医院数据仓库实例讲解
 社区干货
社区干货
ByConity 技术详解之 ELT
谈到数据仓库, 一定离不开使用Extract-Transform-Load (ETL)或 Extract-Load-Transform (ELT)。 将来源不同、格式各异的数据提取到数据仓库中,并进行处理加工。传统的数据转换过程一般采用Extract-Transform-Load ... server是多实例,每个server实例中都有queue,所持有的是一个局部视角,缺乏全局的资源视角。除此之外,每个queue中的查询状态没有持久化,只是简单的缓存在内存中。后续,我们会增加server之间的协调,在一个全局的视角...
DataLeap数据仓库流程最佳实践
我们的数据仓库建设思路是:* ODS(从生产系统采集原始数据,并将原始数据集成冗余宽表)* DWD(对ODS冗余表数据进行轻度过滤处理)* DWM (基于DWD表与业务需求,轻度聚合最近三天的数据)* APP (基于DWD或DWM,输出具体报表信息)在“数据地图”中创建数据仓库中要使用到的表: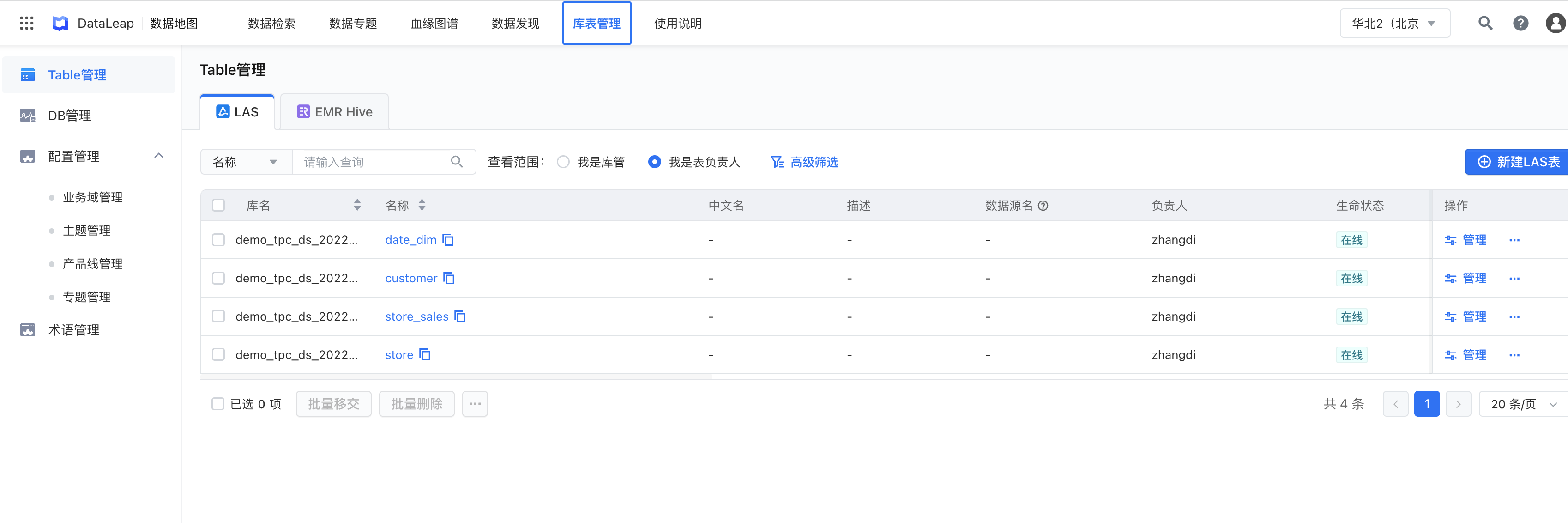本案例中库信息为:demo_tpc_ds_20...
浅谈大数据建模的主要技术:维度建模 | 社区征文
## 前言我们不管是基于 Hadoop 的数据仓库(如 Hive ),还是基于传统 MPP 架构的数据仓库(如Teradata ),抑或是基于传统 Oracle 、MySQL 、MS SQL Server 关系型数据库的数据仓库,其实都面临如下问题:- 怎么组织数... [维度建模事实表示例](https://img-blog.csdnimg.cn/20201103111923706.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0JlaWlzQmVp,size_1,color_FFF...
浅谈数仓建设及数据治理 | 社区征文
## 一、前言在谈数仓之前,先来看下面几个问题:### 1. 数仓为什么要分层?1. 用空间换时间,通过大量的预处理来提升应用系统的用户体验(效率),因此数据仓库会存在大量冗余的数据;不分层的话,如果源业务系统的业... 而企业数据模型也分为两个层次,即主题域模型和逻辑模型。同样,主题域模型可以看成是业务模型的概念模型,而逻辑模型则是域模型在关系型数据库上的实例化。#### 2) 实体建模法实体建模法并不是数据仓库建模中常见...
