KafkaCDC是否可以用于已经存在的数据库和数据(而不是在一开始设置日志记录)?
 社区干货
社区干货
消息队列选型之 Kafka vs RabbitMQ
在面对众多的消息队列时,我们往往会陷入选择的困境:“消息队列那么多,该怎么选啊?Kafka 和 RabbitMQ 比较好用,用哪个更好呢?”想必大家也曾有过类似的疑问。对此本文将在接下来的内容中以 Kafka 和 RabbitMQ 为例分享消息队列选型的一些经验。消息队列即 Message+Queue,消息可以说是一个数据传输单位,它包含了创建时间、通道/主题信息、输入参数等全部数据;队列(Queue)是一种 FIFO(先进先出)的数据结构,编程语言一般都内置(内存...
聊聊 Kafka:Topic 创建流程与源码分析 | 社区征文
设置为 true 时,那么当 Producer 向一个不存在的 topic 发送数据时,该 topic 同样会被创建出来,此时,副本数默认是 1。## 三、Topic 的创建流程### 3.1 Topic 创建入口首先我们找到 kafka-topics.sh 这个脚本... (https://p3-volc-community-sign.byteimg.com/tos-cn-i-tlddhu82om/cb0a715aff8e46c39fba047cdc300898~tplv-tlddhu82om-image.image?=&rk3s=8031ce6d&x-expires=1716135718&x-signature=f2MSlOm9P4zDS5kDwBhfsD%2...
Kafka@记一次修复Kafka分区所在broker宕机故障引发当前分区不可用思考过程 | 社区征文
写在前面的话,业务组内研发童鞋碰到了这样一个问题,反复尝试并研究,包括不限于改Kafka,主题创建删除,Zookeeper配置信息重启服务等等,于是我们来一起看看... Ok,Now,我们还是先来一步步分析它并解决它,依然以”... 数据入发送到Kafka中,消费者线程正常订阅到消息。 我们这里分布式协调服务采用的是Zookeeper,当Kafka某个broker节点宕调后,其实我们可以在Zookeeper中还是有迹可循的,Kafka集群的一些重要信息都记录在Zookeepe...
火山引擎上云迁移指南(二):迁移实施
准备工作:火山引擎准备环境和迁移环境检查,提前暴露迁移可能存在的潜在风险;2. 应用迁移:将应用及其数据和涉及到的镜像文件迁移到新的集群中;3. 流量切换:这一阶段决定了如何将线上流量导入到新建的集群中,并使用新建的集群为用户提供服务。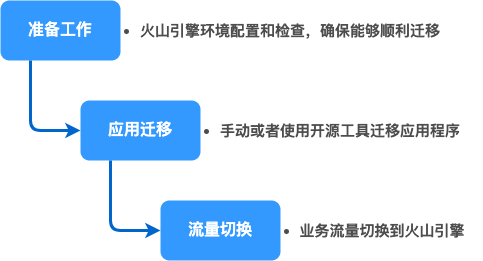具体步骤如下:1. 准备工作 提前在火山引擎控制台中创建创...
 特惠活动
特惠活动
 KafkaCDC是否可以用于已经存在的数据库和数据(而不是在一开始设置日志记录)?
-优选内容
KafkaCDC是否可以用于已经存在的数据库和数据(而不是在一开始设置日志记录)?
-优选内容
 KafkaCDC是否可以用于已经存在的数据库和数据(而不是在一开始设置日志记录)?
-相关内容
KafkaCDC是否可以用于已经存在的数据库和数据(而不是在一开始设置日志记录)?
-相关内容
Kafka@记一次修复Kafka分区所在broker宕机故障引发当前分区不可用思考过程 | 社区征文
写在前面的话,业务组内研发童鞋碰到了这样一个问题,反复尝试并研究,包括不限于改Kafka,主题创建删除,Zookeeper配置信息重启服务等等,于是我们来一起看看... Ok,Now,我们还是先来一步步分析它并解决它,依然以”... 数据入发送到Kafka中,消费者线程正常订阅到消息。 我们这里分布式协调服务采用的是Zookeeper,当Kafka某个broker节点宕调后,其实我们可以在Zookeeper中还是有迹可循的,Kafka集群的一些重要信息都记录在Zookeepe...
