dw数据仓库的设计
 社区干货
社区干货
数仓黄金价值圈: 为什么、是什么、怎么做|社区征文
今天给大家一起分享下有着悠久历史的数据仓库的一些思考由三部分组成为什么,搭建数据仓库是什么,数据仓库定义怎么做,如何搭建数仓# 一:为什么,搭建数据仓库最终目标:**数据驱动资源优化配置,即科学、高效... 同时又承担基础数据记录历史变化,之所以保留原始数据和线上原始数据保持一致,方便后期数据核对需要。- CDM:通用数据模型,又称为数据中间层(Common Data Model),包含DWD、DWS、DIM层。- DWD:数据仓库明细层数...
浅谈数仓建设及数据治理 | 社区征文
**数据应用**。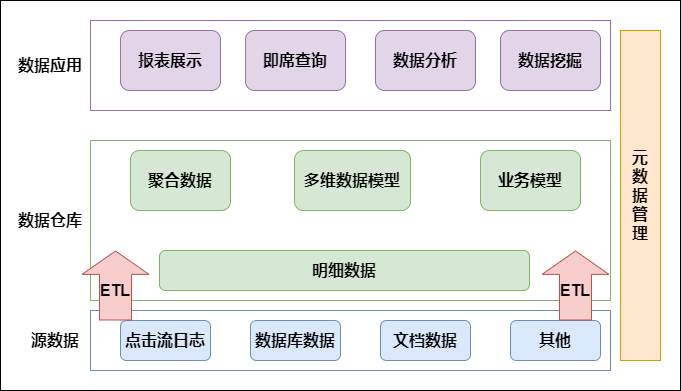数据仓库的数据来源于不同的源数据,并提供多样的数据应用,数据自下而上流入数据仓库后向上层开放应用,而数据仓库只是中间集成化数据管理的一个平台。**源数据**:此层数据无任何更改,直接沿用外围系统数据结构和数据,不对外开放;为临时存储层,是接口数据的临时存储区域,为后一步的数据处理做准备。**数据仓库**:也称为细节层,DW层的数据...
干货 | 这样做,能快速构建企业级数据湖仓
* 使用体验离预期有差距:由于 Table Format 设计上的原因,流式写入的效率不高,写入越频繁小文件问题就越严重;* 有一定维护成本:使用 Table Format 的用户需要自己维护,会给用户造成一定的负担;* 与现有生态之间存... Codegen 和向量化都是从数据仓库,而不是 Hadoop 体系的产品中衍生出来。Codegen 是 Hyper 提出的技术,而向量化则是 MonetDB 提出的,所以计算引擎的精细化也是沿着数仓开辟的路子在走。Spark 等 Hadoop 体系均走...
浅谈大数据建模的主要技术:维度建模 | 社区征文
怎么组织才能使得数据的使用最为方便和便捷?- 怎么组织才能使得数据仓库具有良好的可扩展性和可维护性?> **Ralph Kimball 维度建模理论很好地回答和解决了上述问题。**维度建模理论和技术也是目前在数据仓库领域中使用最为广泛的、也最得到认可和接纳的一项技术。今天我们就来深入探讨 Ralph Kimball 维度建模的各项技术,涵盖其基本理论、一般过程、维度表设计和事实表设计等各个方面,也为我们后面讲Hadoop 数据仓库实战打...
 特惠活动
特惠活动
 dw数据仓库的设计-优选内容
dw数据仓库的设计-优选内容
 dw数据仓库的设计-相关内容
dw数据仓库的设计-相关内容
干货|ByteHouse:百万级TPS!看字节跳动如何基于ClickHouse落地高性能实时数仓
数据仓库,为用户带来极速分析体验,能够支撑实时数据分析和海量数据离线分析。便捷的弹性扩缩容能力,极致分析性能和丰富的企业级特性,助力客户数字化转型。> > > > > **全篇将从两个版块讲解 ByteHouse 的技术... 各种各样的数据源都可以通过Kafka或者Flink写入到ByteHouse里面,然后来对接上层的应用。按照数仓分层角度,Kafka、Flink可以理解为ODS层,那ByteHouse就可以理解为DWD和DWS层。如果说有聚合或者预计算的场景,也...
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0(中)
云原生数据仓库 ByteHouse 总体架构图如上图所示,设计目标是实现高扩展性、高性能、高可靠性、高易用性。从下往上,总体上分服务层、计算层和存储层。## 服务层服务层包括了所有与用户交互的内容,包括用户管理、... =&rk3s=8031ce6d&x-expires=1716222101&x-signature=B2gh7DFdWLT0qvkAv9lDRKQfod0%3D) Write Query 模块交互图 **Query 的执行过程:**1. 用户提交 Write Query 到服务节点1. 服务节点从元数据服务获取需要的...
