存储过程在执行时失败,但构成它的 SQL 语句运行正常。
 社区干货
社区干货
mysql事物存储过程
MySQL 数据库中的事务和存储过程是两个不同的概念,我将会分别解释这两个概念,然后提供一个简单的存储过程示例。1. **事务(Transaction)**:数据库事务是指一个或一组SQL语句的逻辑单元,这个逻辑单元中的操作要么全部执行,要么全部不执行。如果在执行过程中出现错误,那么事务将会回滚(Rollback),即撤销已经执行的操作;如果所有操作都成功执行,那么事务就会被提交(Commit),数据会被永久保存在数据库中。事务的主要特点是可以保证在...
mysql的面向流程编程
它具有高度的可靠性,高性能和扩展性。它的流程控制十分重要,因为MySQL能够将复杂的数据库管理任务自动完成,比如持续更新数据库后台,以及应用程序开发中所需的任何其他任务。MySQL中的流程控制是通过SQL语句进行的... 在如果某条件符合的情况下,可以使用IF ELSE.. THENEND格式来执行某一API函数,从而实现不同的数据库动作,不同的数据处理方式,或者执行某个外部的语句。为了简化复杂的查询或流程控制,MySQL支持存储过程,允许用户存...
2022技术盘点之平台云原生架构演进之道|社区征文
数据库有MongoDB分片集群/MySQL/Redis/ElasticSearch/RabbitMQ进行各类业务数据计算和存储## 三 流量管控... 事后的全过程防护;- 业界主流安全工具平台赋能:如:KubeLinter/Kubescape/Nessus/Sonarqube/AppScan等,严格把控平台从设计、开发、测试、部署、上线、运维等各流程安全,将SecDevOps贯彻在平台生命周期中,确保平台他...
NL2SQL:智能对话在打通人与数据查询壁垒上的探索 | 社区征文
#### 2.1 什么是NL2SQLNL2SQL(Natural Language to SQL), 顾名思义是将自然语言转为SQL语句。它可以充当数据库的智能接口,让不熟悉数据库的用户能够快速地找到自己想要的数据,改善用户与数据库的交互方式。#### 2.2 NL2SQL的目标与定位从技术的角度来看,NL2SQL的本质是将用户的自然语言语句转化为计算机可读懂、可运行、符合计算机规则的语义表示,同时需要计算机理解人类的语言,生成准确表达语句语义的可执行程序式语言。其定...
 特惠活动
特惠活动
 存储过程在执行时失败,但构成它的 SQL 语句运行正常。-优选内容
存储过程在执行时失败,但构成它的 SQL 语句运行正常。-优选内容
 存储过程在执行时失败,但构成它的 SQL 语句运行正常。-相关内容
存储过程在执行时失败,但构成它的 SQL 语句运行正常。-相关内容
NL2SQL:智能对话在打通人与数据查询壁垒上的探索 | 社区征文
#### 2.1 什么是NL2SQLNL2SQL(Natural Language to SQL), 顾名思义是将自然语言转为SQL语句。它可以充当数据库的智能接口,让不熟悉数据库的用户能够快速地找到自己想要的数据,改善用户与数据库的交互方式。#### 2.2 NL2SQL的目标与定位从技术的角度来看,NL2SQL的本质是将用户的自然语言语句转化为计算机可读懂、可运行、符合计算机规则的语义表示,同时需要计算机理解人类的语言,生成准确表达语句语义的可执行程序式语言。其定...
分布式数据库TiDB的设计和架构
需要同时满足低成本、线性扩容及能够处理交易类事务的新型数据库,大数据的存储刚需不可避免。NewSQL的挑战在于,它是基于 Google Spanner/F1 论文,未开源它的代码及技术细节,是基础软件最前沿的领域之一,技术门槛最... ### TiDB ServerSQL 层,对外暴露 MySQL 协议的连接 endpoint,负责接受客户端的连接,执行 SQL 解析和优化,最终生成分布式执行计划。TiDB 层本身是无状态的,实践中可以启动多个 TiDB 实例,通过负载均衡组件(如 LVS...
数据库顶会 VLDB 2023 论文解读:Krypton: 字节跳动实时服务分析 SQL 引擎设计
同时对于研发人员来讲,也不得不学习维护多套系统。为了解决这个问题,我们开启了 Krypton 项目,这是字节跳动基础架构 计算-实时引擎, 创新应用中心, 存储-HDFS & NoSQL 团队共同合作研发的新一代面向复杂业务的实时... 生成分布式执行 Plan 下发给 Data Server,Data Server 负责 Query Plan 的执行。Krypton 的 Query Processor 采用了 MPP 的执行模式。3. 为了提供更好的数据可见性,我们支持了 Dirty Read 的功能,也就是 Data Ser...
