dw数据仓库的特征
 社区干货
社区干货
数仓黄金价值圈: 为什么、是什么、怎么做|社区征文
今天给大家一起分享下有着悠久历史的数据仓库的一些思考由三部分组成为什么,搭建数据仓库是什么,数据仓库定义怎么做,如何搭建数仓# 一:为什么,搭建数据仓库最终目标:**数据驱动资源优化配置,即科学、高效... 又称为数据中间层(Common Data Model),包含DWD、DWS、DIM层。- DWD:数据仓库明细层数据(Data Warehouse Detail)。对ODS层数据进行清洗转化,以业务过程作为建模驱动,基于每个具体的业务过程特点,构建最细粒度的明...
干货 | 这样做,能快速构建企业级数据湖仓
Codegen 和向量化都是从数据仓库,而不是 Hadoop 体系的产品中衍生出来。Codegen 是 Hyper 提出的技术,而向量化则是 MonetDB 提出的,所以计算引擎的精细化也是沿着数仓开辟的路子在走。Spark 等 Hadoop 体系均走了 Codegen 的道路,因为 Java 做 Codegen 比做向量化要更容易一些。但现在,向量化是一个更好的选择,因为向量化可以一次处理一批数据,而不只是一条数据。其好处是可以充分利用 CPU 的特性,如 SIMD,Pipeline 执行等...
浅谈数仓建设及数据治理 | 社区征文
**数据应用**。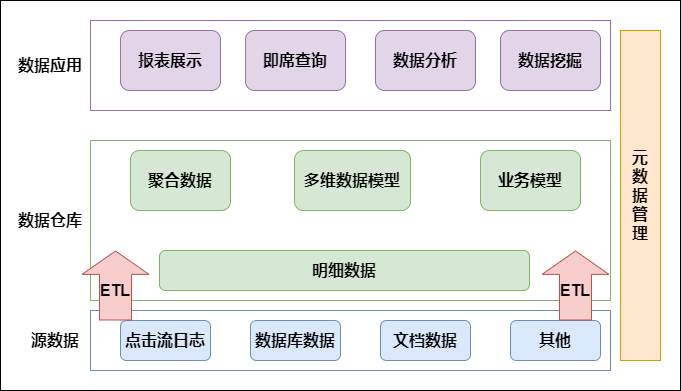数据仓库的数据来源于不同的源数据,并提供多样的数据应用,数据自下而上流入数据仓库后向上层开放应用,而数据仓库只是中间集成化数据管理的一个平台。**源数据**:此层数据无任何更改,直接沿用外围系统数据结构和数据,不对外开放;为临时存储层,是接口数据的临时存储区域,为后一步的数据处理做准备。**数据仓库**:也称为细节层,DW层的数据...
观点|SparkSQL在企业级数仓建设的优势
以及元数据中心,这一系列组合让Hive完整的具备了构建一个企业级数据仓库的所有特性,并且Hive的SQL服务器是目前使用最广泛的标准服务器。虽然Hive有非常明显的优点,可以找出完全替代Hive的组件寥寥无几,但是并... 基于业务系统采集的结构化和非结构化数据进行各种ETL处理成为DWD层,再基于DWD层设计上层的数据模型层,形成DM,中间会有DWB/DWS作为部分中间过程数据。从技术选型来说,从数据源的ETL到数据模型的构建通常需要长...
 特惠活动
特惠活动
 dw数据仓库的特征-优选内容
dw数据仓库的特征-优选内容
 dw数据仓库的特征-相关内容
dw数据仓库的特征-相关内容
干货|ByteHouse:百万级TPS!看字节跳动如何基于ClickHouse落地高性能实时数仓
数据仓库,为用户带来极速分析体验,能够支撑实时数据分析和海量数据离线分析。便捷的弹性扩缩容能力,极致分析性能和丰富的企业级特性,助力客户数字化转型。> > > > > **全篇将从两个版块讲解 ByteHouse 的技术... 各种各样的数据源都可以通过Kafka或者Flink写入到ByteHouse里面,然后来对接上层的应用。按照数仓分层角度,Kafka、Flink可以理解为ODS层,那ByteHouse就可以理解为DWD和DWS层。如果说有聚合或者预计算的场景,也...
【活动推荐】揭秘新一代云数仓技术架构与最佳实践
以云原生数仓为中心的现代数据栈时代已然到来。背后的核心的原因在于,企业正在加速走向数字化、智能化,对数据的应用也提出了全新要求,特别是对数据的实时分析、实时部署需求更加的强烈,而云数据仓库为用户实现云... 技术特点* 核心特点拆解:如何实现存算分离、性能突破、动态扩容缩容、弹性伸缩等* 云数仓典型案例和应用场景**演讲议题二:从「三个落地案例」剖析字节跳动云数仓最佳实践****演讲人:火山引擎解决方案...
