h265cuda
 社区干货
社区干货
nvidia-cuda镜像
## 简介CUDA-X AI 是软件加速库的集合,这些库建立在 CUDA® (NVIDIA 的开创性并行编程模型)之上,提供对于深度学习、机器学习和高性能计算 (HPC) 必不可少的优化功能。下载地址:- 火山引擎访问地址:https://mirrors.ivolces.com/nvidia_all/- 公网访问地址:https://mirrors.volces.com/nvidia_all/## 相关链接官方主页:[https://www.nvidia.cn/technologies/cuda-x/](https://www.nvidia.cn/technologies/cuda-x/?spm=a...
Linux安装CUDA
# 运行环境* CentOS* RHEL* Ubuntu* OpenSUSE# 问题描述初始创建的火山引擎实例并没有安装相关cuda软件,需要手动安装。# 解决方案1. 确认驱动版本,以及与驱动匹配的cuda版本,执行命令`nvidia-smi`显示如下。 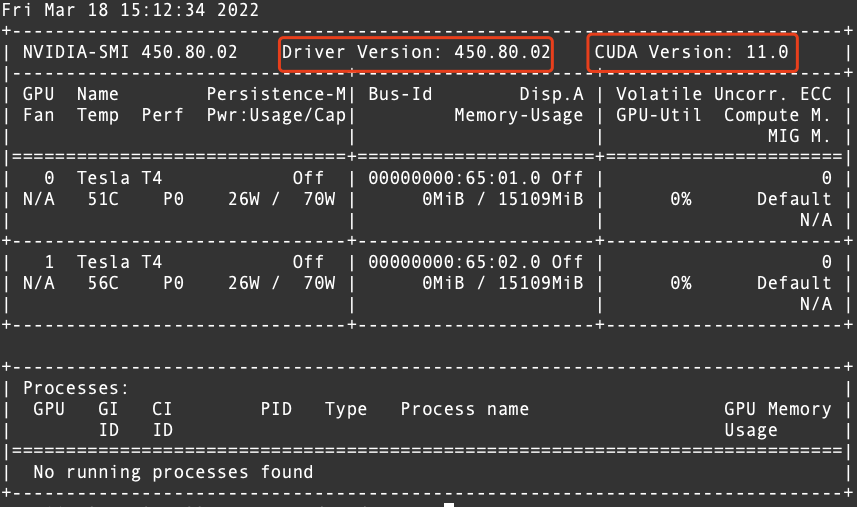 从上图中可以确认CUDA的版本为 11.02. 从英伟达官方网站下载相对应的 CUDA 版本的...
大模型:深度学习之旅与未来趋势|社区征文
device = torch.device("cuda" if torch.cuda.is_available() else "cpu") input_tensors = input_tensors.to(device) model.to(device) with torch.no_grad(): outputs = model(input_tensors) predictions = torch.argmax(outputs.logits, dim=2).squeeze().tolist() # 解码预测结果 tokens = tokenizer.convert_ids_to_tokens(input_ids) labels = [tokenizer.decode([pred]) ...
探索大模型知识库:技术学习与个人成长分享 | 社区征文
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')model.to(device)for epoch in range(10): train_loss = train(model, train_loader, criterion, optimizer) test_loss, test_acc = evaluate(model, test_loader, criterion) print(f'Epoch {epoch + 1}: Training loss = {train_loss:.4f}, Test loss = {test_loss:.4f}, Test accuracy = {test_acc:.4f}')```我们使用 PyTorch 和 H...
 特惠活动
特惠活动
 h265cuda-优选内容
h265cuda-优选内容
 h265cuda-相关内容
h265cuda-相关内容
新功能发布记录
CUDA和CUDNN库。 全部 商用 驱动安装指引 2023年11月24日序号 功能描述 发布地域 阶段 文档 1 邀测上线GPU计算型gni3实例。 华东2(上海) 邀测 GPU计算型gni3 2023年09月08日序号 功能描述 发布地域 阶段 文档 1 部署了HPC GPU实例的高性能计算集群最多支持绑定5个vePFS文件系统。 华北2(北京) 邀测 管理vePFS存储资源 2023年08月17日序号 功能描述 发布地域 阶段 文档 1 正式上线GPU计算型gni2、GPU渲染型gni2-vws实例。 华北2(北...
