启动服务器时出现“GraphQLError:语法错误:预期“:”,但找到“)”。”的错误消息。
 社区干货
社区干货
干货|字节跳动EMR产品在Spark SQL的优化实践
**首先在与Iceberg集成的时候**,对体验和易用的问题进行了优化,用户在使用Spark SQL过程中,需要手动输入很多指令,并且需要找到对应的spark-iceberg 依赖包,这个也是目前集成Iceberg最常用的方案。**我们的解决方... **Spark SQL服务器**------------------虽然行业针对Spark SQL 提供一个SQL 服务器已经有Spark Thrift Server或者Kyuubi这样的工具,但是在某些B端客户的业务的背景下,这些工具并不能完全满足要求,因此...
分布式数据库TiDB的设计和架构
只能通过购买更贵更好的服务器;无法线性扩容,海量数据下处理能力大幅下降。 **2008年至2013年**2008年至2013年,随着搜索/社交的发展,数据量爆发增长,传统数据库高成本,无法线性扩容问题日益突显;分布式及分布... 并兼容大多数 MySQL 的语法,在大多数场景下可以直接替换 MySQL- 默认支持高可用,在少数副本失效的情况下,数据库本身能够自动进行数据修复和故障转移,对业务透明- 支持 ACID 事务,对于一些有强一致需求的场景友...
分布式数据库TiDB的设计和架构
只能通过购买更贵更好的服务器;无法线性扩容,海量数据下处理能力大幅下降。**2008年至2013年**2008年至2013年,随着搜索/社交的发展,数据量爆发增长,传统数据库高成本,无法线性扩容问题日益突显;分布式及分布式... 并兼容大多数 MySQL 的语法,在大多数场景下可以直接替换 MySQL- 默认支持高可用,在少数副本失效的情况下,数据库本身能够自动进行数据修复和故障转移,对业务透明- 支持 ACID 事务,对于一些有强一致需求的场景...
一个 41 岁老程序员的 2023 年总结 - 利用 AI 延长自己的编程寿命 |社区征文
当时云原生开发的理念已经大行其道,我所在的 SAP 公司也在云转型的道路上迈开大步往前走,公司内部也举办了很多轮的 Docker & Kubernetes 等技术培训。我当时已经从服务器端编程的 ABAP 技术栈转到了 Java 和 Node.js,搭建本地开发环境一度成为了我的噩梦。Docker 提供了应用与环境的隔离,简化了应用的部署和扩展,使得应用能在不同的环境中以一致性的方式运行。其轻量级特性使得它相比传统虚拟机技术,在资源利用和启动速度上都有明...
 特惠活动
特惠活动
 启动服务器时出现“GraphQLError:语法错误:预期“:”,但找到“)”。”的错误消息。
-优选内容
启动服务器时出现“GraphQLError:语法错误:预期“:”,但找到“)”。”的错误消息。
-优选内容
 启动服务器时出现“GraphQLError:语法错误:预期“:”,但找到“)”。”的错误消息。
-相关内容
启动服务器时出现“GraphQLError:语法错误:预期“:”,但找到“)”。”的错误消息。
-相关内容
观点|SparkSQL在企业级数仓建设的优势
支持标准JDBC接口访问的HiveServer2服务器,管理元数据服务的Hive Metastore,以及任务以MapReduce分布式任务运行在YARN上。标准的JDBC接口,标准的SQL服务器,分布式任务执行,以及元数据中心,这一系列组合让Hiv... 再次重试所消耗的时间几乎等于全新重新提交一个任务,在分布式任务的背景下,任务运行的时间越长,出现错误的概率越高,对于此类组件的使用业界最佳实践的建议也是不超过30分钟左右的查询使用这类引擎是比较合适的。...
干货 |揭秘字节跳动基于 Doris 的实时数仓探索
**但该功能目前有一些比较大的限制:**- **支持的聚合函数相对来说比较简单,** 比如在sum函数中嵌套的加入 case when 语法, 该功能就无法使用了,这就是目前单表物化视图最大一个限制。- Doris 有比较好的 MP... 直接在日志中心里面看到所有的服务器日志,用户只要在这个页面上查询,跟原来用 ES 去做搜集和用 Kibana 做展示 的效果差不多的。**除了监控、日志以外,还有集群的扩缩容能力,这也是云上的这种服务化能力优势的体现...
SaaS-发版日志(2024年前)
功能六:多维表格分析 功能说明:预期它能帮忙解决这类问题:需要同时对比不同人群,在不同维度下的各类指标表现。比如:需要看看自己的产品「windows端人群、mac端人群」在「不同国家、不同省份、不同城市」下的「活... 错误分析、抖音分析将迁移至‘运营优化’模块; 其余基本分析模块,将按照平台(跨端、App端、网页端、小程序端)提供一键预置看板功能 (仅管理员可使用); 2. 场景模板优化 模板配置区增加实时图表预览功能,方便用户在...
