分布式事务是什么?TCC分布式事务是如何实现的?
 社区干货
社区干货
业务中台数据一致性方案|社区征文
分布式事务随着业务的不断发展,业务复杂度也在不断的增长,企业基于微服务架构向下沉淀出了通用的业务中台,数据的访问形式变得复杂了,服务节点间的数据访问通过 API 接口进行。原本单数据库实例只能保证数据库实例... 正是因为分布式微服务的复杂结构,因此给维护数据一致性带来了一定的挑战,但是由于分布式理论的发展与实践,为我们解决分布式系统提供了理论依据。分布式系统数据一致性的保证的关键点就在于如何实现和单系统一样的...
基于国产化环境的金融级业务系统性能优化实践|社区征文
并创新地开发出HBase分布式事务处理等新技术,从而推出了Trafodion,并将全部代码开源,贡献给社区。应客户的要求,为了能够让业务系统在国产化环境下性能达到最优,对系统从硬件到软件做了全方位的性能优化,包括BIOS... 为了是系统发挥出最大性能,这里还将CPU与数据库实现了绑核优化,具体调整如下:```jsØ 应用绑核:每一个服务绑0-15核,每个微服务各启了1个实例,绑核时候要通过localaloc设置内存亲和性。Ø 数据库绑核:数据库...
火山引擎ByteHouse基于云原生架构的实时导入探索与实践
介绍了ByteHouse的整体架构演进以及基于不同架构的实时导入技术实现。# 架构整体的演进过程## 分布式架构概述ByteHouse是基于社区ClickHouse数据分析管理系统(下文简称社区)来做的产品集成和开发。ClickHous... 分布式架构的扩容成本非常高,而且容易导致线上服务IO热点,进而影响整个集群的稳定性。最后,由于无中心化节点以及事务的缺失,一致性问题是目前社区最为人吐槽的缺陷。显示,数据库系统种类已经多达 870 种,可谓是欣欣向荣,让人眼花缭乱。 特惠活动
特惠活动
 分布式事务是什么?TCC分布式事务是如何实现的?-优选内容
分布式事务是什么?TCC分布式事务是如何实现的?-优选内容
 分布式事务是什么?TCC分布式事务是如何实现的?-相关内容
分布式事务是什么?TCC分布式事务是如何实现的?-相关内容
微服务的学习与实践 主赛道 | 社区征文
安全和事务等。在微服务的技术栈方面,我主要学习了 Spring Boot、Spring Cloud、Docker、Kubernetes、Nacos、Sentinel、OpenFeign、JWT、ElasticSearch 等技术,它们分别涵盖了微服务的开发、构建、部署、注册、发... 实现微服务的按需使用和付费,提高微服务的灵活性和效率。## 微服务的项目经验分享在过去的一年里,我参与了一些微服务的项目,值得一提的是一个是基于 Spring Cloud 的分布式电商项目。在这个项目中,我担任了后端...
分布式数据库在抖音春晚活动中的应用
## 分布式数据库架构简介相信对数据库感兴趣的同学对上面这张图也不会陌生。这... 列存还是行存并不是绝对的,这只是对现有产品特点的总结。- Shared-Storage 架构:目前一些主流的基于 Shared-Storage 架构的产品都是用来处理实时的在线事务。使用这种架构的数据库产品,用户可能会更关心在线事务...
敏捷研发、分布自治:火山引擎业务为先的数据中台新模式
数据开发平台是研发导向的,目标是提高数据研发效率,从而帮助开发者提效。- **第三阶段:全链路数据中台**这里要解决的核心问题是如何支撑业务。一方面要解决数据全生命周期的问题,覆盖从数据需求提升到最终交... 实现提效。## **数据治理闭环**在数据治理闭环中,我们提出了 **“分布式”的理念**。分布式的概念来源于大数据系统,核心是建立一个无中心、且各节点可以单独运行的机制。字节每个业务发展不一样,用一套治理方...
