KafkaJDBCsink不支持十进制/数字反序列化?
 社区干货
社区干货
干货|字节跳动流式数据集成基于Flink Checkpoint两阶段提交的实践和优化(1)
> > 字节跳动开发套件数据集成团队(DTS ,Data Transmission Service)在字节跳动内基于 Flink 实现了流批一体的数据集成服务。其中一个典型场景是 Kafka/ByteMQ/RocketMQ -> HDFS/Hive 。Kafka/ByteMQ/RocketMQ ->... Checkpoint Coordinator 收到 Sink Operator 的所有 Checkpoint 的完成信号后,会给 Operator 发送 Notify 信号。Operator 收到信号以后会调用相应的函数进行 Notify 的操作。在字节跳动内基于 Flink 实现了流批一体的数据集成服务。其中一个典型场景是 Kafka/ByteMQ/RocketMQ -> HDFS/Hive 。Kafka/ByteMQ/RocketMQ... Notify Checkpoint 完成阶段:对应 2PC 的 commit 阶段。Checkpoint Coordinator 收到 Sink Operator 的所有 Checkpoint 的完成信号后,会给 Operator 发送 Notify 信号。Operator 收到信号以后会调用相应的函数...
干货|8000字长文,深度介绍Flink在字节跳动数据流的实践
这样就减少了不必要的反序列化开销,同时降低了MQ集群带宽扇出比例。在数据分流... PyFlink和Kafka的性能瓶颈、以及JSON数据格式带来的性能和数据质量问题都一一显现出来,与此同时下游业务对延迟、数据质量的敏感程度却是与日俱增。于是,我们一方面对一些痛点进行了针对性的优化。另一方面,花费1...
 特惠活动
特惠活动
 KafkaJDBCsink不支持十进制/数字反序列化?
-优选内容
KafkaJDBCsink不支持十进制/数字反序列化?
-优选内容
 KafkaJDBCsink不支持十进制/数字反序列化?
-相关内容
KafkaJDBCsink不支持十进制/数字反序列化?
-相关内容
干货|8000字长文,深度介绍Flink在字节跳动数据流的实践
这样就减少了不必要的反序列化开销,同时降低了MQ集群带宽扇出比例。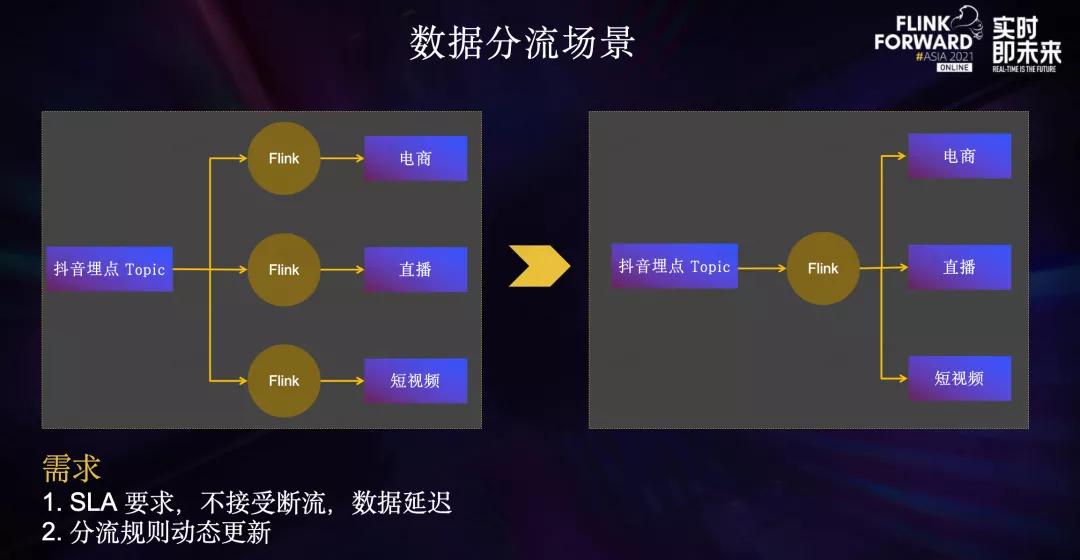在数据分流... PyFlink和Kafka的性能瓶颈、以及JSON数据格式带来的性能和数据质量问题都一一显现出来,与此同时下游业务对延迟、数据质量的敏感程度却是与日俱增。于是,我们一方面对一些痛点进行了针对性的优化。另一方面,花费1...
关于大数据计算框架 Flink 内存管理的原理与实现总结 | 社区征文
内置支持了 Kafka 的端到端保证,并提供了 TwoPhaseCommitSinkFunction 供用于实现自定义外部存储的端到端 exactly-once 保证。)- state有状态计算:支持大状态、灵活的状态后端- Flink 还实现了 watermark 的... 对象序列化二进制存储,下面在来详细介绍下flink内存管理。## 完全JVM内存管理存在的问题基于JVM的数据分析引擎都需要面对将大量数据存到内存当中,就不得不面对JVM存在的几个问题:- java对象存储密度低:比如...
Kafka/BMQ
用作数据目的(Sink)SQL CREATE TABLE kafka_sink ( name String, score INT ) WITH ( 'connector' = 'kafka', 'topic' = 'test_topic_01', 'properties.bootstrap.servers' = 'localhost:9092', 'format' = 'csv' ); WITH 参数参数 是否必选 默认值 数据类型 描述 connector 是 (none) String 指定使用的连接器,此处仅支持 Kafka 连接器。 注意 Kafka-0.10 和 Kafka-0.11 两个版本的连接器使用的...
「火山引擎」数智平台 VeDI 数据中台产品双月刊 VOL.03
为企业数字化转型提供数据支撑。**火山引擎云原生数据仓库** **ByteHouse**云原生数据仓库,为用户提供极速分析体验,能够支撑实时数据分析和海量数据离线分析。便捷的弹性扩缩容能力,极致分析性能和丰富的企业级... Kafka、ClickHouse、Hudi、Iceberg 等大数据生态组件,100%开源兼容,支持构建实时数据湖、数据仓库、湖仓一体等数据平台架构,帮助用户轻松完成企业大数据平台的建设,降低运维门槛,快速形成大数据分析能力。## **产...
火山引擎DataLeap:「数据血缘」踩过哪些坑?来看看字节跳动内部进化史
支持表级血缘、字段血缘,涉及10+元数据。 **第二阶段:从2020年初开始**第二阶段引入了任务血缘,同时支持的元数据类型进行扩充,达到15+。 **第三阶段:从2021年上半年至今**... 如Kafka ,相关 Topic覆盖70%,其他元数据则稍低。在准确率部分,我们区分任务类型做准确性解析。如 DTS 数据集成任务达到99%以上,Hive SQL 任务、 Flink SQL 任务是97%、81% 左右。 