创建数据仓库的例子
 社区干货
社区干货
DataLeap数据仓库流程最佳实践
完成数据仓库的构建。# 关于实验* 预计部署时间:50分钟* 级别:初级* 相关产品:大数据开发套件、湖仓一体分析服务LAS* 受众: 通用## 环境说明1. 已购买DataLeap产品2. 已创建湖仓一体LAS队列3. 子账户... ## **步骤5:** **数仓任务构建**在任务开发中,新建“数据开发”任务: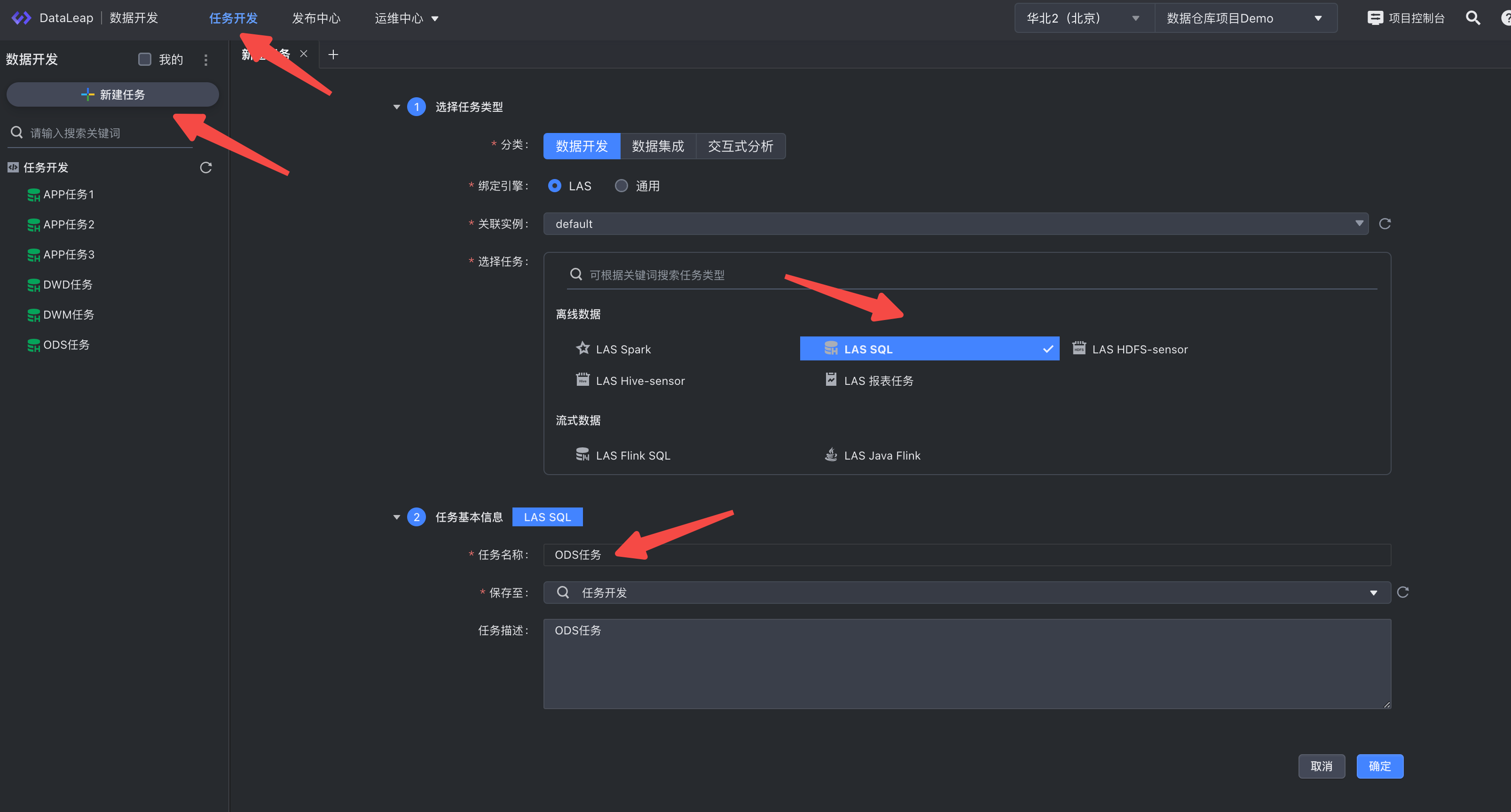,还是基于传统 MPP 架构的数据仓库(如Teradata ),抑或是基于传统 Oracle 、MySQL 、MS SQL Server 关系型数据库的数据仓库,其实都面临如下问题:- 怎么组织数... 可以把各个地方仓库的库存加起来,或者把一个仓库不同的商品加起来,但是很明显不能把一个仓库同一商品在不同时期的库存加起来。银行的账户余额也是半可加事实的例子,可以把不同分行的账户余额加起来或者不同账户人...
干货 | 这样做,能快速构建企业级数据湖仓
主要介绍了数据湖仓开源趋势、火山引擎 EMR 的架构及特点,以及如何基于火山引擎 EMR 构建企业级数据湖仓。> > > >  特惠活动
特惠活动
 创建数据仓库的例子-优选内容
创建数据仓库的例子-优选内容
 创建数据仓库的例子-相关内容
创建数据仓库的例子-相关内容
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0 (Ⅳ)
> 更多技术交流、求职机会,欢迎关注**字节跳动数据平台微信公众号,回复【1】进入官方交流群**近日,《火山引擎云原生数据仓库 ByteHouse 技术白皮书》正式发布。白皮书简述了 ByteHouse 基于 ClickHouse 引擎的发展历程,首次详细展现 ByteHouse 的整体架构设计及自研核心技术,为云原生数据仓库发展,及企业数字化转型实战运用提供最新的参考和启迪。以下为 ByteHouse 技术白皮书【数据导入导出】版块摘录。技术白皮书(Ⅰ)(Ⅱ...