 特惠活动
特惠活动
 医院数据仓库实例讲解-优选内容
医院数据仓库实例讲解-优选内容
 医院数据仓库实例讲解-相关内容
医院数据仓库实例讲解-相关内容
数仓进阶篇@记一次BigData-OLAP分析引擎演进思考过程 | 社区征文
数据由本系统产生,数据量不是很大,但是数据增删改较多; **2、** 另一种是统计分析类型,数据不由本系统产生,来自医院各生产系统,数据集规模极其庞大,并且数据查询较多。## 思考数据每天在源源不断产生,音视... 兼顾数据仓库,具有实时,批处理,多并发等优点。**Java接入:** ![image.png]...
云原生数据仓库ByteHouse性能白皮书(企业版)|火山引擎
白皮书下载 下载《云原生数据仓库ByteHouse性能白皮书(企业版)》 白皮书简介 在选择OLAP引擎时,性能是一个重要的因素。高性能,意味着:更短响应时间、更快处理能力、更好用户体验...... ByteHouse 是火山引擎自主研发的云原生数据仓库产品,它全面继承了开源 ClickHouse 的高性能和强大的分析能力,并在架构上遵循新一代云原生理念进行全面重构,实现了容器化、存储计算分离、多租户管理和读写分离等功能。在可扩展性、稳定性、可运维...
ByteHouse:基于ClickHouse的实时数仓能力升级解读
数据仓库,为用户带来极速分析体验,能够支撑实时数据分析和海量数据离线分析。便捷的弹性扩缩容能力,极致分析性能和丰富的企业级特性,助力客户数字化转型。全篇将从两个版块讲解ByteHouse的技术业务场景及实践经验... 如果采用数据湖方案,可能需要投入更多的资源。这个时候,可以先选择使用ByteHouse的存储方案来作为实时数仓初步的构建,快速而敏捷的去构建起一套实时数仓的架构。## 案例一
> 更多技术交流、求职机会,欢迎关注**字节跳动数据平台微信公众号,回复【1】进入官方交流群** **近日,《火山引擎云原生数据仓库 ByteHouse 技术白皮书》正式发布。** 白皮书简述了 ByteHouse 基于 ClickHouse 引擎的发展历程,首次详细展现 ByteHouse 的整体架构设计及自研核心技术,为云原生数据仓库发展,及企业数字化转型实战运用提供最新的参考和启迪。 以下为 ByteHouse 技术白皮书前两个版块摘录。# 1.ByteHous...
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0(中)
> 更多技术交流、求职机会,欢迎关注**字节跳动数据平台微信公众号,回复【1】进入官方交流群** 近日,《火山引擎云原生数据仓库 ByteHouse 技术白皮书》正式发布。白皮书简述了 ByteHouse 基于 ClickHouse 引擎的发展历程,首次详细展现 ByteHouse 的整体架构设计及自研核心技术,为云原生数据仓库发展,及企业数字化转型实战运用提供最新的参考和启迪。 **以下为 ByteHouse 技术白皮书整体架构设计版块摘录。** [点...
使用 Hive 访问 CloudFS 中的数据
Hive 是基于 Hadoop 的一个数据仓库工具,用来进行数据提取、转化、加载。本文介绍如何配置 Hive 服务来访问 CloudFS 中的数据。 前提条件在使用 Hive 服务访问大数据文件存储服务 CloudFS 前,确保您已经完成以下准备工作: 开通大数据文件存储服务 CloudFS 并创建文件存储,获取挂载信息。详细操作请参考创建文件存储系统。 开通 E-MapReduce 服务并创建集群。详细操作请参考E-MapReduce 集群创建。 在配置 Hive 服务之前,请确认/u...
干货 | 这样做,能快速构建企业级数据湖仓
案例或者商业公司,比如 Data Bricks、基于 Iceberg 的 Tabluar以及基于 Hudi 的 OneHouse 公司。通过这些公司的商业产品,底层组件、运维和优化都交由商业产品解决,有效减轻负担。而且商业公司还有能力提供上层的... Codegen 和向量化都是从数据仓库,而不是 Hadoop 体系的产品中衍生出来。Codegen 是 Hyper 提出的技术,而向量化则是 MonetDB 提出的,所以计算引擎的精细化也是沿着数仓开辟的路子在走。Spark 等 Hadoop 体系均走...
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0 (Ⅳ)
> 更多技术交流、求职机会,欢迎关注**字节跳动数据平台微信公众号,回复【1】进入官方交流群**近日,《火山引擎云原生数据仓库 ByteHouse 技术白皮书》正式发布。白皮书简述了 ByteHouse 基于 ClickHouse 引擎的发展历程,首次详细展现 ByteHouse 的整体架构设计及自研核心技术,为云原生数据仓库发展,及企业数字化转型实战运用提供最新的参考和启迪。以下为 ByteHouse 技术白皮书【数据导入导出】版块摘录。技术白皮书(Ⅰ)(Ⅱ...
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0 (Ⅵ)
> 更多技术交流、求职机会,欢迎关注**字节跳动数据平台微信公众号,回复【1】进入官方交流群** 近日,《火山引擎云原生数据仓库 ByteHouse 技术白皮书》正式发布。白皮书简述了 ByteHouse 基于 ClickHouse 引擎的发展历程,首次详细展现 ByteHouse 的整体架构设计及自研核心技术,为云原生数据仓库发展,及企业数字化转型实战运用提供最新的参考和启迪。 **以下为 ByteHouse 技术白皮书【核心技术解析——元数据】版块摘录...
