怎么把hdfs挂到ubuntu
 社区干货
社区干货
ByConity 0.2.0 版本发布
同时支持将 Hive 的统计信息集成到 ByConity 的优化器。该版本同时支持 HDFS 和 S3 存储。## Hudi 表引擎该版本实现 Hudi 两种类型表的支持:Copy On Write 表和 Merge On Read 表。ByConity 实现了对 Hudi CoW 表的进行快照查询。在开启 JNI Reader 后可以支持 MoR 表的读取。ByConity 引入 JNI 模块来调用 Hudi Java 客户端读取数据。并且通过 Arrow 实现内存数据在 Java 与 C++之间的交换。## Multi-Catalog为了更方便...
ByConity 0.2.0 版本发布
同时支持将 Hive 的统计信息集成到 ByConity 的优化器。该版本同时支持 HDFS 和 S3 存储。 **Hudi 表引擎**该版本实现 Hudi 两种类型表的支持:Copy On Write 表和 Merge On Read 表。ByConity 实现了对 Hudi CoW 表的进行快照查询。在开启 JNI Reader 后可以支持 MoR 表的读取。ByConity 引入 JNI 模块来调用 Hudi Java 客户端读取数据。并且通过 Arrow 实现内存数据在 Java 与 C++ 之间的交换。 **Multi-Catalog**...
为君作磐石——人人都能搭建大规模推荐系统
它会定时将更新的参数发送到 Online PS,从而实现实时增量更新。此外,特征过滤,特征淘汰等也在 PS 上进行。* 在训练过程中或训练结束时,会写 checkpoint。为了加速 checkpoint,Monolith 没有延用 TF 中的 saveable,而是利用 estimator saving listener,流式多线程地存取,性能大副提升。为了减少 checkpoint 体积,会将过期特征淘汰。**在线推理*** 加载 saved\_model。Entry 本质上是 TF Serving,它会从 HDFS 上加载非 Emb...
干货 | 看 SparkSQL 如何支撑企业级数仓
最重要的是如何基于企业业务流程来设计架构,而不是基于某个组件来扩展架构。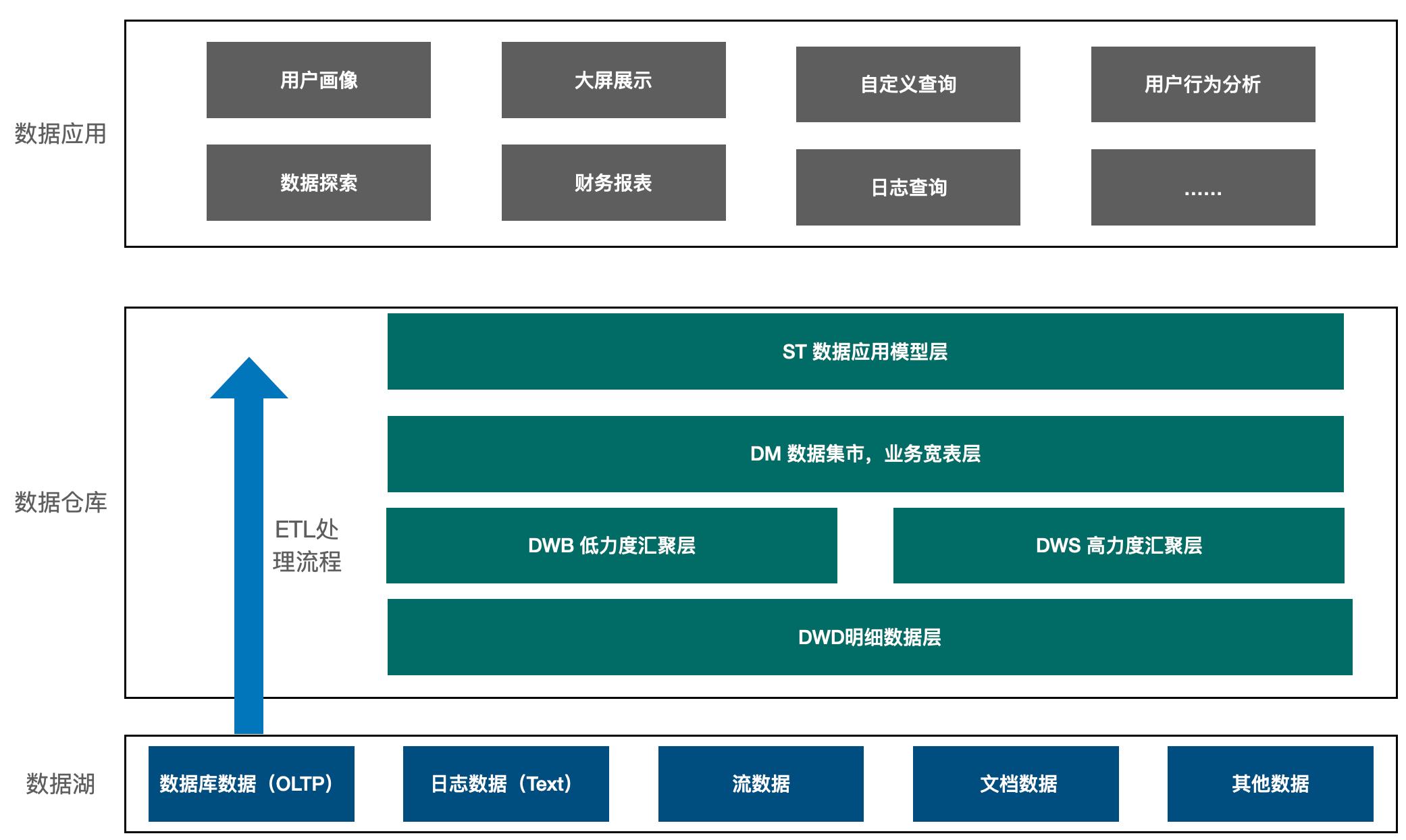一... 数据保存于 HDFS 等分布式存储系统上,自身不管理数据,具有极高的稳定性和容错处理机制。反过来,因为 Hive,Spark 更善于处理这类批处理的长时任务,因此这类组件不擅长与上层的交互式分析,对于这种对于时效性要求更...