连接器列表
Kafka Topic 中读取数据并将数据写入 Kafka Topic 的能力。 ✅ ✅ ❌ Flink 1.16 jdbc 提供对 MySQL、PostgreSQL 等常见的关系型数据库的读写能力,以及支持维表。 ✅ ✅ ✅ Flink 1.11、Flink 1.16 mysql-cdc 提供从 MySQL 中读取快照数据和增量数据的能力。 ✅ ❌ ❌ Flink 1.16 mongodb-cdc 提供从 MongoDB 中读取快照数据和增量数据的能力。 ✅ ❌ ❌ Flink 1.16 postgres-cdc 用于从 PostgreSQL 数据...
通过 ByteHouse 消费日志
中进行进一步的分析处理。在 ByteHouse 中创建 Kafka 数据导入任务之后,可以直接通过 Kafka 流式传输数据。数据导入任务将自动运行,持续读取日志主题中的日志数据,并将其写入到指定的数据库表中。消费日志时,支持仅消费其中的部分字段,并设置最大消息大小等配置。同时您可以随时停止数据导入任务以减少资源使用,并在任何必要的时候恢复该任务。ByteHouse 将在内部记录 offset,以确保停止和恢复过程中不会丢失数据。 费用说明通过...
火山引擎上云迁移指南(二):迁移实施
准备工作:火山引擎准备环境和迁移环境检查,提前暴露迁移可能存在的潜在风险;2. 应用迁移:将应用及其数据和涉及到的镜像文件迁移到新的集群中;3. 流量切换:这一阶段决定了如何将线上流量导入到新建的集群中,并使用新建的集群为用户提供服务。具体步骤如下:1. 准备工作 提前在火山引擎控制台中创建创...
火山引擎上云迁移指南(一):上云迁移背景与流程
由资深的存储&数据库解决方案架构师组成。团队致力于帮助企业与组织更好的使用火山引擎云存储与云数据库产品,针对实际业务场景设计最优的解决方案,用专业技术助力组织和企业实现业务成功。## 上云迁移背景### 什么是云迁移云迁移是指将数字化业务运营迁移到云的过程。云迁移更侧重于将数据、应用程序和 IT 流程等企业数字资产从某些数据中心迁移到其他数据中心,而不是把服务器、网络等硬件设备打包和移动。云迁移绝不仅仅...
9年演进史:字节跳动 10EB 级大数据存储实战
从集群规模和数据量来说,HDFS 平台在公司内部已经成长为总数十万台级别服务器的大平台,支持了 10 EB 级别的数据量。**当前在字节跳动,** **HDFS** **承载的主要业务如下:**- Hive,HBase,日志服务,Kafka 数据... 无法对外提供一个完整的目录树视图。NNProxy 中的路由管理就解决了这个问题。路由管理存储了一张 mount table,表中记录若干条路径到集群的映射关系。例如 **/user ->** **hdfs** **://namenodeB**,这条映射关系的...
变更数据捕获(CDC)管理
变更数据捕获功能用于记录应用到所启用的表中的插入、更新和删除,能够提供变更的详细信息。本文介绍使用存储过程对指定数据库开启或关闭数据捕获功能和使用示例。 前提条件已连接 SQL Server 实例且目标库状态为 Online。更多信息,请参见连接实例。 注意事项存在事务的语句不能执行插入操作。 不支持对系统库或 rdsadmin 库执行变更数据捕获语句。 只有主账号支持对数据库执行开启或关闭变更数据捕获语句。 开启或关闭 CDC执行...
字节跳动实时数据湖构建的探索和实践
字节跳动数据集成系统目前支持了几十条不同的数据传输管道,涵盖了线上数据库,例如Mysql Oracle和MangoDB;消息队列,例如Kafka RocketMQ;大数据生态系统的各种组件,例如HDFS、HIVE和ClickHouse。在字节跳动内部,数... 目前支持了20多种不同数据源类型。- 流式集成模式主要是从MQ将数据导入到Hive和HDFS,任务的稳定性和实时性都受到了用户广泛的认可。- 增量模式即CDC模式,用于支持通过数据库变更日志Binlog,将数据变更同步到...
配置 Kafka 数据源
4 数据同步任务开发 4.1 数据源注册新建数据源操作详见配置数据源,以下为您介绍不同接入方式的 Kafka 数据源配置相关信息: 火山引擎 Kafka 接入方式其中参数名称前带 * 的为必填参数,名称前未带 * 的为可选填参数。 参数 说明 基本配置 *数据源类型 Kafka *接入方式 火山引擎 Kafka *数据源名称 数据源的名称,可自行设置,仅支持中文,英文,数字,“_”,100个字符以内。 参数配置 *Kafka 实例 ID 下拉选择已在火山引擎...
