怎么把hdfs转到ubuntu
 社区干货
社区干货
干货 | 提速 10 倍!源自字节跳动的新型云原生 Spark History Server正式发布
火山引擎 LAS 团队将向大家详细介绍字节跳动内部是怎么基于 UIMeta 实现海量数据业务的平稳和高效运转,让技术驱动业务不断发展。 。通常一个机房的任务的文件都存储在一个路径下。在 History Server 侧,核心逻辑在 `FsHistoryProvider`中。`FsHistoryProvider` 会维持一个线程间歇扫描配置好的 event log 存储路径,遍...
20000字详解大厂实时数仓建设 | 社区征文
我们是如何去做的?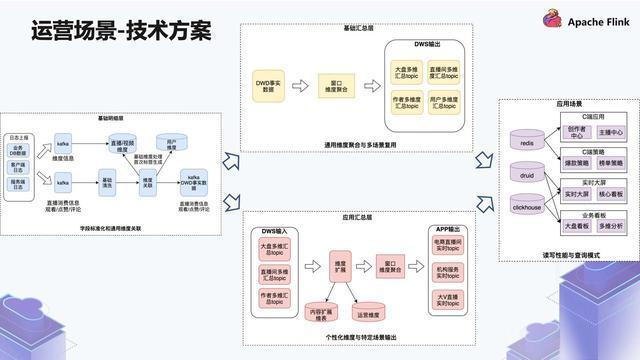首先看一下基础明细层 (图中左方),数据源有两条链路,其中一条链路是消费的流,比如直播的消费信息,还有观看 / 点赞 / 评论。经过... 原始数据都存放在 HDFS 上,扩容只是 Region Server 扩容,不涉及原始数据的迁移。但是 Clickhouse 的每个分片数据都是在本地,是一个比较底层存储引擎,不能像 HBase 那样方便扩容。Redis 是哈希槽这种类似一致性哈...
「火山引擎」数智平台 VeDI 数据中台产品双月刊 VOL.04
访问迁移和模型设计更加便捷。- **【新增ByteHouse企业版功能】** - 在社区版本 MaterializeMySQL 库引擎的基础上支持了集群模式(Distributed_mode),支持将 MySQL 中的库同步到集群并自动分布到每个节点... **更少的存储**:对象存储没有 HDFS 副本概念,按照默认 3 副本,计算存算分离占据的存储容量只有 HDFS 的三分之一。 - **按需的计算:** 无需常驻 DataNode,按需弹性使用计算节点,减少常驻节点,成本减...
「火山引擎」数智平台 VeDI 数据中台产品双月刊 VOL.04
访问迁移和模型设计更加便捷。- **【新增ByteHouse企业版功能】** - 在社区版本 MaterializeMySQL 库引擎的基础上支持了集群模式(Distributed_mode),支持将 MySQL 中的库同步到集群并自动分布到每个节点... 为 Oozie 系统用户赋予 HDFS 全路径、Hive 库表、YARN 队列等资源的权限;在 Ranger 中默认为系统用户配置 HDFS 等资源的权限。**说明文档链接(非微信域内链接)**:https://www.volcengine.com/docs/6491/72143...
 特惠活动
特惠活动
 怎么把hdfs转到ubuntu-优选内容
怎么把hdfs转到ubuntu-优选内容
 怎么把hdfs转到ubuntu-相关内容
怎么把hdfs转到ubuntu-相关内容
干货 | 提速 10 倍!源自字节跳动的新型云原生 Spark History Server正式发布
火山引擎 LAS 团队将向大家详细介绍字节跳动内部是怎么基于 UIMeta 实现海量数据业务的平稳和高效运转,让技术驱动业务不断发展。 。通常一个机房的任务的文件都存储在一个路径下。在 History Server 侧,核心逻辑在 `FsHistoryProvider`中。`FsHistoryProvider` 会维持一个线程间歇扫描配置好的 event log 存储路径,遍...
V2.58.0
改成直接传输数据到 hdfs。如下图所示: 【优化】更多技术细节优化 (1)在数据连接的 Redshift 数据源抽取中新增支持 text, super类型的字段接入。(2)文件上传支持解析百分数 2.1.2 可视化建模新功能【新增】自定义S... 如一键转大写、一键转小写、一键修复非法字符一键修正不规范数据,支持字段快捷排序,提高数据处理效率。 【新增】输出节点支持字段修正 可视化建模的输出节点,支持字段修正,当上游节点字段格式同目标存储的字段格式...