 特惠活动
特惠活动
 怎么把hdfs挂到ubuntu-优选内容
怎么把hdfs挂到ubuntu-优选内容
 怎么把hdfs挂到ubuntu-相关内容
怎么把hdfs挂到ubuntu-相关内容
ByConity 0.2.0 版本发布
同时支持将 Hive 的统计信息集成到 ByConity 的优化器。该版本同时支持 HDFS 和 S3 存储。 **Hudi 表引擎**该版本实现 Hudi 两种类型表的支持:Copy On Write 表和 Merge On Read 表。ByConity 实现了对 Hudi CoW 表的进行快照查询。在开启 JNI Reader 后可以支持 MoR 表的读取。ByConity 引入 JNI 模块来调用 Hudi Java 客户端读取数据。并且通过 Arrow 实现内存数据在 Java 与 C++ 之间的交换。 **Multi-Catalog**...
使用大数据文件存储静态存储卷
大数据文件存储(Cloud File System , 简称 CloudFS)是火山引擎面向大数据和机器学习生态的文件存储和加速服务,支持标准的 HDFS 协议访问和数据湖透明访问模式,为您提供低成本、高性能、高吞吐和高可用的大数据文件访问服务。 容器服务支持通过 CSI 使用大数据文件存储,本文为您介绍如何创建大数据文件存储类型的存储卷和存储卷声明,以及工作负载如何使用大数据文件存储静态存储卷。 说明 【邀测·申请试用】该功能目前处于邀测阶...
EMR 1.1.0版本说明
环境信息 系统环境版本 环境 OS Debian 9.13 Python2 2.7.13 Python3 3.5.3 Java 1.8.0_312 应用程序版本组件 Hadoop集群 Flink集群 Kafka集群 Flume 1.9.0 1.9.0 1.9.0 OpenLDAP 2.4.58 2.4.58 2.4.58 Ranger 2.1.0 2.1.0 2.1.0 ZooKeeper 3.5.7 3.5.7 3.5.7 Flink 1.11 1.11 - HDFS 3.3.1 3.3.1 - MapReduce2 3.3.1 3.3.1 - YARN 3.3.1 3.3.1 - Airflow 2.2.0 - - Hive 3.1.2 - - Hue 4.9.0 - - Kafka - - - Knox 1.5.0 - - Pr...
为君作磐石——人人都能搭建大规模推荐系统
它会定时将更新的参数发送到 Online PS,从而实现实时增量更新。此外,特征过滤,特征淘汰等也在 PS 上进行。* 在训练过程中或训练结束时,会写 checkpoint。为了加速 checkpoint,Monolith 没有延用 TF 中的 saveable,而是利用 estimator saving listener,流式多线程地存取,性能大副提升。为了减少 checkpoint 体积,会将过期特征淘汰。**在线推理*** 加载 saved\_model。Entry 本质上是 TF Serving,它会从 HDFS 上加载非 Emb...
干货 | 看 SparkSQL 如何支撑企业级数仓
最重要的是如何基于企业业务流程来设计架构,而不是基于某个组件来扩展架构。一... 数据保存于 HDFS 等分布式存储系统上,自身不管理数据,具有极高的稳定性和容错处理机制。反过来,因为 Hive,Spark 更善于处理这类批处理的长时任务,因此这类组件不擅长与上层的交互式分析,对于这种对于时效性要求更...
干货|揭秘字节跳动对Apache Doris 数据湖联邦分析的升级和优化
如果我们把数据湖和实时数仓进行融合,利用实时数仓的快速分析能力去查询数据湖中的海量数据,势必将会给企业带来更高的价值。 数据湖和实时数仓具备不同特点: **● 数据湖:** 提供多模存储引擎,如 S3、HDFS 等,也支持多计算引擎,如 Hive、Spark、Flink 等。在事务性方面,数据湖支持 ACID 和 snapshot 等方式。同时,数据湖提供了 Hudi、Iceberg、DeltaLake 等表格式的定义,也支持结构化、半结构化和非结构化数据。 **● 实时...
看火山引擎DataLeap如何做好电商治理(二):案例分析与解决方案
在预处理完这些数据之后会把数据放到 Hive 表,或者是放到 HDFS 上面去,这些数据在HDFS上可以设置长久保存。这就很好的满足了在实际应用场景中需要收集很长一段数据的需求,不必受存储的有效期只有 7 天时间的限制。