浅谈数仓建设及数据治理 | 社区征文
## 一、前言在谈数仓之前,先来看下面几个问题:### 1. 数仓为什么要分层?1. 用空间换时间,通过大量的预处理来提升应用系统的用户体验(效率),因此数据仓库会存在大量冗余的数据;不分层的话,如果源业务系统的业... 准确的数据支撑,并能够按照已有的模型为新业务发展提供方向,也就是数据驱动和赋能。### 3. 如何搭建一个好的数仓?1. **稳定**:数据产出稳定且有保障。2. **可信**:数据干净、数据质量高。3. **丰富**:数据...
基于火山引擎 EMR 构建企业级数据湖仓
主要介绍了数据湖仓开源趋势、火山引擎 EMR 的架构及特点,以及如何基于火山引擎 EMR 构建企业级数据湖仓。作者:辛现银,火山引擎开源大数据平台 E-MapReduce 技术架构师 数据湖仓开源趋势... 都是从数据仓库而不是 Hadoop 体系的产品中长出来的:Codegen 是 Hyper 提出的技术,而向量化则是 MonetDB 提出的,所以计算引擎的精细化也是沿着数仓开辟的路子在走。Spark 等 Hadoop 体系均走了 Codegen 的道路,因为...
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0(上)
> 更多技术交流、求职机会,欢迎关注**字节跳动数据平台微信公众号,回复【1】进入官方交流群** **近日,《火山引擎云原生数据仓库 ByteHouse 技术白皮书》正式发布。** 白皮书简述了 ByteHouse 基于 ClickHous... UDF:支持 Python UDF/UDAF 创建与管理,补足函数的可扩展性。(Java UDF/UDAF 已在开发中)- 自研优化器:自研 Cost-Based Optimizer,优化多表 JOIN 等复杂查询性能,性能提升若干倍。 **产品能力上,在引擎...
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0(中)
> 更多技术交流、求职机会,欢迎关注**字节跳动数据平台微信公众号,回复【1】进入官方交流群** 近日,《火山引擎云原生数据仓库 ByteHouse 技术白皮书》正式发布。白皮书简述了 ByteHouse 基于 ClickHouse 引擎... 生成逻辑执行计划,优化执行计划,调度和执行 query,并将最终结果返回给用户。服务节点是无状态的,意味着用户可以接入任意一个服务节点(当然如果有需要,也可以隔离开),并且可以水平扩展,意味着平台具备支持高并发查...
基于火山引擎 EMR 构建企业级数据湖仓
主要为大家介绍了数据湖仓开源趋势、火山引擎 EMR 的架构及特点,以及如何基于火山引擎 EMR 构建企业级数据湖仓。## 数据湖仓开源趋势### 趋势一:数据架构向 LakeHouse 方向发展什么是 LakeHouse? LakeHouse ... 都是从数据仓库而不是 Hadoop 体系的产品中长出来的:Codegen 是 Hyper 提出的技术,而向量化则是 MonetDB 提出的,所以计算引擎的精细化也是沿着数仓开辟的路子在走。Spark 等 Hadoop 体系均走了 Codegen 的道路,因为...
ByConity 替换 ClickHouse 构建 OLAP 数据平台,资源成本大幅降低
ByConity 是字节跳动开源的云原生数据仓库,在满足数仓用户对资源弹性扩缩容,读写分离,资源隔离,数据强一致性等多种需求的同时,提供优异的查询,写入性能。文章来源|ByConity 开源社区GitHub |https://github.com/ByConity/ByConity作者|程伟,MetaAPP 大数据研发工程师 MetaApp 是国内领先的游戏开发与运营商,专注移动端信息高效分发,致力于构建面向全年龄段的虚拟世界。截至 2023 年,MetaAp...
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0 (Ⅴ)
> 更多技术交流、求职机会,欢迎关注**字节跳动数据平台微信公众号,回复【1】进入官方交流群** 近日,《火山引擎云原生数据仓库 ByteHouse 技术白皮书》正式发布。白皮书简述了 ByteHouse 基于 ClickHouse 引擎的发展历程,首次详细展现 ByteHouse 的整体架构设计及自研核心技术,为云原生数据仓库发展,及企业数字化转型实战运用提供最新的参考和启迪。 **以下为 ByteHouse 技术白皮书【多租户管理、运维监控管理】版块摘...
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0 (Ⅲ)
> 更多技术交流、求职机会,欢迎关注**字节跳动数据平台微信公众号,回复【1】进入官方交流群**近日,《火山引擎云原生数据仓库 ByteHouse 技术白皮书》正式发布。白皮书简述了 ByteHouse 基于 ClickHouse 引擎的发展历程,首次详细展现 ByteHouse 的整体架构设计及自研核心技术,为云原生数据仓库发展,及企业数字化转型实战运用提供最新的参考和启迪。以下为 ByteHouse 技术白皮书**作业执行流程版块**摘录。技术白皮书(上...