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0(中)
设计目标是实现高扩展性、高性能、高可靠性、高易用性。从下往上,总体上分服务层、计算层和存储层。## 服务层服务层包括了所有与用户交互的内容,包括用户管理、身份验证、查询优化器,事务管理、安全管理、元数... 数据表的数据文件存储在远端的统一分布式存储系统中,与计算节点分离开来。底层存储系统可能会对应不同类型的分布式系统。例如 HDFS,Amazon S3, Google cloud storage,Azure blob storage,阿里云对象存储等等。 ...
干货 | 看 SparkSQL 如何支撑企业级数仓
Hive 已经不单单是一个技术组件,而是一种设计理念。Hive 有 JDBC 客户端,支持标准 JDBC 接口访问的 HiveServer2 服务器,管理元数据服务的 Hive Metastore,以及任务以 MapReduce 分布式任务运行在 YARN 上。标准... 最重要的是如何基于企业业务流程来设计架构,而不是基于某个组件来扩展架构。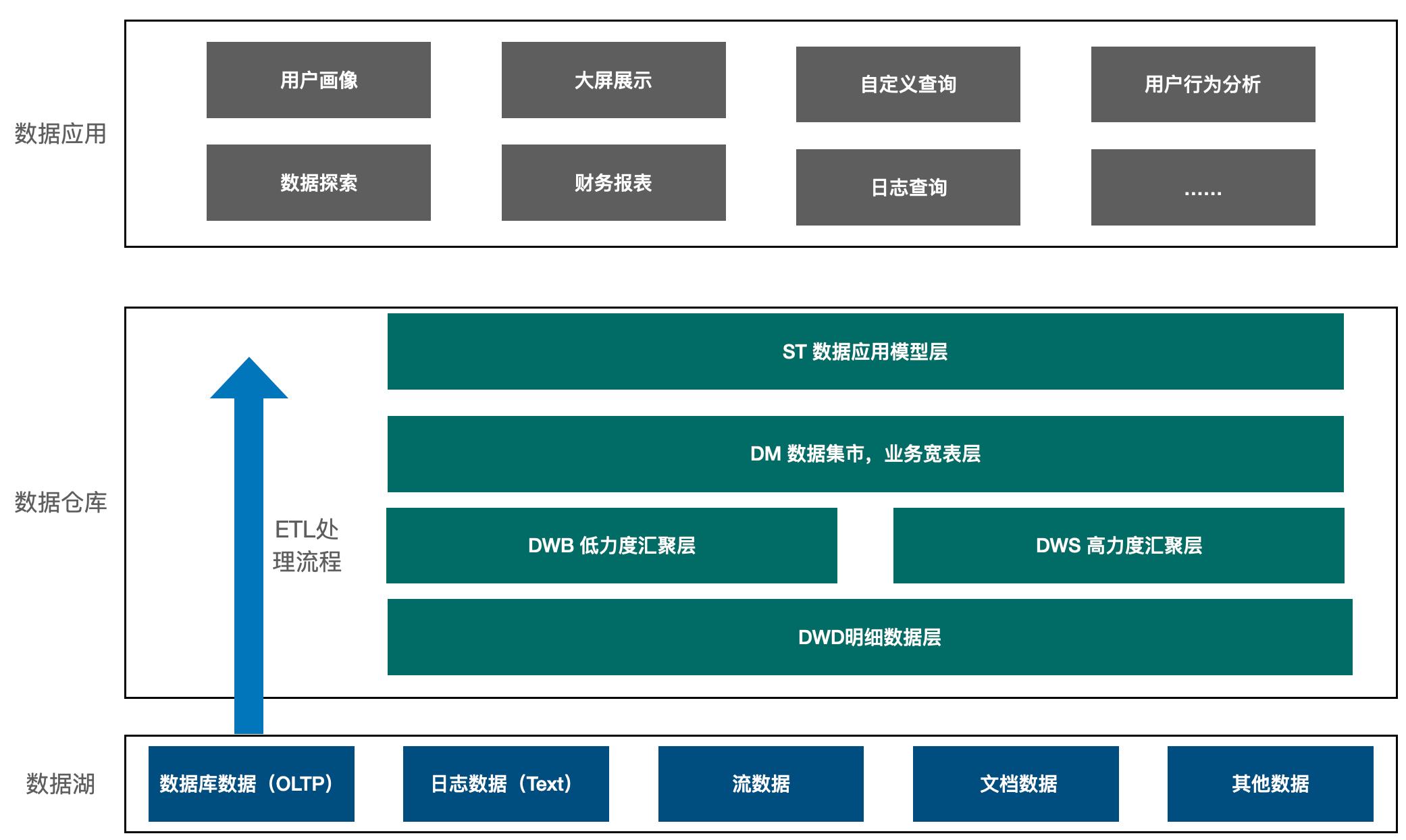一...