新功能发布记录
对业务侧使用的 CUDA 等软件不同版本进行适配。 华北 2 (北京) 2024-01-31 自定义 GPU 驱动安装说明 华南 1 (广州) 2024-01-30 华东 2 (上海) 2024-01-30 AIOps 套件支持生成和下载巡检/故障诊断报告 【邀测·申请试用】在集群巡检/故障诊断的报告详情中增加下载报告的功能。方便多方介入排障时,共享下载的集群巡检和故障诊断报告,协作排障。 华北 2 (北京) 2024-01-31 配置集群巡检 华南 1 (广州) 2024-01-30 华东 2 (上海) 202...
大模型:深度学习之旅与未来趋势|社区征文
device = torch.device("cuda" if torch.cuda.is_available() else "cpu") input_tensors = input_tensors.to(device) model.to(device) with torch.no_grad(): outputs = model(input_tensors) predictions = torch.argmax(outputs.logits, dim=2).squeeze().tolist() # 解码预测结果 tokens = tokenizer.convert_ids_to_tokens(input_ids) labels = [tokenizer.decode([pred]) ...
探索大模型知识库:技术学习与个人成长分享 | 社区征文
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')model.to(device)for epoch in range(10): train_loss = train(model, train_loader, criterion, optimizer) test_loss, test_acc = evaluate(model, test_loader, criterion) print(f'Epoch {epoch + 1}: Training loss = {train_loss:.4f}, Test loss = {test_loss:.4f}, Test accuracy = {test_acc:.4f}')```我们使用 PyTorch 和 H...
AI ASIC 的基准测试、优化和生态系统协作的整合|KubeCon China
而各家 ASIC 由于具备类似 CUDA 的开发生态,往往都需要单独适配,且各家 ASIC 往往都会自带一套自身的软件栈,从使用方式,硬件管理,监控接入等层面,都需要额外开发。这些相比沿用 GPU,都是额外成本。 **不透明性体现在哪?**关于不透明性,就像刚才 Habana 的例子提到的,ASIC 的架构乍一看会很简单,但其实很多硬件的设计细节作为核心技术,作为终端...
【高效视频处理】一窥火山引擎多媒体处理框架-BMF|社区征文
它还支持不同框架如CUDA和OpenCL之间的异构计算。从这些建议简单实验开始, 开发者就可以感受到BMF模块化设计及其强大的处理能力。同时,它提供Python、C++和Go三种语言接口,语法简洁易用,无门槛上手。通过这些基础功能,我们已经看到BMF在视频管道工程中的广阔地平线。> 深入原理学习如何创建自己的视频处理模块,必然需要了解BMF内部工作机制:多媒体处理框架 BMF 的整体架构分为应用层、框架层、模块层和异构层,共 4 个部分...
GPU实例部署paddlepaddle-gpu环境
本文介绍 GPU 实例部署深度学习Paddle环境。 前言 在ECS GPU实例上部署深度学习Paddle环境。 关于实验 预计实验时间:20分钟级别:初级相关产品:ECS受众: 通用 环境说明 本文测试规格如下:实例规格:ecs.pni2.3xlargeGPU 类型:Tesla A100 80G显存容量:81920MiB实例镜像:velinux - 1.0 with GPU DriverNVIDIA-SMI:470.57.02NVIDIA Driver version:470.57.02CUDA version:11.4CUDA Toolkit version:11.2Python version:Python 3.7.3pa...
通过工作流串联训练与评测任务
args = parser.parse_args() device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu') print(f"use device={device}, local_rank={args.local_rank}") if args.local_rank >= 0: torch.cuda.set_device(args.local_rank) dist.init_process_group(backend="nccl") if args.train: trainset = torchvision.datasets.CIFAR10(root=args.data_path, train=True, ...
【高效视频处理】体验火山引擎多媒体处理框架 BMF |社区征文
确保系统环境中已经安装了必要的 GPU 驱动和 CUDA 工具包,这对于 BMF 的 GPU 加速至关重要。- Windows 平台——虽然 Windows 不是 BMF 的主要开发平台,但在某些情况下需要在 Windows 环境中进行部署。我选择了一台配备了强大 GPU 的 Windows 机器,并确保系统中安装了相应的开发工具。- Mac OS 平台——Mac OS 平台也是 BMF 支持的一个选项。在我的体验中,我选择了一台配备了高性能 GPU 的 Mac 机器进行尝试。在这个过程中,...
