停地调用 `RPOP` 命令占用 `CPU` 资源。> 65 哥:要如何避免循环调用导致的 CPU 性能损耗呢?Redis 提供了 `BLP...
云原生环境下的日志采集、存储、分析实践
在遇到这些问题以后,我们研发了一套统一的日志管理平台——火山引擎日志服务(Tinder Log Service,简称为 TLS)。TLS 的整体架构如下: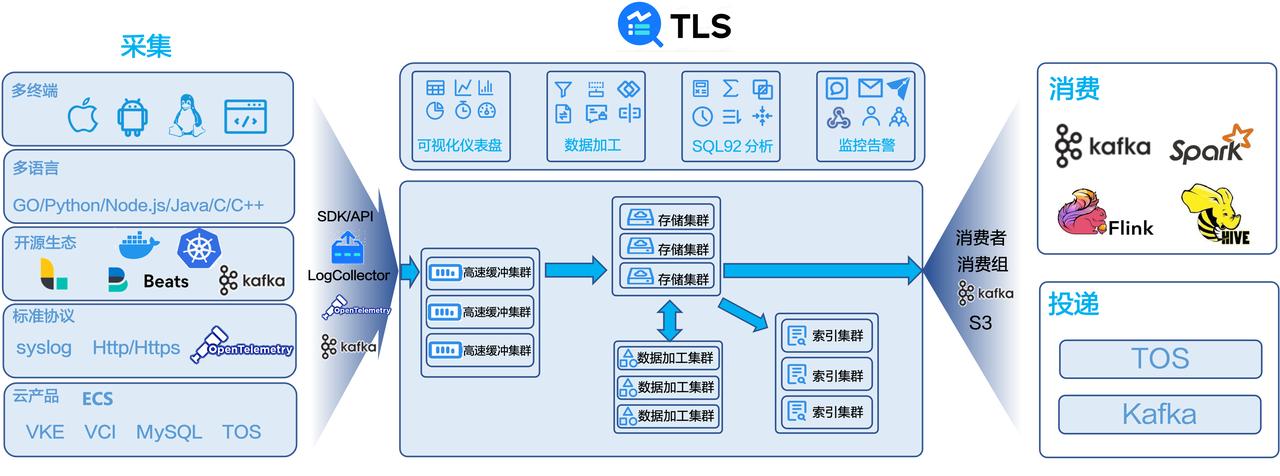面对各种日志源,TLS 通过自研的 LogCollector/SDK/API,可支持专有协议、 OpenTelemetry 和 Kafka 协议上传日志。支持多种类型的终端、多种开发语言以及开源生态标...
 特惠活动
特惠活动
 Kafka轮询和重新平衡问题
-优选内容
Kafka轮询和重新平衡问题
-优选内容
 Kafka轮询和重新平衡问题
-相关内容
Kafka轮询和重新平衡问题
-相关内容
云原生环境下的日志采集、存储、分析实践
在遇到这些问题以后,我们研发了一套统一的日志管理平台——火山引擎日志服务(Tinder Log Service,简称为 TLS)。TLS 的整体架构如下:面对各种日志源,TLS 通过自研的 LogCollector/SDK/API,可支持专有协议、 OpenTelemetry 和 Kafka 协议上传日志。支持多种类型的终端、多种开发语言以及开源生态标...
9年演进史:字节跳动 10EB 级大数据存储实战
从集群规模和数据量来说,HDFS 平台在公司内部已经成长为总数十万台级别服务器的大平台,支持了 10 EB 级别的数据量。**当前在字节跳动,** **HDFS** **承载的主要业务如下:**- Hive,HBase,日志服务,Kafka 数据... 用户请求的统一接入及统一视图的管理也会有很大的问题。为了解决用户接入过于分散,我们需要一个独立的接入层来支持用户请求的统一接入,转发路由;同时也能结合业务提供用户权限和流量控制能力。另外,该接入层也需要...
