数据仓库实施难点
 社区干货
社区干货
浅谈数仓建设及数据治理 | 社区征文
## 一、前言在谈数仓之前,先来看下面几个问题:### 1. 数仓为什么要分层?1. 用空间换时间,通过大量的预处理来提升应用系统的用户体验(效率),因此数据仓库会存在大量冗余的数据;不分层的话,如果源业务系统的业... **一张图总结下数据仓库的构建整体流程**: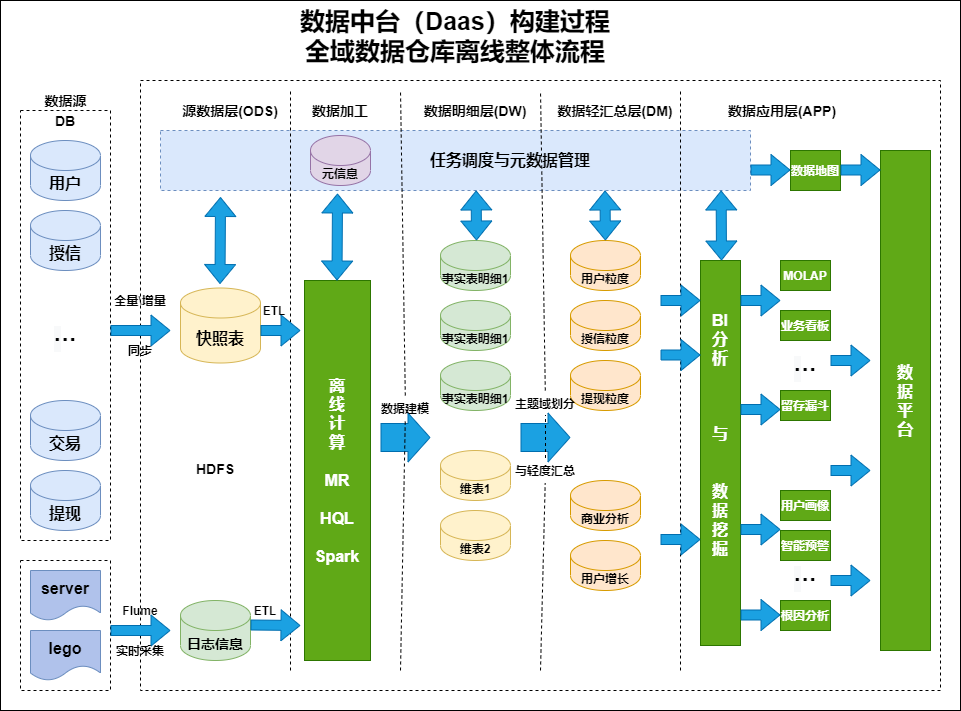## 数据治理**数仓建设真正的难点不在于数仓设计,而在于后续业务发展起来,业务线变的庞...
ELT in ByteHouse 实践与展望
> 更多技术交流、求职机会,欢迎关注字节跳动数据平台微信公众号,回复【1】进入官方交流群谈到数据仓库, 一定离不开使用Extract-Transform-Load (ETL)或 Extract-Load-Transform (ELT)。 将来源不同、格式各异的数... 传统大数据解决的方案有两大难点:慢和难。分别体现在传统大数据方案在及时性上达不到要求以及传统数仓ETL对人员要求高、定位难和链路复杂。但是ByteHouse可以轻松的解决上述问题:将hive数据直接导入到ByteHouse,...
ELT in ByteHouse 实践与展望
谈到数据仓库, 一定离不开使用 Extract-Transform-Load (ETL)或 Extract-Load-Transform (ELT)。将来源不同、格式各异的数据提取到数据仓库中,并进行处理加工。传统的数据转换过程一般采用 Extract-Transform-L... 传统大数据解决的方案有两大难点:慢和难。分别体现在传统大数据方案在及时性上达不到要求以及传统数仓 ETL 对人员要求高、定位难和链路复杂。但是ByteHouse可以轻松地解决上述问题:将hive数据直接导入到ByteHou...
干货 | 看 SparkSQL 如何支撑企业级数仓
特别是几乎完全以结构化数据为主的企业在实施上会把数据湖和企业数仓库合并,基于某个数仓平台合二为一。企业在考虑构建自身数仓体系的时候,虽然需要参考现有的行业技术体系,以及可以选择的组件服务,但是不能太过于局限于组件本身,寻找 100%开箱即用的产品。太过于局限于寻找完全契合的组件服务必然受限于服务本身的实现,给未来扩展留下巨大的约束。企业数据仓库架构必然不等于一个组件,大部分企业在数仓架构实施的都是都是基于...
 特惠活动
特惠活动
 数据仓库实施难点-优选内容
数据仓库实施难点-优选内容
 数据仓库实施难点-相关内容
数据仓库实施难点-相关内容
观点|SparkSQL在企业级数仓建设的优势
特别是几乎完全以结构化数据为主的企业在实施上会把数据湖和企业数仓库合并,基于某个数仓平台合二为一。企业在考虑构建自身数仓体系的时候,虽然需要参考现有的行业技术体系,以及可以选择的组件服务,但是不能太过于局限于组件本身,寻找100%开箱即用的产品。太过于局限于寻找完全契合的组件服务必然受限于服务本身的实现,给未来扩展留下巨大的约束。企业数据仓库架构必然不等于一个组件,大部分企业在数仓架构实施的都是都...
