如何设置两个使用相同内存持久化存储的核心数据堆栈?
 社区干货
社区干货
阿里巴巴的 Java 开发手册(黄山版)来了
而是限制过度个性化,以一种普遍认可的统一方式一起做事,提升协作效率,降低沟通成本。代码的字里行间流淌的是软件系统的血液,代码质 量的提升是尽可能少踩坑,杜绝踩重复的坑,切实提升系统稳定性,码出质量。## 2. ... 直接像魔法一样凭空出现的值,可以是数字、字符串等。**这是我印象中比较深的一条强制性规约。当我刚入这行的开始写代码的时候,魔法值满天飞,怎么方便怎么来。根本不会考虑这样的问题,但是后来这样做的恶性后果...
字节跳动 NoSQL 的探索与实践
作者:王佳毅|火山引擎存储&数据库解决方案负责人> 本文整理自火山引擎开发者社区技术大讲堂第三期演讲,主要为大家介绍了 NoSQL 的前世今生和发展脉搏,以及字节跳动 NoSQL 的实践。## NoSQL 应用的现状什么是... 除核心数据管理之外,BytrGraph 也支持以下典型场景:- 风控反作弊:在风控场景,业界以前的常用做法是使用 HBase 加上一个计算引擎。实际上图计算对于风控反作弊的异常识别和风险检测更适合。 - 推荐模型:图训练...
字节跳动 NoSQL 的探索与实践
具有海量存储和吞吐能力,单体集群可达万亿条边,支持百万 QPS 图上多度读写。ByteGraph 也支持 Super Node 热点访问,单个过亿出度节点 10K 量级 QPS 毫秒级读写。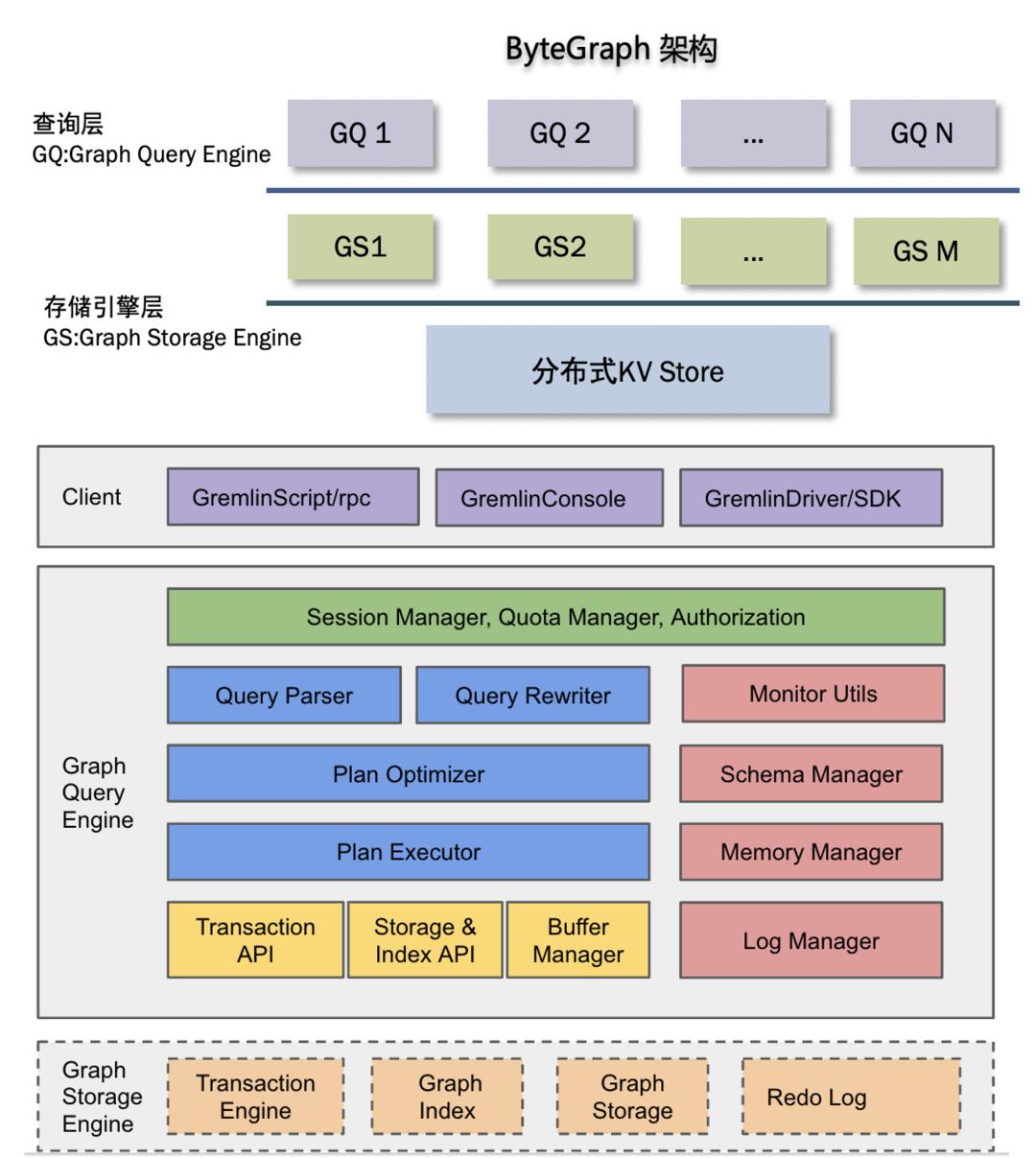目前 ByteGraph 基本支持了字节跳动全系产品,除核心数据管理之外,BytrGraph 也支持以下典型场景:- 风控反作弊:在风控场景,业界以前...