以 100GB SSB 性能测试为例,通过 ByteHouse 云数仓开启你的数据分析之路
按实际使用付费的特性也极大地降低了企业和个人的上手门槛,能够在短短数分钟内体验到数据分析的魅力。 Talk is cheap, 接下来就让我们通过一个实战案例来体验下 ByteHouse 云数仓的强大功能。 ## II. ... dwdate 以及 supplier,每张维度表通过 Primary Key 和事实表进行关联。测试通过执行 13 条 SQL 进行查询,包含了多表关联,group by,复杂条件等多种组合。更多详细信息请参考 [SSB 文献](https://xie.infoq.cn/link...
浅谈大数据建模的主要技术:维度建模 | 社区征文
## 前言我们不管是基于 Hadoop 的数据仓库(如 Hive ),还是基于传统 MPP 架构的数据仓库(如Teradata ),抑或是基于传统 Oracle 、MySQL 、MS SQL Server 关系型数据库的数据仓库,其实都面临如下问题:- 怎么组织数据仓库中的数据?- 怎么组织才能使得数据的使用最为方便和便捷?- 怎么组织才能使得数据仓库具有良好的可扩展性和可维护性?> **Ralph Kimball 维度建模理论很好地回答和解决了上述问题。**维度建模理论和技术也是...
干货|从ETL到ELT,揭秘火山引擎ByteHouse的技术实现
谈到数据仓库, 一定离不开使用Extract-Transform-Load (ETL)或 Extract-Load-Transform (ELT) 将来源不同、格式各异的数据提取到数据仓库中。 作为云原生数据仓库, **火山引擎ByteHouse已支持ELT能力,让... **火山引擎ByteHouse是一款基于开源ClickHouse推出的云原生数据仓库,**为用户提供极速分析体验,能够支撑实时数据分析和海量数据离线分析,同时还具备便捷的弹性扩缩容能力,极致分析性能和丰富的企业级特性。**凭借...
基于火山引擎 EMR 构建企业级数据湖仓
非结构化数据,支持多种场景的能力,同时也引入了 Data Warehouse 支持事务和数据质量的特点。LakeHouse 定义了一种叫我们称之为 Table Format 的存储标准。Table format 有四个典型的特征:- 支持 ACID 和历史... 都是从数据仓库而不是 Hadoop 体系的产品中长出来的:Codegen 是 Hyper 提出的技术,而向量化则是 MonetDB 提出的,所以计算引擎的精细化也是沿着数仓开辟的路子在走。Spark 等 Hadoop 体系均走了 Codegen 的道路,因为...
干货|解析云原生数仓ByteHouse如何构建高性能向量检索技术
[picture.image](https://p3-volc-community-sign.byteimg.com/tos-cn-i-tlddhu82om/ea4a41d078194164a4e6a93665cc4c8c~tplv-tlddhu82om-image.image?=&rk3s=8031ce6d&x-expires=1716135641&x-signature=sCHdiDW1i... 用来提升非结构化数据的分析和检索能力。ByteHouse是火山引擎推出的云原生数据仓库,近期推出高性能向量检索能力, **本篇将结合ByteHouse团队对向量数据库行业和技术的前沿观察,详细解读OLAP引擎如何建设高性能的向...
字节跳动开源其云原生数据仓库 ByConity
项目简介-----ByConity 是字节跳动开源的云原生数据仓库,它采用计算-存储分离的架构,支持多个关键功能特性,如计算存储分离、弹性扩缩容、租户资源隔离和数据读写的强一致性等。通过利用主流的... =&rk3s=8031ce6d&x-expires=1716135659&x-signature=40dWQ0VMHNIYwoX%2BSdBVno%2FTewo%3D) *图4 计算组和多租户*#### 虚拟文件系统虚拟文件系统模块作为数据读写的中间层,ByConity 做了比较好...
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0(上)
数据仓库产品,在开源 ClickHouse 引擎之上做了技术架构重构,实现了云原生环境的部署和运维管理、存储计算分离、多租户管理等功能。在可扩展性、稳定性、可运维性、性能以及资源利用率方面都有巨大的提升。 截至 2022 年 2 月,ByteHouse 在字节跳动内部部署规模超过 1 万 8000 台,单集群超过 2400 台。经过内部数百个应用场景和数万用户锤炼,并在多个外部企业客户中得到推广应用。## 产品特性**ByteHouse 以提供高性能、...