Hive SQL 底层执行过程 | 社区征文
第三节剖析 SQL 编译成 MapReduce 的具体实现原理。### 一、HiveHive是什么?Hive 是数据仓库工具,再具体点就是一个 SQL 解析引擎,因为它即不负责存储数据,也不负责计算数据,只负责解析 SQL,记录元数据。Hiv... Hive 的主要组件与 Hadoop 交互的过程: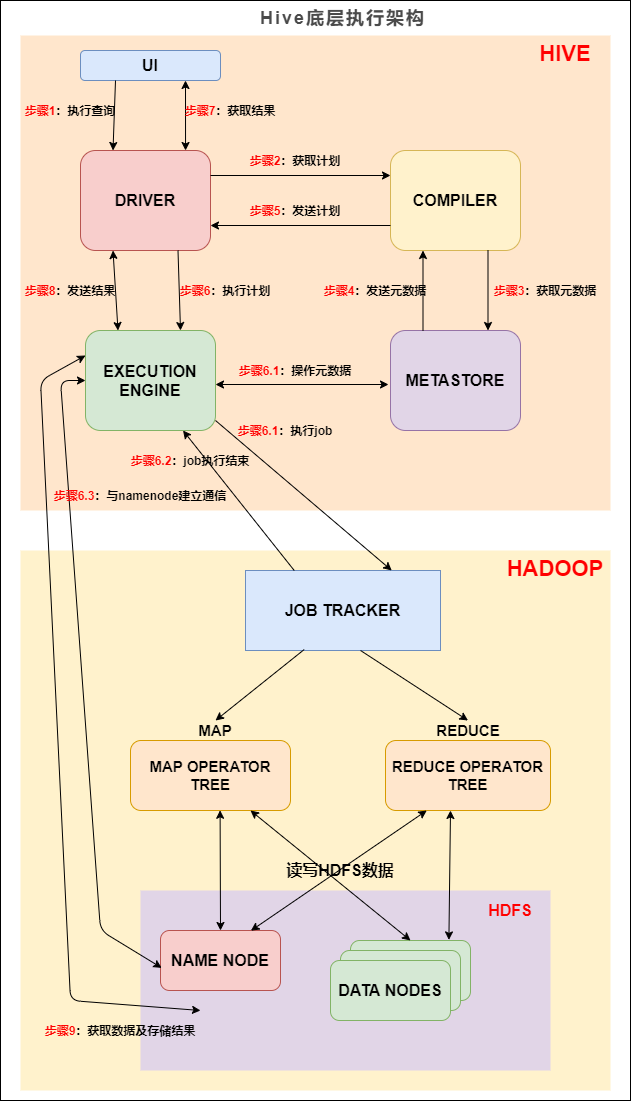在 Hive 这一侧,总共有五个组件:1. UI:用户界面。可看作我们提交SQL语句的命令行界面。...
同步至火山引擎版 MySQL
Binlog 日志至少要保留 24 小时,建议保留 7 天以上的日志,否则 DTS 可能因无法获取日志从而导致任务失败,某些情况下也可能导致数据丢失。 涉及外键依赖的表,需要同时同步,否则将导致数据同步失败。 单任务中表的数量建议不超过 2 万,库的数量不超过 1000 个。当有大量库表需要同步时,建议拆分为多个任务。 目标库限制 数据库版本:当前支持 5.7 和 8.0 的 MySQL 实例。 目标数据库的同步账号权限,会影响视图、存储过程和...
干货 | 看 SparkSQL 如何支撑企业级数仓
以及任务以 MapReduce 分布式任务运行在 YARN 上。标准的 JDBC 接口,标准的 SQL 服务器,分布式任务执行,以及元数据中心,这一系列组合让 Hive 完整的具备了构建一个企业级数据仓库的所有特性,并且 Hive 的 SQL 服... 确保某个节点出现故障或者部分任务失败后可以快速进行恢复。数据保存于 HDFS 等分布式存储系统上,自身不管理数据,具有极高的稳定性和容错处理机制。反过来,因为 Hive,Spark 更善于处理这类批处理的长时任务,因此...
迁移至火山引擎版 MySQL
请参见预检查项(MySQL)。 注意事项由于数据库传输服务 DTS 的延迟时间是根据迁移到目标库最后一条数据的时间戳和当前时间戳对比得出,源库长时间未执行 DML 操作可能会导致延迟信息不准确。如果任务显示的延迟时间... 迁移对象非整库时,不支持 OnlineDDL 操作,且增量迁移不支持自动迁移新增的对象及其相关变更。 迁移对象选择的粒度为库或表。若迁移对象选择的是表,则其他对象例如视图、触发器、函数或存储过程等,不会被迁移至目...
观点|SparkSQL在企业级数仓建设的优势
以及任务以MapReduce分布式任务运行在YARN上。标准的JDBC接口,标准的SQL服务器,分布式任务执行,以及元数据中心,这一系列组合让Hive完整的具备了构建一个企业级数据仓库的所有特性,并且Hive的SQL服务器是目前... 单单是因为暂时找不到一个能支撑企业诉求的替代服务。 EMR 企业级数仓构建需求数仓架构通常是一个企业数据分析的起点,在数仓之下会再有一层数据湖,用来做异构数据的存储以及数据的冷备份...
SQL查询-查询结果可视化及例行
快速入门 2.1 SQL查询结果保存至可视化在 SQL 执行完毕后,点击页面右下角的新建图表按钮,稍等一会儿后,会自动跳转至可视化查询页面,您可在此页面使用可视化查询来查询数据。 2.2 在可视化查询页面保存图表注意: 保存至可视化查询时相当于在 SQL 查询的项目内生成了一个临时数据集,可视化查询页面的查询也是基于这个数据集进行查询。由于该项目的临时数据集仅用于 SQL 查询结果的临时存储,定期会删除清理。若您保存图表,则该临时...