观点|SparkSQL在企业级数仓建设的优势
但是Hive集成的节奏却非常慢。* 解耦程度:分布式任务必然需要多个组件的协调,例如分布式存储,资源管理,调度等,像Hive就重度依赖于YARN体系,计算引擎也与MR强绑定,在解耦方面较弱,如果企业考虑在K8S上构建自己的计算引擎,Hive面临的局限会更加明显。* 性能:整体架构是否拥有更好的性能。* 安全:是否支持不同级别,不同力度的用户访问和数据安全鉴权体系。对于企业数仓架构来说,最重要的是如何基于企业业务流程来设计架...
掘地三尺,搞定 Redis 与 MySQL 数据一致性问题 | 社区征文
毕竟是两套系统,如果要保证强一致性,势必要引入 `2PC` 或 `Paxos` 等分布式一致性协议,或者分布式锁等等,这个在实现上是有难度的,而且一定会对性能有影响。如果真的对数据的一致性要求这么高,那引入缓存是否真的... 就涉及到分布式事务的范畴了。**### 3.1 先更新缓存,再更新数据库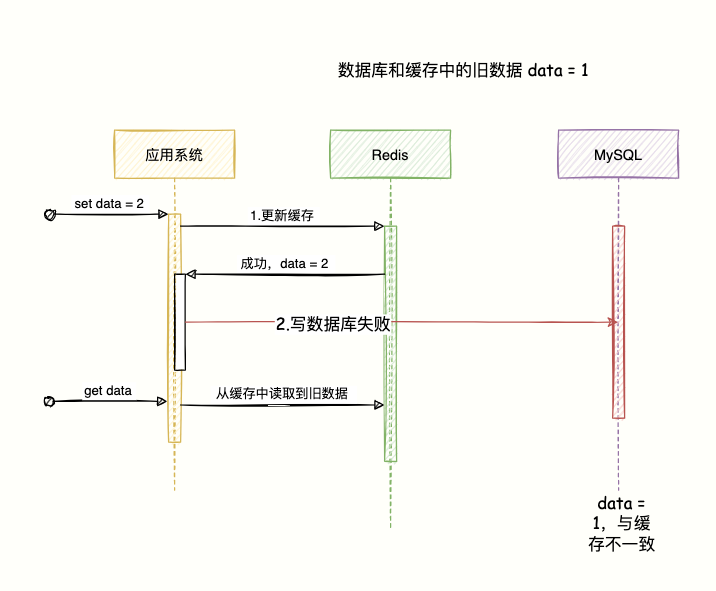如果先更新缓存成功,写数据库...
传统架构 VS 云原生:如何更好的选择搭配
# 前言随着互联网的发展,目前云原生的趋势已经是势在必行,例如容器化、微服务、DevOps、持续交付等等等等,都在大大冲击着传统架构的模式,逼着运维人员去转型。# 过渡先来讲一下我,我也是从传统架构过渡过来的,之前公司的业务模型全部依托于宿主机,虽说也是分布式部署,可扩展,勉强可以算是微服务,但远远达不到持续交付的层次。因此,之前我们尝试过 ansible 以及 shell 脚本作为持续交付的一种方式。ansible 在我看来,也能...
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0(上)
进行了优化设计和工程实现,产品特性和优势如下:**- 存储计算分离:解决了全局元数据管理,过多小文件存储性能差等等技术难题。在最小化性能损耗的情况下,实现存储层与计算层的分离,独立扩缩容。- 新一代 MPP 架构:结合 Shared-nothing 的计算层以及 Shared-everything 的存储层,有效避免了传统 MPP 架构中的 Re-sharding 问题,同时保留了 MPP 并行处理能力。- 数据一致性与事务支持。- 计算资源隔离,读写分离:通过计算...
