数据仓库集成特性叙述
 社区干货
社区干货
数仓黄金价值圈: 为什么、是什么、怎么做|社区征文
即让数据高效复用,减少重复开发2、增效是技术的价值,即降低数据使用门槛,让数据服务无处不在3、清晰明了是数据GPS,即清晰的管理、追踪、定位数据把为什么想清楚了,接下来就是探讨数据仓库是什么,是否能满足以上的诉求# 二、是什么,数据仓库定义数据仓库广泛定义:数据仓库是一个面向主题的(Subject Oriented)、集成的(Integrate)、相对稳定的(Non-Volatile)、反映历史变化(Time Variant)的数据集合,用于支持管理决策。...
浅谈数仓建设及数据治理 | 社区征文
当数据发生错误的时候,往往我们只需要局部调整某个步骤即可。数据仓库之父 Bill Inmon对数据仓库做了定义——面向主题的、集成的、相对稳定的、反映历史变化的数据集合,用于支持管理决策。从定义上来看,数据仓库... 结合指标的特性以及词根管理规范,将指标进行结构化处理。1. 基础指标词根,即所有指标必须包含以下基础词根: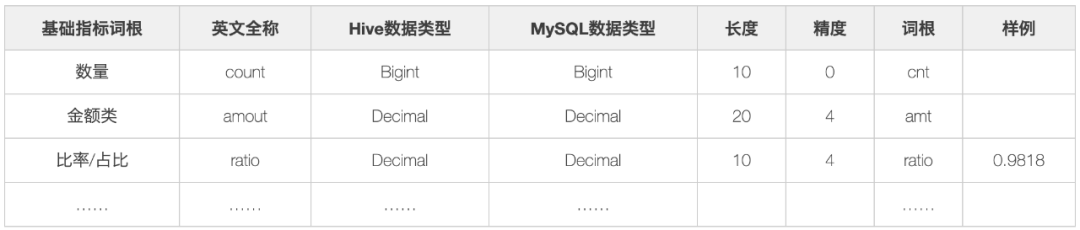2. 业务修饰词,用于描述业务场景的词汇,例如...
字节跳动开源其云原生数据仓库 ByConity
项目简介-----ByConity 是字节跳动开源的云原生数据仓库,它采用计算-存储分离的架构,支持多个关键功能特性,如计算存储分离、弹性扩缩容、租户资源隔离和数据读写的强一致性等。通过利用主流的... 并为分布式计划集成 Property Enforcement。#### 查询调度ByConity 目前支持两种查询调度策略:Cache-aware 调度和 Resource-aware 调度。其中:**Cache-aware 调度** 针对计算和存储分离的场景,旨在最大化...
数仓进阶篇@记一次BigData-OLAP分析引擎演进思考过程 | 社区征文
兼顾数据仓库,具有实时,批处理,多并发等优点。**Java接入:**  在阐述Vertica(简称V)、 ClickHouse(简称C)、Greenplum(简称G)这三款MPP之前,我们不妨以北京...
 特惠活动
特惠活动
 数据仓库集成特性叙述-优选内容
数据仓库集成特性叙述-优选内容
 数据仓库集成特性叙述-相关内容
数据仓库集成特性叙述-相关内容
配置 ByteHouse 云数仓版 数据源
ByteHouse 是一款火山引擎云原生数据仓库,为您提供极速分析体验,能够支撑实时数据分析和海量数据离线分析等场景。DataSail 中的 ByteHouse 云数仓版数据源配置,为您提供读取和写入 ByteHouse 的双向通道数据集成能力,实现不同数据源与 ByteHouse 之间进行数据传输。本文为您介绍 DataSail 的 ByteHouse 数据同步的能力支持情况。 1 支持的 ByteHouse 版本支持火山引擎 ByteHouse 云数仓版(ByteHouse_CDW)标品。开通服务详见快速开...
配置 ByteHouse 企业版 数据源
ByteHouse 是一款火山引擎云原生数据仓库,为您提供极速分析体验,能够支撑实时数据分析和海量数据离线分析等场景。ByteHouse(企业版)是基于开源 ClickHouse 的企业级分析型数据库,支持用户交互式分析 PB 级别数据,通过多种自研表引擎,灵活支持各类数据分析和应用。DataSail 中的 ByteHouse 企业版数据源配置,为您提供读取和写入 ByteHouse 的双向通道数据集成能力,实现不同数据源与 ByteHouse 之间进行数据传输。本文为您介绍 Dat...
