一般用途事务处理数据仓库
 社区干货
社区干货
数仓黄金价值圈: 为什么、是什么、怎么做|社区征文
操作型数据库的数据组织面向事务处理任务,各个业务系统之间各自分离,而数据仓库中的数据是按照一定的主题域进行组织的。 2、集成的【大一统、全链路】 数据仓库中的数据是在对原有分散的数据库[数据抽取](h... 观点来考察事物把整体论映射到数据仓库,包含**数据汇聚与全局数据**DWS:数据仓库汇总层数据(Data Warehouse Summary)DIM:数据仓库为表层(Dimension)DWS的建设思路是:**确定分析实体**【用户、用户&产品、...
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0(上)
> 更多技术交流、求职机会,欢迎关注**字节跳动数据平台微信公众号,回复【1】进入官方交流群** **近日,《火山引擎云原生数据仓库 ByteHouse 技术白皮书》正式发布。** 白皮书简述了 ByteHouse 基于 ClickHous... 同时保留了 MPP 并行处理能力。- 数据一致性与事务支持。- 计算资源隔离,读写分离:通过计算组(VW)概念,对宿主机硬件资源进行灵活切割分配,按需扩缩容。资源有效隔离,读写分开资源管理,任务之间互不影响,杜绝...
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0(中)
云原生数据仓库 ByteHouse 总体架构图如上图所示,设计目标是实现高扩展性、高性能、高可靠性、高易用性。从下往上,总体上分服务层、计算层和存储层。## 服务层服务层包括了所有与用户交互的内容,包括用户管理、身份验证、查询优化器,事务管理、安全管理、元数据管理,以及运维监控、数据查询等可视化操作功能。 **服务层主要包括如下组件:**- **资源管理器**资源管理器(Resource Manager)负责对计算资源进行统一的...
ByConity 技术详解之 ELT
谈到数据仓库, 一定离不开使用Extract-Transform-Load (ETL)或 Extract-Load-Transform (ELT)。 将来源不同、格式各异的数据提取到数据仓库中,并进行处理加工。传统的数据转换过程一般采用Extract-Transform-Load (ETL)来将业务数据转换为适合数仓的数据模型,然而,这依赖于独立于数仓外的ETL系统,因而维护成本较高。ByConity 作为云原生数据仓库,从0.2.0版本开始逐步支持 Extract-Load-Transform (ELT),使用户免于维护多套异构...
 特惠活动
特惠活动
 一般用途事务处理数据仓库-优选内容
一般用途事务处理数据仓库-优选内容
 一般用途事务处理数据仓库-相关内容
一般用途事务处理数据仓库-相关内容
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0 (Ⅵ)
> 更多技术交流、求职机会,欢迎关注**字节跳动数据平台微信公众号,回复【1】进入官方交流群** 近日,《火山引擎云原生数据仓库 ByteHouse 技术白皮书》正式发布。白皮书简述了 ByteHouse 基于 ClickHouse 引擎的发展历程,首次详细展现 ByteHouse 的整体架构设计及自研核心技术,为云原生数据仓库发展,及企业数字化转型实战运用提供最新的参考和启迪。 **以下为 ByteHouse 技术白皮书【核心技术解析——元数据】版块摘录...
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0 (Ⅲ)
> 更多技术交流、求职机会,欢迎关注**字节跳动数据平台微信公众号,回复【1】进入官方交流群**近日,《火山引擎云原生数据仓库 ByteHouse 技术白皮书》正式发布。白皮书简述了 ByteHouse 基于 ClickHouse 引擎的发展历程,首次详细展现 ByteHouse 的整体架构设计及自研核心技术,为云原生数据仓库发展,及企业数字化转型实战运用提供最新的参考和启迪。以下为 ByteHouse 技术白皮书**作业执行流程版块**摘录。技术白皮书(上...
字节跳动开源其云原生数据仓库 ByConity
项目简介-----ByConity 是字节跳动开源的云原生数据仓库,它采用计算-存储分离的架构,支持多个关键功能特性,如计算存储分离、弹性扩缩容、租户资源隔离和数据读写的强一致性等。通过利用主流的... 前者支持事务处理,后者则对后来的一些任务进行管理和调度。### 主要组件库#### 元数据管理ByConity 提供了一个高可用和高性能的元数据读写服务--Catalog Server,并且支持了完备的事务语义特性(ACID)。同时...