SparkSQL 在企业级数仓建设的优势
用来做异构数据的存储以及数据的冷备份。但是也有很多企业,特别是几乎完全以结构化数据为主的企业在实施上会把数据湖和企业数仓库合并,基于某个数仓平台合二为一。企业在考虑构建自身数仓体系的时候,虽然需要参考现有的行业技术体系,以及可以选择的组件服务,但是不能太过于局限于组件本身,寻找100%开箱即用的产品。太过于局限于寻找完全契合的组件服务必然受限于服务本身的实现,给未来扩展留下巨大的约束。企业数据仓库架构必...
当OLAP碰撞Serverless,看ByteHouse如何建设下一代云计算架构
作为一款火山引擎推出的云原生数据仓库,ByteHouse 基于开源 ClickHouse 构建,并在字节跳动内外部场景的检验下,对 OLAP 引擎能力、性能、运维、架构进一步升级。除此之外,ByteHouse 也在 Serverless 方向探索,基于 ... 仍然存在一些技术难点。 首先,OLAP 数据分析涉及到存储、网络、操作系统、数据库、AI 等 IT 领域几乎全栈的技术点,需要厂商做持续的、高成本的研发投入。而且这些投入短期内难见市场回报,一旦中途停顿则意味...
干货 | ELT in ByteHouse 实践与展望
火山引擎ByteHouse 是一款基于开源 ClickHouse 推出的云原生数据仓库,本篇文章将介绍 ByteHouse 团队如何在 ClickHouse 的基础上,构建并优化 ELT 能力,具体包括四部分: **●** ByteHouse 在字节的应... 传统大数据解决的方案有两大难点:慢和难。分别体现在传统大数据方案在及时性上达不到要求以及传统数仓**ETL**对人员要求高、定位难和链路复杂。 但是**ByteHouse**可以轻松地解决上述问题:将**hive**...
火山引擎ByteHouse:4000字总结,Serverless在OLAP领域应用的五点思考
作为一款火山引擎推出的云原生数据仓库,ByteHouse基于开源ClickHouse构建,并在字节跳动内外部场景的检验下,对OLAP引擎能力、性能、运维、架构进一步升级。除此之外,ByteHouse也在Serverless方向探索,基于cloud-nat... 提高吞吐也是业界在持续解决网络通信层面的难点之一。2. **计算无状态**计算侧通常还是采用经典的shared-nothing架构,具备良好的水平伸缩扩展性,但是计算侧的无状态化程度直接关系到弹性能力的优劣,这其中元数...
干货|解析云原生数仓ByteHouse如何构建高性能向量检索技术
用来提升非结构化数据的分析和检索能力。ByteHouse是火山引擎推出的云原生数据仓库,近期推出高性能向量检索能力, **本篇将结合ByteHouse团队对向量数据库行业和技术的前沿观察,详细解读OLAP引擎如何建设高性能的向... ByteHouse 主要克服以下三大难点: **1.读放大问题** **根本原因:**ByteHouse 中,当前最小的读取单元是一个 mark,即便通过 Vector Index 查询得到结果是有行号信息的,但是在真正读取的...
解析云原生数仓 ByteHouse 如何构建高性能向量检索技术
与完备数据管理和查询支持的数据库形态。这也是 ByteHouse 在设计向量检索相关功能时,主要考虑的一个目标。 ByteHouse 向量检索 ByteHouse 是火山引擎研发的云原生数据仓库产... ByteHouse 主要克服以下三大难点:**读放大问题****根本原因**:ByteHouse 中,当前最小的读取单元是一个 mark,即便通过 Vector Index 查询得到结果是有行号信息的,但是在真正读取的时候仍需要转成对应的...
风很大的“云数仓”到底怎么用?三家企业交出答卷
这些需求无疑对提供基础引擎支持的数据仓库能力,提出了极大的技术挑战。 第一个挑战是数据量。精细化营销所筛选的人群包以及人群基数都是巨大的,做交并补计算所需的大量数据导致查询复杂度高,找定向人群的难... 都变为一串用来判断太阳能板发电效率的数据,自然的庞大力量在电子世界里,为数据的计算能力和实时查询也带来了巨大的难点。 一是地理信息数据处理能力,业务需要丰富的geo函数,用于整合海量的历史气象数据,对目...
「火山引擎」数据中台产品双月刊 VOL.05
火山引擎数据中台产品双月刊涵盖「大数据研发治理套件 DataLeap」「云原生数据仓库 ByteHouse」「湖仓一体分析服务 LAS」「云原生开源大数据平台 E-MapReduce」四款数据中台产品的功能迭代、重点功能介绍、平台最新... 了解自动化解决方案在Spark任务调优中的应用和实施过程,以及所取得的成果和效果。思考计算治理自动化解决方案的优势与局限性,并对未来发展趋势和挑战【活动回放】 ### **【活动】Apache Hudi 中文社区技术交流会...