字节跳动 EMR 产品在 Spark SQL 的优化实践
**首先在与Iceberg集成的时候**,对体验和易用的问题进行了优化,用户在使用Spark SQL过程中,需要手动输入很多指令,并且需要找到对应的spark-iceberg 依赖包,这个也是目前集成Iceberg最常用的方案。**我们的解决方式... 虽然行业针对Spark SQL 提供一个SQL 服务器已经有Spark Thrift Server或者Kyuubi这样的工具,但是在某些B端客户的业务的背景下,这些工具并不能完全满足要求,因此**字节跳动EMR团队自己设计实现了Spark SQL Server,主...
一个 Angular 程序员两年多的远程办公经验分享 | 社区征文
均持久化在服务器端,便于查询很多使用微信群进行工作沟通的朋友都曾经抱怨过,微信群聊天记录仅仅保存在本地,很容易丢失。而 Slack 不存在这个问题,因为一条消息(无论纯文字还是包含了文件),一经发送,就会保存到服... 就可以快速找到我需要查找的包含某关键字的交互记录: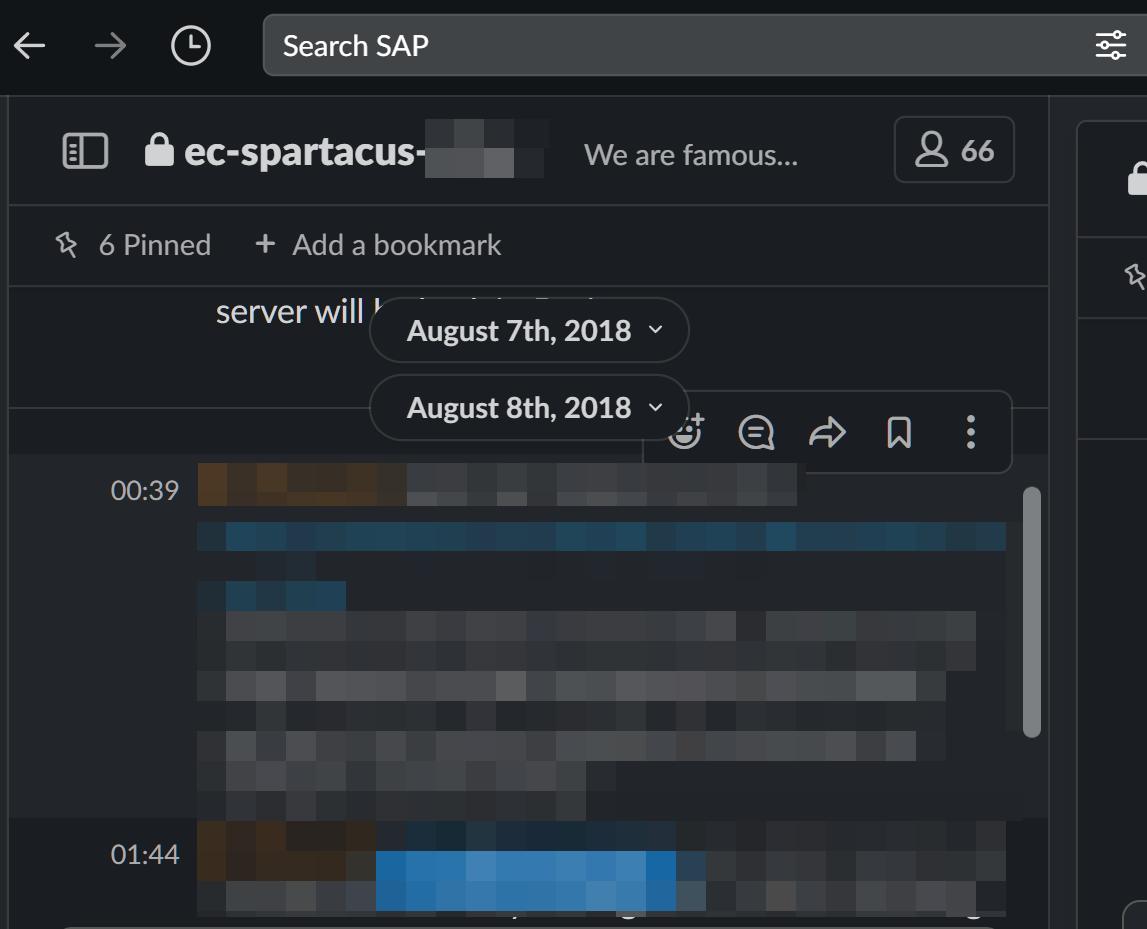## 2. Slack 的文字...
最新动态(2024年前)
服务器端过滤参数、流量计算器rc前端样式升级 【bugfix】升级 chart-space 版本,修复自定义 legend 不能正常展示问题 【bugfix】服务端参数回显错误问题 【bugfix】修复系统管理指标权限优先级高于指标管理页单个指... 修复编辑器问题 线上售卖二期:流程优化及改造 优化 推送人群圈选dsl升级 2021年10月14日 1.9.23 版本 功能 OpenAPI支持 创建实验/启动实验/停止实验/获取互斥组列表/获取指标列表 广告实验增加快手渠道 支持极光...
传统架构 VS 云原生:如何更好的选择搭配
于是今年着重与学习 ansibie 的语法与原理,让管理起服务来不在那么累。(PS:之前有的项目 5、60 台机器,升级一次真的就是通宵了,ansible 至少可以省去几倍的时间)