DataLeap数据仓库流程最佳实践
基于上述表数据,我们的数据分析需求如下:1)“查看最近三天商店销售额情况(未促销)TOP3”2)“查看最近三天消费最多的用户与金额TOP3”3)“获取商店地域分布情况” 经典数据仓库按照大类分为基础数据层、应用数据层。 本样例中,我们的数据仓库建设思路是: ODS(从生产系统采集原始数据,并将原始数据集成冗余宽表) DWD(对ODS冗余表数据进行轻度过滤处理) DWM (基于DWD表与业务需求,轻度聚合最近三天的数据) APP (基于DWD或DWM,...
云原生数据仓库ByteHouse性能白皮书(企业版)|火山引擎
白皮书下载 下载《云原生数据仓库ByteHouse性能白皮书(企业版)》 白皮书简介 在选择OLAP引擎时,性能是一个重要的因素。高性能,意味着:更短响应时间、更快处理能力、更好用户体验...... ByteHouse 是火山引擎自主研发的云原生数据仓库产品,它全面继承了开源 ClickHouse 的高性能和强大的分析能力,并在架构上遵循新一代云原生理念进行全面重构,实现了容器化、存储计算分离、多租户管理和读写分离等功能。在可扩展性、稳定性、可运维...
浅谈大数据建模的主要技术:维度建模 | 社区征文
## 前言我们不管是基于 Hadoop 的数据仓库(如 Hive ),还是基于传统 MPP 架构的数据仓库(如Teradata ),抑或是基于传统 Oracle 、MySQL 、MS SQL Server 关系型数据库的数据仓库,其实都面临如下问题:- 怎么组织数... 例如产品交易事务事实、 ATM交易事务事实。- 周期快照事实表用于记录有规律的、固定时间间隔的业务累计数据,通常粒度比较大,例如账户月平均余额事实表。- 累积快照事实表用于记录具有时间跨度的业务处理过程的整...
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0 (Ⅳ)
> 更多技术交流、求职机会,欢迎关注**字节跳动数据平台微信公众号,回复【1】进入官方交流群**近日,《火山引擎云原生数据仓库 ByteHouse 技术白皮书》正式发布。白皮书简述了 ByteHouse 基于 ClickHouse 引擎的发展历程,首次详细展现 ByteHouse 的整体架构设计及自研核心技术,为云原生数据仓库发展,及企业数字化转型实战运用提供最新的参考和启迪。以下为 ByteHouse 技术白皮书【数据导入导出】版块摘录。技术白皮书(Ⅰ)(Ⅱ...
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0 (Ⅴ)
> 更多技术交流、求职机会,欢迎关注**字节跳动数据平台微信公众号,回复【1】进入官方交流群** 近日,《火山引擎云原生数据仓库 ByteHouse 技术白皮书》正式发布。白皮书简述了 ByteHouse 基于 ClickHouse 引擎的发展历程,首次详细展现 ByteHouse 的整体架构设计及自研核心技术,为云原生数据仓库发展,及企业数字化转型实战运用提供最新的参考和启迪。 **以下为 ByteHouse 技术白皮书【多租户管理、运维监控管理】版块摘...
DataLeap数据仓库流程最佳实践
经典数据仓库按照大类分为基础数据层、应用数据层。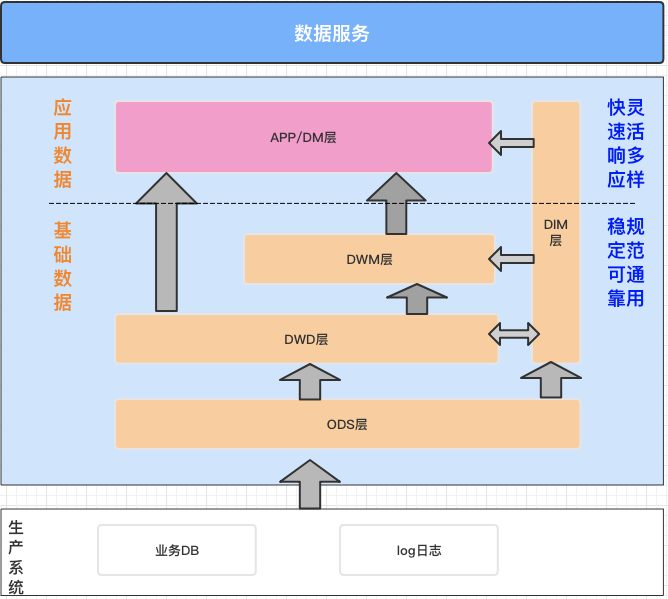本样例中,我们的数据仓库建设思路是:* ODS(从生产系统采集原始数据,并将原始数据集成冗余宽表)* DWD(对ODS冗余表数据进行轻度过滤处理)* DWM (基于DWD表与业务需求,轻度聚合最近三天的数据)* APP (基于DWD或DWM,输出具体报表信息)在“数据地图”中...
