Hadoop中的Mapper和Reducer函数依赖文件是否只能与它们放在同一个目录下?如果不是,那么这些文件可以存放在哪些位置?
 社区干货
社区干货
万字长文,Spark 架构原理和 RDD 算子详解一网打进! | 社区征文
Partitioner函数不但决定了RDD本身的分片数量,也决定了parent RDD Shuffle输出时的分片数量。(5)一个列表,存储存取每个Partition的优先位置(preferred location)。对于一个HDFS文件来说,这个列表保存的就是每个P... 也就是说上图中的stage1和stage2相当于mapreduce中的Mapper,而ResultTask所代表的stage3就相当于mapreduce中的reducer。在之前动手操作了一个wordcount程序,因此可知,Hadoop中MapReduce操作中的Mapper和Reducer在...
字节跳动 Spark Shuffle 大规模云原生化演进实践
文件和按 Partition 排序后的数据文件。当所有的 Mappers 写完 Map Output 后,就会开始第二个阶段- Shuffle Read 阶段。这个时候每个 Reducer 会向所有包含它的 Reducer Partition 的 ESS 访问,并读取对应 Reduce... 磁盘和网络开销都很有可能是造成 Fetch Failure 的原因或 Shuffle 速度较慢的瓶颈。在字节跳动大规模的 Shuffle 场景中,同一个 ESS 节点可能需要同时服务多个商户,而这些集群没有进行 IO 的隔离,就可能会导致 Shuf...
字节跳动 MapReduce - Spark 平滑迁移实践
在正式推动下线之前,我们首先统计了 MapReduce 类型作业的业务方和任务维护方式。左边的饼图是业务方的占比统计,占比最大的是 Hadoop Streaming 作业,差不多占到了所有作业的 45%,占比第二名的是 Druid 作业 ... 所以我们通过增加一个中间层去适配用户的代码和 Spark 计算接口,用 MapRunner、 ReduceRunner 适配 Hadoop 里的 Map 和 Reducer 方法,从而使 Spark 的 Map 算子可以运行 Mapper 和 Reducer,我们通过 Counter 的 Ad...
字节跳动 MapReduce - Spark 平滑迁移实践
在正式推动下线之前,我们首先统计了 MapReduce 类型作业的业务方和任务维护方式。左边的饼图是业务方的占比统计,占比最大的是 Hadoop Streaming 作业,差不多占到了所有作业的 45%,占比第二名的是 Druid 作业 ... 所以我们通过增加一个中间层去适配用户的代码和 Spark 计算接口,用 MapRunner、 ReduceRunner 适配 Hadoop 里的 Map 和 Reducer 方法,从而使 Spark 的 Map 算子可以运行 Mapper 和 Reducer,我们通过 Counter 的 Ad...
 特惠活动
特惠活动
 Hadoop中的Mapper和Reducer函数依赖文件是否只能与它们放在同一个目录下?如果不是,那么这些文件可以存放在哪些位置?-优选内容
Hadoop中的Mapper和Reducer函数依赖文件是否只能与它们放在同一个目录下?如果不是,那么这些文件可以存放在哪些位置?-优选内容
 Hadoop中的Mapper和Reducer函数依赖文件是否只能与它们放在同一个目录下?如果不是,那么这些文件可以存放在哪些位置?-相关内容
Hadoop中的Mapper和Reducer函数依赖文件是否只能与它们放在同一个目录下?如果不是,那么这些文件可以存放在哪些位置?-相关内容
干货|火山引擎A/B测试平台如何“嵌入”技术研发流程
然后它就能够把它的流量正确的调度到下游相应的集群。 这个过程中,需要多大流量,分配多少机器,开发人员可以通过OpenAPI是能够把这两件事关联起来的,可以得到恰当的处理。线上的整个升级包括重启机器等都可以非常平稳、非常丝滑。 **SQL** **优化让人秃头,怎么破?**--------------------------再比如Spark SQL的优化,首先想做好优化,优化前需要知道mapper数、reducer数、excutor数等参数怎么设置,还...