干货|4000字总结,Serverless在OLAP领域应用的五点思考
而无需考虑底层堆栈问题。 伴随着近年来相关技术成熟度的增加,市场对Serverless的接受程度也变得越来越高。可以说时至今日,Serverless已迈入了向成熟稳定方向发展的高速轨道。 作为一款... 基于cloud-native 云原生的理念构建了全新一代的数据仓库,架构上进行了三层解耦,**期望在Serverless的加持下,提供更稳定、可靠、可信的分析服务,让开发人员时间精力从基础设施运维优化上解放,更聚焦在核心业务功能...
 特惠活动
特惠活动
 如何设置两个使用相同内存持久化存储的核心数据堆栈?
-优选内容
如何设置两个使用相同内存持久化存储的核心数据堆栈?
-优选内容
 如何设置两个使用相同内存持久化存储的核心数据堆栈?
-相关内容
如何设置两个使用相同内存持久化存储的核心数据堆栈?
-相关内容
海量笔记@在云上,如何搭建属于自己的全文搜索引擎 Web应用-个人站点 | 社区征文
修改配置:参数设置项(server.host、server.name、elasticsearch.url...)vim /kibana.yml启动:Kibananohup ./bin/kibana &(后台启动方式,关闭终端服务正常运行)查看:kibana进程,能看到则表示正常,可在终端(curl+链接)访问验证,也可进入浏览器:当前kibana服务IP:5601)ps aux|grep kibana```## Redis缓存**描述:开源、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API,当下较为热门的查询性能缓存。...
一文了解 DataLeap 中的 Notebook
> 更多技术交流、求职机会,欢迎关注**字节跳动****数据平台****微信公众号,回复【1】进入官方交流群**# 概述Notebook 是一种支持 REPL 模式的开发环境。所谓「REPL」,即「读取-求值-输出」循环:输入一段代码,立... 通常认为其有两个核心的概念:Notebook 和 Kernel。- Notebook 指的是代码文件,一般在文件系统中存储,后缀名为`ipynb`。Jupyter Notebook 后端提供了管理这些文件的能力,用户可以通过 Jupyter Notebook 的页面创...
Kubernetes 观测:基于 eBPF 的云原生深度可观测性实践
我们不难总结出几个**核心诉求**:* 从应用层到内核,自顶向下,需要能够尽可能全面地进行覆盖;* 接入成本需要尽可能低;* 需要能够有统一标准的语义化标签和因果关系,来帮助我们关联分析各个离散的可观测数据。... 操作系统内核中运行沙盒程序。eBPF 被用于安全有效地扩展内核的功能,而无需更改内核源代码或加载内核模块,同时 eBPF 程序在加载的时候有严格的 Verifier 进行校验,可以确保代码的正确性,避免死循环或者非法内存访问...
Java SDK
1. 安装SDK 1.1 下载SDK当前SDK版本:v2.0.15 【附件下载】: datatester-java-sdk-2.0.15.jar,大小为 1.2 添加jar包java版本需求:Java 8及更高版本 导入方式:将jar文件添加至项目Modules 以主流IDE(IntelliJ IDEA... // 进组不出组内存实现接口,若用户不配置下列代码,则默认不开启“进组不出组”功能 // 持久化存储进组信息,请自行实现 UserAbInfoHandler 接口(推荐) // MemoryHandler为内存存储,仅...
配置数据持久化
如果未配置数据持久化,则可能有数据丢失的风险。本文档演示如何配置数据持久化。 应用场景数据持久化指将保存在内存中的数据写入到磁盘上进行长期存储。在消息队列 RabbitMQ版中,持久化或非持久化的消息都会被写入... RabbitMQ 数据持久化的方式包括 Exchange 持久化、Queue 持久化和 Message 持久化。推荐全部配置,保障绝大多数的异常场景下不丢失消息。 配置方式 配置 Exchange 持久化Queue 和 Message 的持久化设置保障消息的可...
云原生之旅:一年的变革、成长与启示|社区征文
它提供了自动化部署、弹性扩展、自我修复等功能,帮助开发者更好地管理容器化应用程序。Kubernetes的核心概念包括节点、Pod、Service、Deployment等,通过这些概念可以构建和管理一个可扩展的容器化应用程序。