20000字详解大厂实时数仓建设 | 社区征文
我们是如何去做的?首先看一下基础明细层 (图中左方),数据源有两条链路,其中一条链路是消费的流,比如直播的消费信息,还有观看 / 点赞 / 评论。经过... 原始数据都存放在 HDFS 上,扩容只是 Region Server 扩容,不涉及原始数据的迁移。但是 Clickhouse 的每个分片数据都是在本地,是一个比较底层存储引擎,不能像 HBase 那样方便扩容。Redis 是哈希槽这种类似一致性哈...
「火山引擎」数智平台 VeDI 数据中台产品双月刊 VOL.04
访问迁移和模型设计更加便捷。- **【新增ByteHouse企业版功能】** - 在社区版本 MaterializeMySQL 库引擎的基础上支持了集群模式(Distributed_mode),支持将 MySQL 中的库同步到集群并自动分布到每个节点... **更少的存储**:对象存储没有 HDFS 副本概念,按照默认 3 副本,计算存算分离占据的存储容量只有 HDFS 的三分之一。 - **按需的计算:** 无需常驻 DataNode,按需弹性使用计算节点,减少常驻节点,成本减...
「火山引擎」数智平台 VeDI 数据中台产品双月刊 VOL.04
访问迁移和模型设计更加便捷。- **【新增ByteHouse企业版功能】** - 在社区版本 MaterializeMySQL 库引擎的基础上支持了集群模式(Distributed_mode),支持将 MySQL 中的库同步到集群并自动分布到每个节点... 为 Oozie 系统用户赋予 HDFS 全路径、Hive 库表、YARN 队列等资源的权限;在 Ranger 中默认为系统用户配置 HDFS 等资源的权限。**说明文档链接(非微信域内链接)**:https://www.volcengine.com/docs/6491/72143...
干货|什么是瞬态集群?解读火山引擎EMR Stateless 的创新理念以及应用
再将任务提交上去,接下来无论是通过 IO 的直接返回,还是把数据写入到 HDFS 或是对象存储,执行结束后都将拿到历史结果。站在大数据维护视角来看,在提交任务的流程结束以后,运维长时间运行的集群,无论是对它的运... 这种情况下直到所有任务执行完毕,实体集群就会被释放。当集群释放完以后,如果又有任务需要提交了,同理,只需要再去起一个配置相同的集群,再来做任务的执行,执行完了以后再释放。这就是Stateless 体系运转的大致流程...
开源数据集成平台SeaTunnel:MySQL实时同步到es
项目有几个表要从 MySQL 实时同步到 另一个 MySQL,也有同步到 ElasticSearch 的。- 目前,公司生产环境同步,用的是 阿里云的 DTS,每个同步任务每月 500多元,有点小贵。- 其他环境:MySQL同步到ES,用的是 CloudCanal,不支持 数据转换,添加同步字段比较麻烦,社区版限制5个任务,不够用;MySQL同步到MySQL,用的是 debezium,不支持写入 ES。- 恰好3年前用过 SeaTunnel 的 前身 WaterDrop,那就开始吧。本文以 2.3.1 版本,Ubuntu 系统为...
干货|数据湖技术在抖音近实时场景的实践
底层存储兼容各类文件系统 (HDFS、Amazon S3、GCS、OSS)* Hudi 使用 Timeline Service机制对数据版本进行管理,实现了数据近实时增量读、写。* Hudi 支持 Merge on Read / Copy on Write 两种表类型,以及Read... 转换为复用用流计算当日更新增量的结果, 从而提高离线数据的产出时效性 。降低数据基线破线的风险。通过复用批流计算的结果,也可以提高开发的人效。* 统一存储:字节数据湖采用HDFS作为底层存储层,通过将ods、...
干货 | 实时数据湖在字节跳动的实践
这个异构问题是如何导致的呢?为什么Hive Matestore 没有办法去满足元数据管理的这个诉求?这就涉及到数据湖管理元数据的特殊性。以Hudi为例,作为一个典型的事务型数据湖,Hudi使用时间线 Timeline 来追踪针对表... 通过同步到Hive Metastore来做元数据的展示。这个过程中我们发现了三个问题。第一个问题就是分区的元数据是分散在两个系统当中的,缺乏 single source of true。第二个是分区的元数据的获取需要从 HDFS 拉取多...