Hive SQL 底层执行过程 | 社区征文
我们先来看下 Hive 的底层执行架构图, Hive 的主要组件与 Hadoop 交互的过程: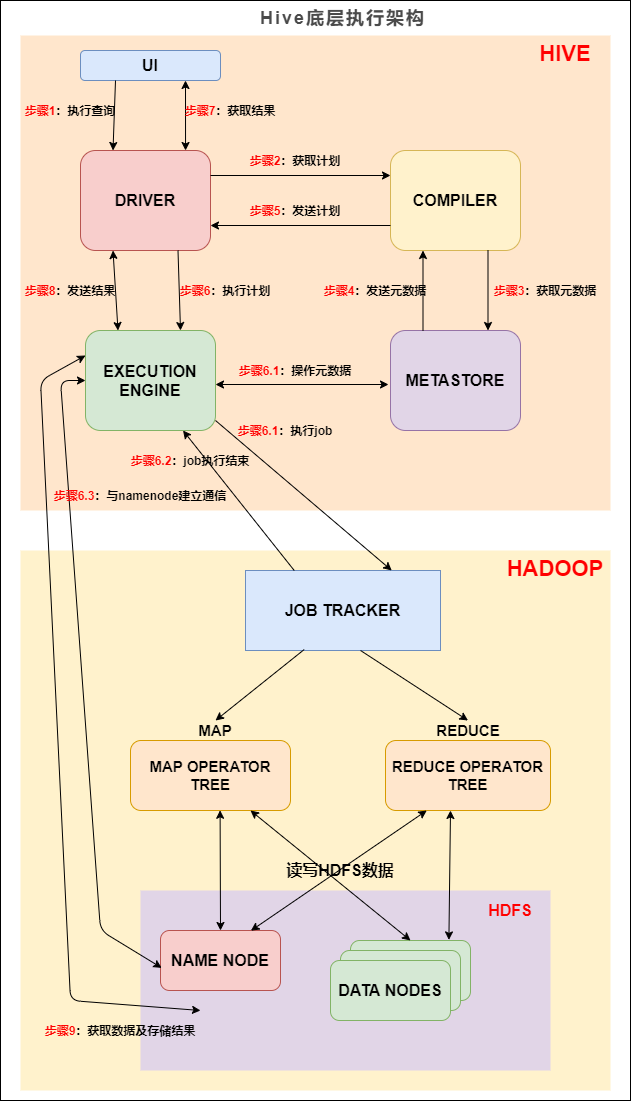在 Hive 这一侧,总共有五个组件:1. UI:用户界面。... 执行引擎将会把这些作业发送给 MapReduce :**步骤6、6.1、6.2和6.3**:执行引擎将这些阶段提交给适当的组件。在每个 task(mapper/reducer) 中,从HDFS文件中读取与表或中间输出相关联的数据,并通过相关算子树传递这...
Flink 使用 Proton
需要下载 Proton SDK,并且做一些额外配置,才能正常使用,可参考 Proton 发行版本,手动下载 Proton SDK。 1 火山 EMR1.1 集群配置火山EMR集群自 3.2.1 版本之后已经默认集成了 Proton 的相关依赖,包括 Hadoop 数据湖... 3 独立 Flink 集群3.1 集群配置独立 Flink 集群和自建 Hadoop+Flink 集群类似,需要在下载 Proton SDK 之后,将proton-flink${flink.version}-${proton.version}.jar拷贝到 flink lib 目录下,然后在core-site.xml或...
Hive 作业调优
本文将为您介绍如何通过调整内存、CPU 和 Task 个数等方式,实现 Hive 作业调优。 1 调优方案总览调优方向 调优方案 代码优化 代码优化 参数调优 内存参数 CPU 参数 开启向量化 Task 数量优化 合并小文件 2 ... 在一定范围可以减小 default_split_size 的值,从而增加 split_num 的值,增大 mapred.map.tasks 的数量。 3.4.2 Reduce Task 数量优化 通过 hive.exec.reducers.bytes.per.reducer 参数控制单个 Reduce 处理的字节...
UDF
Presto 引擎在执行 UDF 时,基于安全、稳定性考虑,会在远端 FaaS 执行。FaaS 即 Function as a Service,它可以基于自动扩缩容的能力免去扩缩容运维成本。关于 FaaS 在 UDF 的使用,需要注意两点: 当您首次创建函数时... hadoop2.jaraws-java-sdk-1.7.4.jarbcprov-jdk16-1.46.jarbec.jarbonecp-0.8.0.RELEASE.jarbreeze-macros_2.12-1.0.jarbreeze_2.12-1.0.jarbtrace-1.0.3.jarbytedance-data_2.12-2.0.3-SNAPSHOT.jarcaffeine-2.6.2...