DataLeap数据仓库流程最佳实践
我们的数据分析需求如下:1)“查看最近三天商店销售额情况(未促销)TOP3”2)“查看最近三天消费最多的用户与金额TOP3”3)“获取商店地域分布情况”经典数据仓库按照大类分为基础数据层、应用数据层。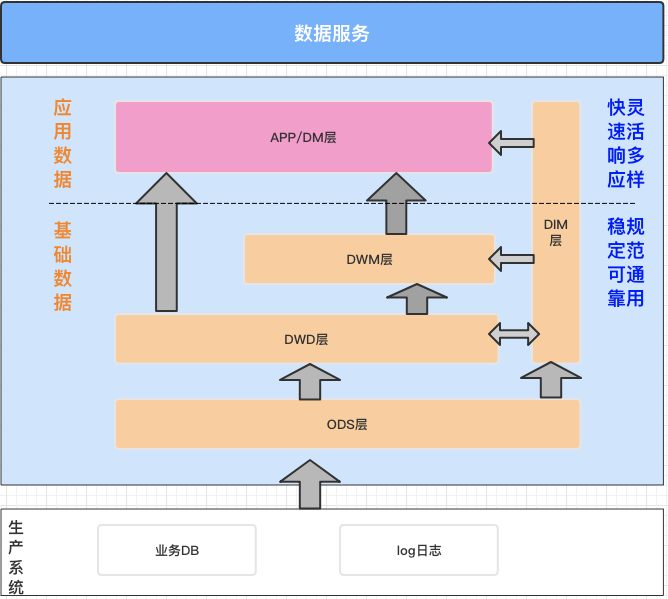本样例中,我们的数据仓库建设思路是:* ODS(从生产系统采集原始数据,并将原始数据集成冗余宽表)* DWD...
基于 ByteHouse 构建实时数仓实践
从而最大效率实现数据价值转化,对实时数仓的建设需求自然而然的诞生了。而建设好实时数仓需要解决如下几个问题: 一、稳定性:实时数仓对数据的实时处理必须是可靠的、稳定的;二、高效数据集成:流式数据的集... 面对业务大数据量的产生,需要高效可靠实时数据的接入能力,为此我们自研了 Kafka 数据源接入表引擎 HaKafka ,该表引擎可高效的将 Kafka 的数据接入 ByteHouse ,具有有如下特性:1. 数据接入高吞吐性,支持了多线消...
干货 | 看 SparkSQL 如何支撑企业级数仓
以及元数据中心,这一系列组合让 Hive 完整的具备了构建一个企业级数据仓库的所有特性,并且 Hive 的 SQL 服务器是目前使用最广泛的标准服务器。虽然 Hive 有非常明显的优点,可以找出完全替代 Hive 的组件寥寥无几... 或者是否可以很好的与其他服务集成,例如数据湖引擎 delta lake,icebeg,hudi 等优秀组件出现,但是 Hive 集成的节奏却非常慢。- 解耦程度:分布式任务必然需要多个组件的协调,例如分布式存储,资源管理,调度等,像 H...
观点|SparkSQL在企业级数仓建设的优势
以及元数据中心,这一系列组合让Hive完整的具备了构建一个企业级数据仓库的所有特性,并且Hive的SQL服务器是目前使用最广泛的标准服务器。虽然Hive有非常明显的优点,可以找出完全替代Hive的组件寥寥无几,但是并... 或者是否可以很好的与其他服务集成,例如数据湖引擎delta lake,icebeg,hudi等优秀组件出现,但是Hive集成的节奏却非常慢。* 解耦程度:分布式任务必然需要多个组件的协调,例如分布式存储,资源管理,调度等,像Hive就...
「火山引擎」数智平台 VeDI 数据中台产品双月刊 VOL.03
一站式数据中台套件,帮助用户快速完成数据集成、开发、运维、治理、资产、安全等全套数据中台建设,提升数据研发效率、降低管理成本。搭配 EMR/LAS 大数据存储计算引擎,加速企业数据中台及湖仓一体平台建设,为企业数字化转型提供数据支撑。**火山引擎云原生数据仓库** **ByteHouse**云原生数据仓库,为用户提供极速分析体验,能够支撑实时数据分析和海量数据离线分析。便捷的弹性扩缩容能力,极致分析性能和丰富的企业级特性,助力...
基于火山引擎 EMR 构建企业级数据湖仓
都是从数据仓库而不是 Hadoop 体系的产品中长出来的:Codegen 是 Hyper 提出的技术,而向量化则是 MonetDB 提出的,所以计算引擎的精细化也是沿着数仓开辟的路子在走。Spark 等 Hadoop 体系均走了 Codegen 的道路,因为 Java 做 Codegen 比做向量化要更容易一些。但是现在人们发现可能向量化是一个更好的选择,向量化可以一次处理一批数据,而不只是一条数据。其好处是可以充分利用 CPU 的一些特性,比如 SIMD,Pipeline 执行等。### *...
干货 | 这样做,能快速构建企业级数据湖仓
Codegen 和向量化都是从数据仓库,而不是 Hadoop 体系的产品中衍生出来。Codegen 是 Hyper 提出的技术,而向量化则是 MonetDB 提出的,所以计算引擎的精细化也是沿着数仓开辟的路子在走。Spark 等 Hadoop 体系均走了 Codegen 的道路,因为 Java 做 Codegen 比做向量化要更容易一些。但现在,向量化是一个更好的选择,因为向量化可以一次处理一批数据,而不只是一条数据。其好处是可以充分利用 CPU 的特性,如 SIMD,Pipeline 执行等...