打造新一代云原生"消息、事件、流"统一消息引擎的融合处理平台 | 社区征文
目前存在一些问题,当然其他主流的开源消息项目也没有进行云原生架构转型,比如RabbitMQ无法水平扩展单队列能力、Kafka扩容需要大量数据拷贝和均衡。这些现有解决方案都不适用于为大规模客户提供弹性服务的公共云环境... 和云计算的推动下,RocketMQ不仅在阿里巴巴内部实现大规模应用,还助推了各行各业的数字转型。至2022年,随着5.0版本的发布,Apache RocketMQ正式进入了云原生的新阶段。RocketMQ5.0 面向云计算的场景进行重新设计,期...
云原生环境下的日志采集、存储、分析实践
### 自建日志采集系统的困境与挑战云原生场景下日志种类多、数量多、动态非永久,开源系统在采集云原生日志时面临诸多困难,主要包括以下问题:**一、** **采集难**- **配置复杂** **:** 系统规模越来越大,节... OpenTelemetry 和 Kafka 协议上传日志。支持多种类型的终端、多种开发语言以及开源生态标准协议。采集到的日志首先会存入高速缓冲集群,削峰填谷,随后日志会匀速流入存储集群,根据用户配置再流转到数据加工集群进...
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0(中)
一种是调整计算组的 CPU 核数和内存大小实现快速的纵向扩缩容,另一种方式是增减计算组的数量实现水平扩容,在存储计算分离的架构下,计算资源与存储资源是解耦的且无状态的,扩缩容过程不需要迁移和平衡数据,因而可以实现快速弹性扩缩容。 计算节点主要承担的是计算任务,这些任务可以是数据写入、用户查询,也可以是一些后台任务。用户查询和后台任务,可以共享相同的计算节点以提高利用率,也可以使用独立的计算节点以保证严格的...
什么是云原生消息引擎
云原生消息引擎 BMQ 是火山引擎自研,100% 兼容 Apache Kafka 协议,基于云原生的全托管、高吞吐、低时延、高可用、高可扩展性、高稳定性的分布式消息引擎服务,支持灵活动态扩缩容和流批一体计算,提供企业级大数据量... Consumer Group 获取集群和 Topic 信息后,通过指定 Topic-Partition 订阅或者 Coordinator 协调的方式订阅后,读取消息进行消费。 Coordinator云原生消息引擎 BMQ 中,Coordinator 通过状态机完成整个建立平衡 Consu...
干货丨字节跳动基于 Apache Hudi 的湖仓一体方案及应用实践
文丨火山引擎LAS团队李铮本文对目前主流数仓架构及数据湖方案的不足之处进行分析,介绍了字节内部基于实时/离线数据存储问题提出的的湖仓一体方案的设计思路,并分享该方案在实际业务场景中的应用情况。最后还会为... **目前主流的数仓架构—— Lambda 架构,能够通过实时和离线两套链路、两套代码同时兼容实时数据与离线数据,做到通过批处理提供全面及准确的数据、通过流处理提供低延迟的数据,达到平衡延迟、吞吐量和容错性的目的。...
【GMP3.11】Webhook通道接入
避免因失败重试等导致用户重复触达等客情问题 支持被动接受json回执,但是是基于流水号/消息ID的单个回执支持主动轮询json回执,但是是基于流水号/消息ID的单个查询支持批量发送与批量响应支持kafka/rmq的发送与接收 如何判断gmpWebhook是否可以承载客户业务? gmpWebhook本质是通过产品化配置直接构造http请求访问客户接口,因此需要客户接口请求响应的数据结构可以直接给出,或者可以直接给出示例curl命令或示例报文数据,而不是只能...
干货|一套架构框架满足流批数据质量监控
我们面临了一些什么问题?首先是场景需求非常复杂:1. 离线监控,主要是不同存储的数据质量监控,比如 Hive 或者 ClickHouse 。2. 字节跳动内部的广告系统对时效性和准确性要求很高,如果用微批系统 10 min 才做一次检测,可能线上损失就上百万了甚至千万了。所以广告系统对实时性要求相对较高。3. 另外一个是复杂拓扑情况下的流式延迟监控。4. 最后是微批,指一段时间内的定时调度,有些 Kafka 导入 ES 的流式场景,需要每隔几分...