观点|SparkSQL在企业级数仓建设的优势
数据仓库的事实标准和数据处理工具,Hive已经不单单是一个技术组件,而是一种设计理念。Hive有JDBC客户端,支持标准JDBC接口访问的HiveServer2服务器,管理元数据服务的Hive Metastore,以及任务以MapReduce分布式... 数仓在构建的时候通常需要ETL处理和分层设计,基于业务系统采集的结构化和非结构化数据进行各种ETL处理成为DWD层,再基于DWD层设计上层的数据模型层,形成DM,中间会有DWB/DWS作为部分中间过程数据。从技术选型来...
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0(上)
> 更多技术交流、求职机会,欢迎关注**字节跳动数据平台微信公众号,回复【1】进入官方交流群** **近日,《火山引擎云原生数据仓库 ByteHouse 技术白皮书》正式发布。** 白皮书简述了 ByteHouse 基于 ClickHouse 引擎的发展历程,首次详细展现 ByteHouse 的整体架构设计及自研核心技术,为云原生数据仓库发展,及企业数字化转型实战运用提供最新的参考和启迪。 以下为 ByteHouse 技术白皮书前两个版块摘录。# 1.ByteHous...
ByteHouse:基于ClickHouse的实时数仓能力升级解读
ByteHouse是火山引擎上的一款云原生数据仓库,为用户带来极速分析体验,能够支撑实时数据分析和海量数据离线分析。便捷的弹性扩缩容能力,极致分析性能和丰富的企业级特性,助力客户数字化转型。全篇将从两个版块讲解... 各种各样的数据源都可以通过Kafka或者Flink写入到ByteHouse里面,然后来对接上层的应用。按照数仓分层角度,Kafka、Flink可以理解为ODS层,那ByteHouse就可以理解为DWD和DWS层。如果说有聚合或者预计算的场景,也可以...
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0 (Ⅳ)
> 更多技术交流、求职机会,欢迎关注**字节跳动数据平台微信公众号,回复【1】进入官方交流群**近日,《火山引擎云原生数据仓库 ByteHouse 技术白皮书》正式发布。白皮书简述了 ByteHouse 基于 ClickHouse 引擎的发展历程,首次详细展现 ByteHouse 的整体架构设计及自研核心技术,为云原生数据仓库发展,及企业数字化转型实战运用提供最新的参考和启迪。以下为 ByteHouse 技术白皮书【数据导入导出】版块摘录。技术白皮书(Ⅰ)(Ⅱ...
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0 (Ⅵ)
> 更多技术交流、求职机会,欢迎关注**字节跳动数据平台微信公众号,回复【1】进入官方交流群** 近日,《火山引擎云原生数据仓库 ByteHouse 技术白皮书》正式发布。白皮书简述了 ByteHouse 基于 ClickHouse 引擎的发展历程,首次详细展现 ByteHouse 的整体架构设计及自研核心技术,为云原生数据仓库发展,及企业数字化转型实战运用提供最新的参考和启迪。 **以下为 ByteHouse 技术白皮书【核心技术解析——元数据】版块摘录...
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0 (Ⅲ)
> 更多技术交流、求职机会,欢迎关注**字节跳动数据平台微信公众号,回复【1】进入官方交流群**近日,《火山引擎云原生数据仓库 ByteHouse 技术白皮书》正式发布。白皮书简述了 ByteHouse 基于 ClickHouse 引擎的发展历程,首次详细展现 ByteHouse 的整体架构设计及自研核心技术,为云原生数据仓库发展,及企业数字化转型实战运用提供最新的参考和启迪。以下为 ByteHouse 技术白皮书**作业执行流程版块**摘录。技术白皮书(上...
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0 (Ⅴ)
> 更多技术交流、求职机会,欢迎关注**字节跳动数据平台微信公众号,回复【1】进入官方交流群** 近日,《火山引擎云原生数据仓库 ByteHouse 技术白皮书》正式发布。白皮书简述了 ByteHouse 基于 ClickHouse 引擎的发展历程,首次详细展现 ByteHouse 的整体架构设计及自研核心技术,为云原生数据仓库发展,及企业数字化转型实战运用提供最新的参考和启迪。 **以下为 ByteHouse 技术白皮书【多租户管理、运维监控管理】版块摘...
